EC2 ¶
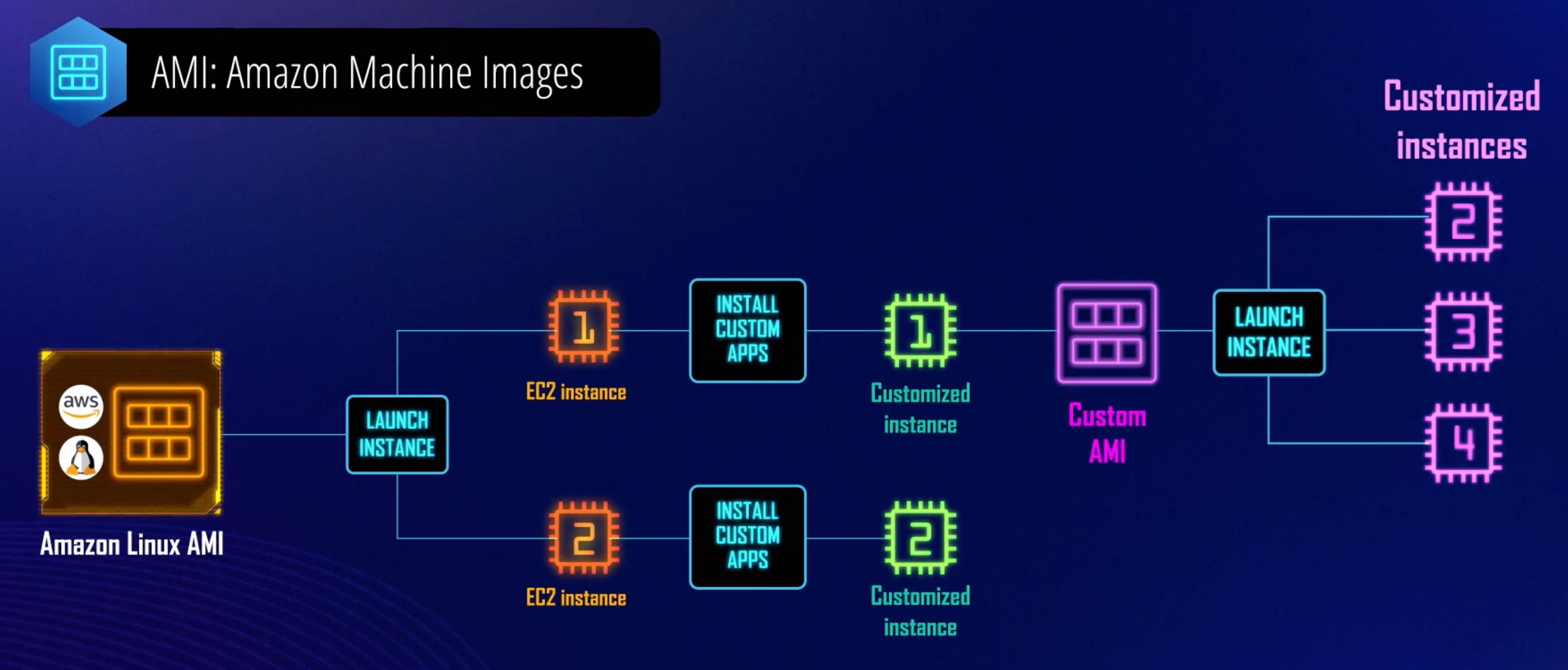
AMI¶
Instance Types for EC2¶
On Demand 📈¶
On-Demand Instances are ideal for short-term, irregular workloads that cannot be interrupted. No upfront costs or minimum contracts apply. The instances run continuously until you stop them, and you pay for only the compute time you use.
Reserved Instances 🔖¶
Reserved Instances are a billing discount applied to the use of On-Demand Instances in your account. There are two available types of Reserved Instances:
- Standard Reserved Instances
- Convertible Reserved Instances
Savings Plan 💰¶
EC2 Instance Savings Plans reduce your EC2 instance costs when you make an hourly spend commitment to an instance family and Region for a 1-year or 3-year term. This term commitment results in savings of up to 72 percent compared to On-Demand rates. Any usage up to the commitment is charged at the discounted Savings Plans rate (for example, $10 per hour). Any usage beyond the commitment is charged at regular On-Demand rates.
How are Savings Plan different from Reserved Instances ?
