Artificial I Basics¶
A machine learning model is a program that can find patterns or make decisions from a previously unseen dataset.
For example, in natural language processing, machine learning models can parse and correctly recognize the intent behind previously unheard sentences or combinations of words.
In image recognition, a machine learning model can be taught to recognize objects - such as cars or dogs.
Info
A machine learning algorithm is a mathematical method to find patterns in a set of data. Machine Learning algorithms are often drawn from statistics, calculus, and linear algebra.
Model Training¶
The process of running a machine learning algorithm on a dataset (called training data) and optimizing the algorithm to find certain patterns or outputs is called model training. The resulting function with rules and data structures is called the trained machine learning model.
Ml Types¶
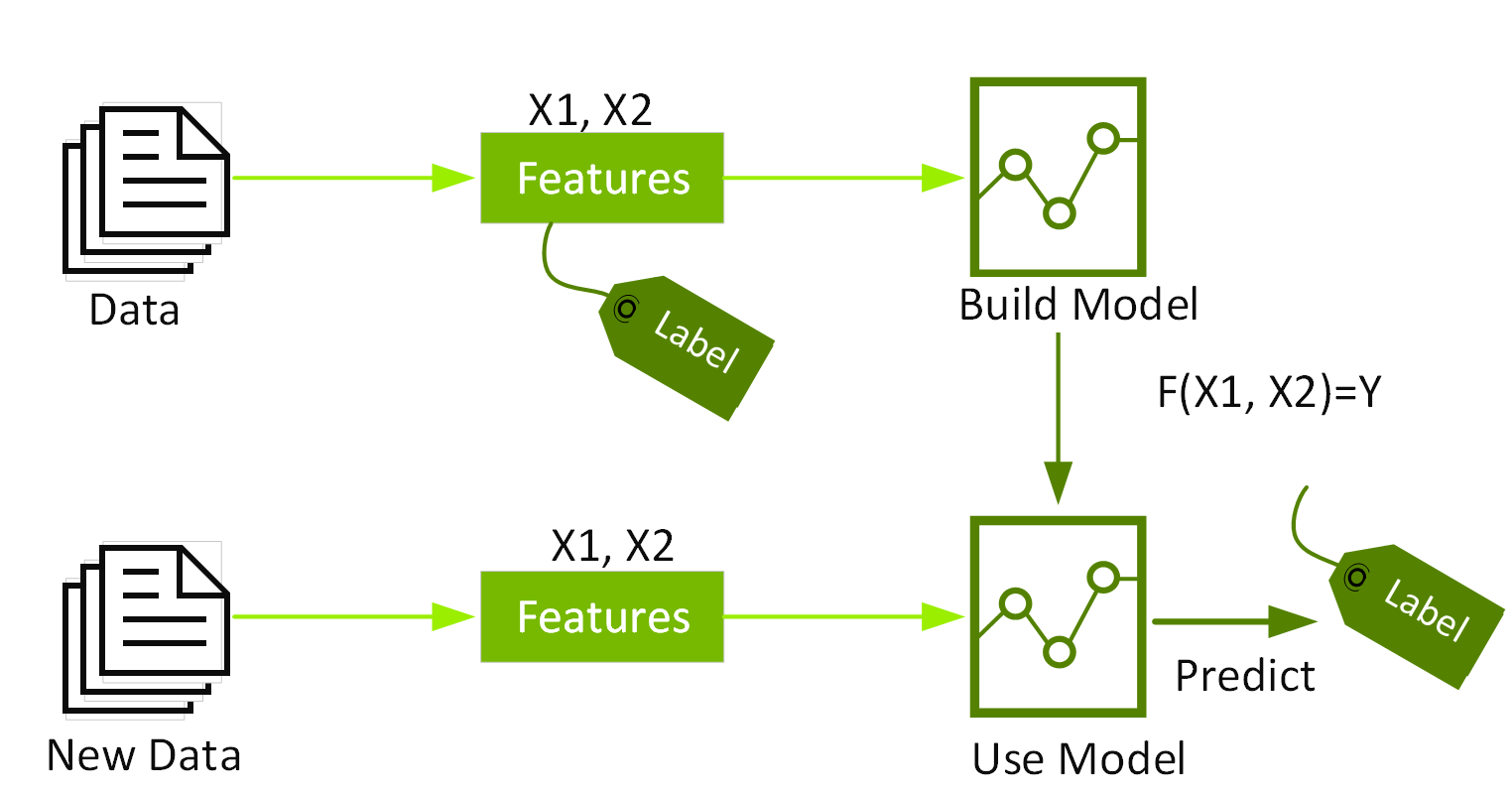
Supervised¶
In supervised machine learning, the algorithm is provided an input dataset, and is rewarded or optimized to meet a set of specific outputs.
Logistic Regression: Logistic Regression is used to determine if an input belongs to a certain group or notSVM: SVM, or Support Vector Machines create coordinates for each object in an n-dimensional space and uses a hyperplane to group objects by common featuresNaive Bayes: Naive Bayes is an algorithm that assumes independence among variables and uses probability to classify objects based on featuresDecision Trees: Decision trees are also classifiers that are used to determine what category an input falls into by traversing the leaf's and nodes of a treeLinear Regression: Linear regression is used to identify relationships between the variable of interest and the inputs, and predict its values based on the values of the input variables.kNN: The k Nearest Neighbors technique involves grouping the closest objects in a dataset and finding the most frequent or average characteristics among the objects.Random Forest: Random forest is a collection of many decision trees from random subsets of the data, resulting in a combination of trees that may be more accurate in prediction than a single decision tree.Boosting algorithms: Boosting algorithms, such as Gradient Boosting Machine, XGBoost, and LightGBM, use ensemble learning. They combine the predictions from multiple algorithms (such as decision trees) while taking into account the error from the previous algorithm.
Unsupervised¶
In unsupervised machine learning, the algorithm is provided an input dataset, but not rewarded or optimized to specific outputs, and instead trained to group objects by common characteristics.
For example, recommendation engines on online stores rely on unsupervised machine learning, specifically a technique called clustering.
K-Means: The K-Means algorithm finds similarities between objects and groups them into K different clusters.Hierarchical Clustering: Hierarchical clustering builds a tree of nested clusters without having to specify the number of clusters.
Reinforcement Learning¶
In reinforcement learning, the algorithm is made to train itself using many trial and error experiments. Reinforcement learning happens when the algorithm interacts continually with the environment, rather than relying on training data.
One of the most popular examples of reinforcement learning is autonomous driving.
Model techniques¶
Regression¶
Regression in data science and machine learning is a statistical method that enables predicting outcomes based on a set of input variables. The outcome is often a variable that depends on a combination of the input variables.