Unlike Reserved Instances, however, you don't need to specify up front what EC2 instance type and size (for example, m5.xlarge), OS, and tenancy to get a discount. Further, you don't need to commit to a certain number of EC2 instances over a 1-year or 3-year term. Additionally, the EC2 Instance Savings Plans don't include an EC2 capacity reservation option.
Spot Instances 🐞¶
Spot Instances are ideal for workloads with flexible start and end times, or that can withstand interruptions. Spot Instances use unused Amazon EC2 computing capacity and offer you cost savings at up to 90% off of On-Demand prices.
Example
If you make a Spot request and Amazon EC2 capacity is available, your Spot Instance launches. However, if you make a Spot request and Amazon EC2 capacity is unavailable, the request is not successful until capacity becomes available. The unavailable capacity might delay the launch of your background processing job.
Tenancy 🏢¶
Shared Tenancy¶
By default, EC2 instances run on shared tenancy hardware. This means that multiple AWS accounts might share the same physical hardware.
Dedicated Instance 🏗️¶
Dedicated Instances are EC2 instances that run on hardware that's dedicated to a single AWS account. This means that Dedicated Instances are physically isolated at the host hardware level from instances that belong to other AWS accounts, even if those accounts are linked to a single payer account. However, Dedicated Instances might share hardware with other instances from the same AWS account that are not Dedicated Instances.
Dedicated Hosts 🏠¶
Dedicated Instances provide no visibility or control over instance placement, and they do not support host affinity. If you stop and start a Dedicated Instance, it might not run on the same host. Similarly, you cannot target a specific host on which to launch or run an instance. Additionally, Dedicated Instances provide limited support for Bring Your Own License (BYOL).
When to use Dedicated Host?
If you require visibility and control over instance placement and more comprehensive BYOL support, consider using a Dedicated Host instead.
Boot volumes 🥾¶
This is easiest to remember by noting that HDD types are not available to use as boot volumes. General SSD and Provisioned IOPS are.
User Data 👱¶
When you launch an Amazon EC2 instance, you can pass user data to the instance that is used to perform automated configuration tasks, or to run scripts after the instance starts.
How user data is handled in Linux and Windows?
On Linux instances, you can pass two types of user data to Amazon EC2:
- shell scripts
- cloud-init directives
You can also pass this data into the launch instance wizard as plain text, as a file (this is useful for launching instances with the command line tools), or as base64-encoded text (for API calls).
On Windows instances, the launch agents handle your user data scripts.
EC2 Placement groups 🎡¶
When you launch a new EC2 instance, the EC2 service attempts to place the instance in such a way that all of your instances are spread out across underlying hardware to minimize correlated failures. You can use placement groups to influence the placement of a group of interdependent instances to meet the needs of your workload.
Depending on the type of workload, you can create a placement group using one of the following placement strategies:
Cluster: It means placing the instances in the same rack and AZ so that there is low latency and high throughput. It packs instances close together inside an Availability Zone. This strategy enables workloads to achieve the low-latency network performance necessary for tightly-coupled node-to-node communication that is typical of HPC applications.
Spread: A spread placement group is a group of instances that are each placed on distinct racks, with each rack having its own network and power source. The following image shows seven instances in a single Availability Zone that are placed into a spread placement group. The seven instances are placed on seven different racks. Spread placement groups are recommended for applications that have a small number of critical instances that should be kept separate from each other.
Partition: Same as Spread but with a difference that in this, we can have multiple instances in the same partition. In this case, the different racks have a different power source. Use case: HDFS, Cassandra, etc.
Partition placement groups help reduce the likelihood of correlated hardware failures for your application. When using partition placement groups, Amazon EC2 divides each group into logical segments called partitions. Amazon EC2 ensures that each partition within a placement group has its own set of racks. Each rack has its own network and power source. No two partitions within a placement group share the same racks, allowing you to isolate the impact of a hardware failure within your application.
The following image is a simple visual representation of a partition placement group in a single Availability Zone. It shows instances that are placed into a partition placement group with three partitions—Partition 1, Partition 2, and Partition 3. Each partition comprises multiple instances. The instances in a partition do not share racks with the instances in the other partitions, allowing you to contain the impact of a single hardware failure to only the associated partition.
Storage Options 📦¶
Persistent¶
For data that you want to retain longer, or if you want to encrypt the data, use Amazon EBS volumes instead. EBS volumes have the following features:
- EBS volumes preserve their data through instance stops and terminations
- You can back up EBS volumes with
EBS snapshots - You can remove EBS volumes from one instance, and reattach them to another
- EBS volumes support
full-volume encryption
Emphemral/Instance-backed¶
Some Amazon EC2 instance types come with a form of directly attached, block-device storage known as an instance store. Use the instance store for temporary storage.