Linear, polynomial, ridge, lasso, quantile, and Bayesian regression
Classification¶
Binary and multi-label classification
Decision Trees¶
A Decision Tree is a predictive approach in ML to determine what class an object belongs to. As the name suggests, a decision tree is a tree-like flow chart where the class of an object is determined step-by-step using certain known conditions.

Random Forests¶
XGBoost¶
XGBoost, which stands for Extreme Gradient Boosting, is a scalable, distributed gradient-boosted decision tree (GBDT) machine learning library. It provides parallel tree boosting and is the leading machine learning library for regression, classification, and ranking problems.
A Gradient Boosting Decision Trees (GBDT) is a decision tree ensemble learning algorithm similar to random forest, for classification and regression. Ensemble learning algorithms combine multiple machine learning algorithms to obtain a better model.
Deep Learning¶
Deep learning models are a class of ML models that imitate the way humans process information. The model consists of several layers of processing (hence the term 'deep') to extract high-level features from the data provided. Each processing layer passes on a more abstract representation of the data to the next layer, with the final layer providing a more human-like insight.

Unlike traditional ML models which require data to be labeled, deep learning models can ingest large amounts of unstructured data.
Other concepts¶
Gradient Boosting¶
The term gradient boosting comes from the idea of boosting or improving a single weak model by combining it with a number of other weak models in order to generate a collectively strong model. Gradient boosting is an extension of boosting where the process of additively generating weak models is formalised as a gradient descent algorithm over an objective function.
Gradient Descent¶
Gradient descent is an optimization algorithm which is commonly-used to train machine learning models and neural networks.
Until the function is close to or equal to zero, the model will continue to adjust its parameters to yield the smallest possible error.
TLDR
Similar to finding the line of best fit in linear regression, the goal of gradient descent is to minimize the cost function, or the error between predicted and actual y. In order to do this, it requires two data points—a direction and a learning rate. These factors determine the partial derivative calculations of future iterations, allowing it to gradually arrive at the local or global minimum (i.e. point of convergence).
Cost/Loss Function¶
The cost (or loss) function measures the difference, or error, between actual y and predicted y at its current position. This improves the machine learning model's efficacy by providing feedback to the model so that it can adjust the parameters to minimize the error and find the local or global minimum.
It continuously iterates, moving along the direction of steepest descent (or the negative gradient) until the cost function is close to or at zero. At this point, the model will stop learning. Additionally, while the terms, cost function and loss function, are considered synonymous, there is a slight difference between them. It’s worth noting that a loss function refers to the error of one training example, while a cost function calculates the average error across an entire training set.
Learning rate¶
Learning rate (also referred to as step size or the alpha) is the size of the steps that are taken to reach the minimum. This is typically a small value, and it is evaluated and updated based on the behavior of the cost function. High learning rates result in larger steps but risks overshooting the minimum. Conversely, a low learning rate has small step sizes. While it has the advantage of more precision, the number of iterations compromises overall efficiency as this takes more time and computations to reach the minimum.
Performance Metrics¶
Classification: Accuracy, Recall, Precision, FPR, FNR, F1, Sensitivity, SpecificityRegression: MAPE, MAE, RMSE, MSE, R-Squared, Mean ErrorRanking: NDCG@k, AUC@kRanking Labels: MAP@k, MRRAUC / LogLoss: AUC, PR-AUC, Log LossComputer Vision / Object Detection: Accuracy (MAP & IoU coming soon)