Data will be lost
Data that's stored in instance store volumes isn't persistent through instance stops, terminations, or hardware failures.
Data will remain if instance reboots
Security Group 🔐¶
What is SG?
Its an instance level firewall.
-
Security groups only contain allow rules, not deny rules.
-
A security group can actually have no inbound or outbound rules.
-
A security group does require a name and description, though.
-
A security group can be attached to multiple constructs, like an EC2 instance, - but is ultimately associated with a network interface, which in turn is - attached to individual instances.
By default SG has
- Outbound 0.0.0.0/0 for all protocols allowed for IPV4
- Outbound ::/0 for all protocols allowed for IPV6
-
Security group rules have a protocol and a description. They do not have a - subnet, although they can have CIDR blocks or single IP addresses. Instances - can associate with a security group, but a security group does not itself refer - to a specific instance.
-
Default security groups prevent all incoming traffic and allow all traffic out - whereas the new SG allows all the outgoing traffic and blocks all the incoming traffic.
Auto Scaling 📈¶
Types of Auto Scaling
There are a number of valid scaling policies for Auto Scaling:
Maintain current instance levels: used to ensure that a specific number of instances is running at all times.Manual scaling: Manual scaling allows you to specify a minimum and a maximum number of instances as well as the desired capacity. The Auto Scaling policy then handles maintaining that capacity.Schedule-based scaling:Demand-based scaling: Demand-based scaling allows you to specify parameters to control scaling. One of those parameters can be CPU utilization
Encryption Settings 🧞♂️¶
-
Client-side encryption involves the client (you, in this example) managing the - entire encryption and decryption process. AWS only provides storage.
-
SSE-S3, SSE-KMS, and SSE-C are all valid approaches to server-side S3 - encryption.
-
SSE-KMS provides a very good audit trail and security.
-
SSE-S3 requires that Amazon S3 manage the data and master encryption keys while - SSE-KMS requires that AWS manage the data key but you manage the customer - master key (CMK) in AWS KMS.
Status Checks ☑️¶
Amazon EC2 performs automated checks on every running EC2 instance to identify hardware and software issues. You can view the results of these status checks to identify specific and detectable problems.
We can't disable these checks
Status checks are performed every minute, returning a pass or a fail status.
If all checks pass, the overall status of the instance is OK
If one or more checks fail, the overall status is impaired
Status checks are built into Amazon EC2, so they cannot be disabled or deleted.
There are three types of status checks
System Check ✅¶
Its something on AWS end
Instance Check¶
Its something on our end and will require your input
Attached EBS Check¶
Attached EBS status checks monitor if the Amazon EBS volumes attached to an instance are reachable and able to complete I/O operations. The StatusCheckFailed_AttachedEBS metric is a binary value that indicates impairment if one or more of the EBS volumes attached to the instance are unable to complete I/O operations.
Notes 📝¶
- EC2 instances, as well as
ECS containers, can both be scaled up and down byAuto Scaling -
A launch configuration contains an
AMI ID,key pair,instance type,security groups, and possibly ablock device mapping. -
InService and Standby are valid states for an instance in an auto-scaling group.
- You have to create a launch configuration first, then an Auto Scaling group, - and then you can verify your configuration and group.
- A
launch configurationneeds a single AMI ID to use for all instances it - launches. - It is generally better to allow AWS to handle encryption in cases where you - want to ensure all encryption is the same across a data store.
- A bastion host is a publicly accessible host that allows traffic to connect to - it. Then, an additional connection is made from the bastion host into a private - subnet and the hosts within that subnet.
- The security of the bastion must be different from the hosts in the private - subnet. The bastion host should be hardened significantly as it is public, but - also accessible; this is in many ways the opposite of the security requirements - of hosts within a private subnet.
- For private subnet instances, you need a route out to a NAT gateway, and that - NAT gateway must be in a public subnet—otherwise, it would not itself be able - to provide outbound traffic access to the Internet.
- NAT gateway is essentially a managed service and a NAT instance as an instance (- which you manage) for networking.
- all custom NACLs disallow all inbound and outbound traffic. It is only a VPC’s - default NACL that has an “allow all” policy.
- An instance has a primary network interface in all cases but can have - additional network interfaces attached.
- You can only assign a single role to an instance.
- By default, root volumes are terminated on instance deletion, and by default, additional EBS volumes attached to an instance are not.