S3 ¶
-
It is object-based storage.
-
Files can be from 0 bytes to 5 TB.
-
Buckets are created in a
region, not in anAZ. It means that S3 is a region-based and fully managed service. -
A bucket is a folder.
-
The object has a:
keyvalue(5 Tb max size)version idmetadatasubresources(such as ACL and bucket policy)
-
S3 has a flat structure but we can create a directory by using the prefixes.
-
It has
read after writeconsistency. -
Eventual consistencyfor overwriting. -
It has a simple web service interface.
-
A
multipart uploadallows an application to upload a large object as a set of smaller parts uploaded in parallel. Upon completion, S3 combines the smaller pieces into the original larger object. -
We can use tags in objects to group various objects and later retrieve them.
-
S3 is a
restful web service. -
Tags can be used in
cloud-trail,cloud-watch, andlifecycle management, etc. -
The lifecycle of tiers means we can move them from one tier to another tier (this can be automated as well).
-
Use
MFAfor delete to make sure someone else does not delete data in bucket. -
ACLis used to grant fine-grained access on bucket. -
First-byte latencyis the time between requesting an object from the service and when that data starts to arrive. With S3 (for example) that time is measured in milliseconds and in many cases could be considered instant. -
Cross-region replicationwill replicate the data across the regions.
- Users can save data to the edge locations in case of
transfer-acceleration.
Can I install OS?
We can not install an operating system on S3.
-
We can create up to 100 buckets by default in one account.
-
Buckets have
sub-resources; which are the resources that can not exist on its own.
What are we geting charged for?
- Object tagging
- Storage
- Requests
- Transfer acceleration
Remember
Standard IAwill charge every time we are going to use the data. It is usually used for backups etc.Glacierhas minimum storage for 3 months andGlacier deep archivehas it for a minimum of 6 months.- For
Intelligent tiering, it will put the data automatically toIAif it is not used for 30 days and there will be no archival feel associated with it as well (special case). - Object size less than 128 kb will not be moved by using the Intelligent tiering, it will remain in the standard tier.
- S3 is a universal namespace, so it has to be unique.
S3 storage tiers 🪣¶
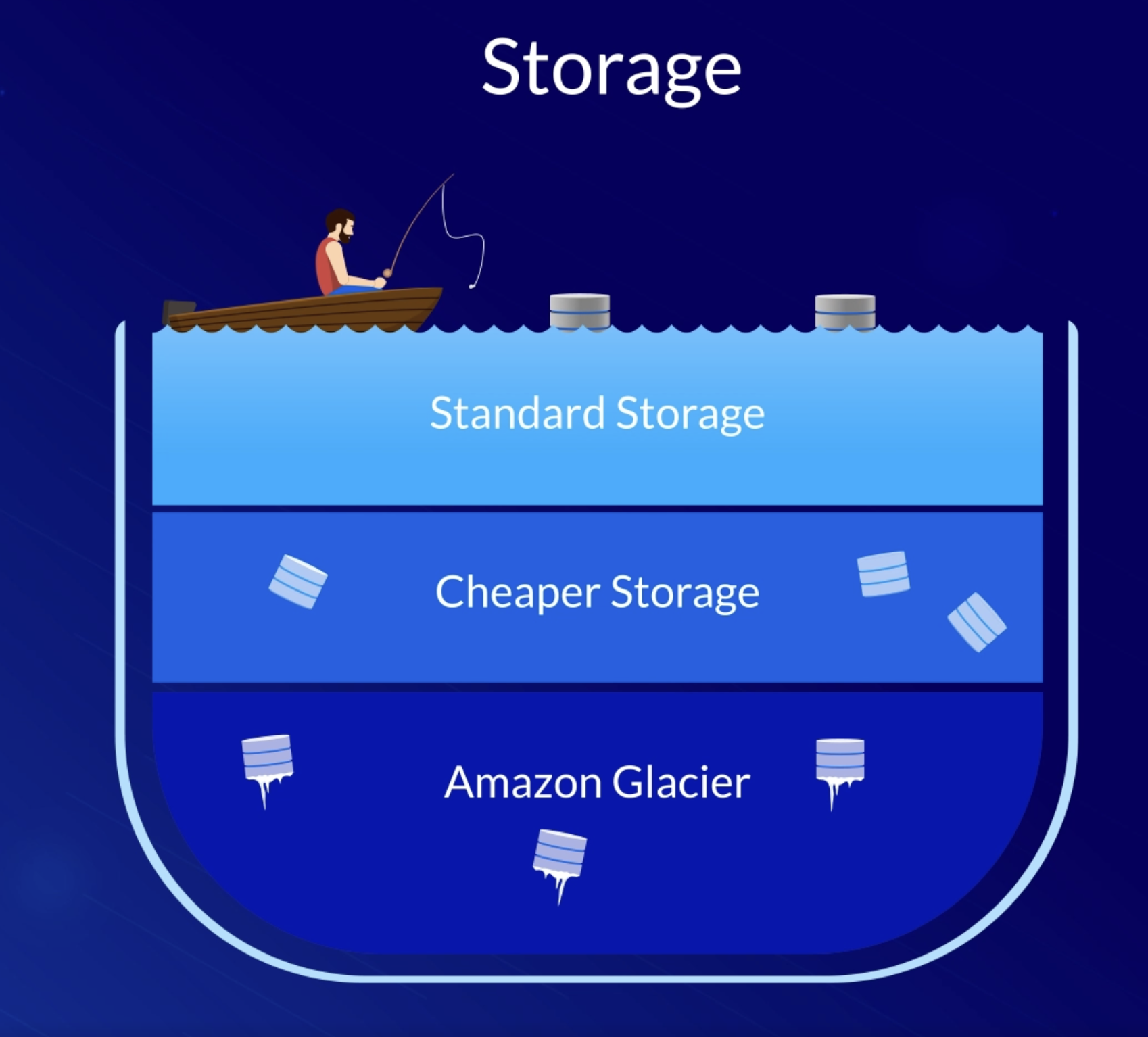
Standard¶
Standard S3 is the most expensive tier.
Designed for frequently accessed data and it stores data in a minimum of 3 Availability Zones
Infrequently Accessed (Standard-IA)¶
Similar to Amazon S3 Standard but has a lower storage price and higher retrieval price.
One zone 🎯¶
It costs less as we use the only 1 zone to keep data.
Tip
All other tiers except one-zone replicate data in 3 or more AZ's
One zone -IA 📦¶
S3 One Zone-IA is intended for use cases with infrequently accessed data that is re-creatable, such as storing secondary backup copies of on-premises data or for storage that is already replicated in another AWS Region for compliance or disaster recovery purposes.
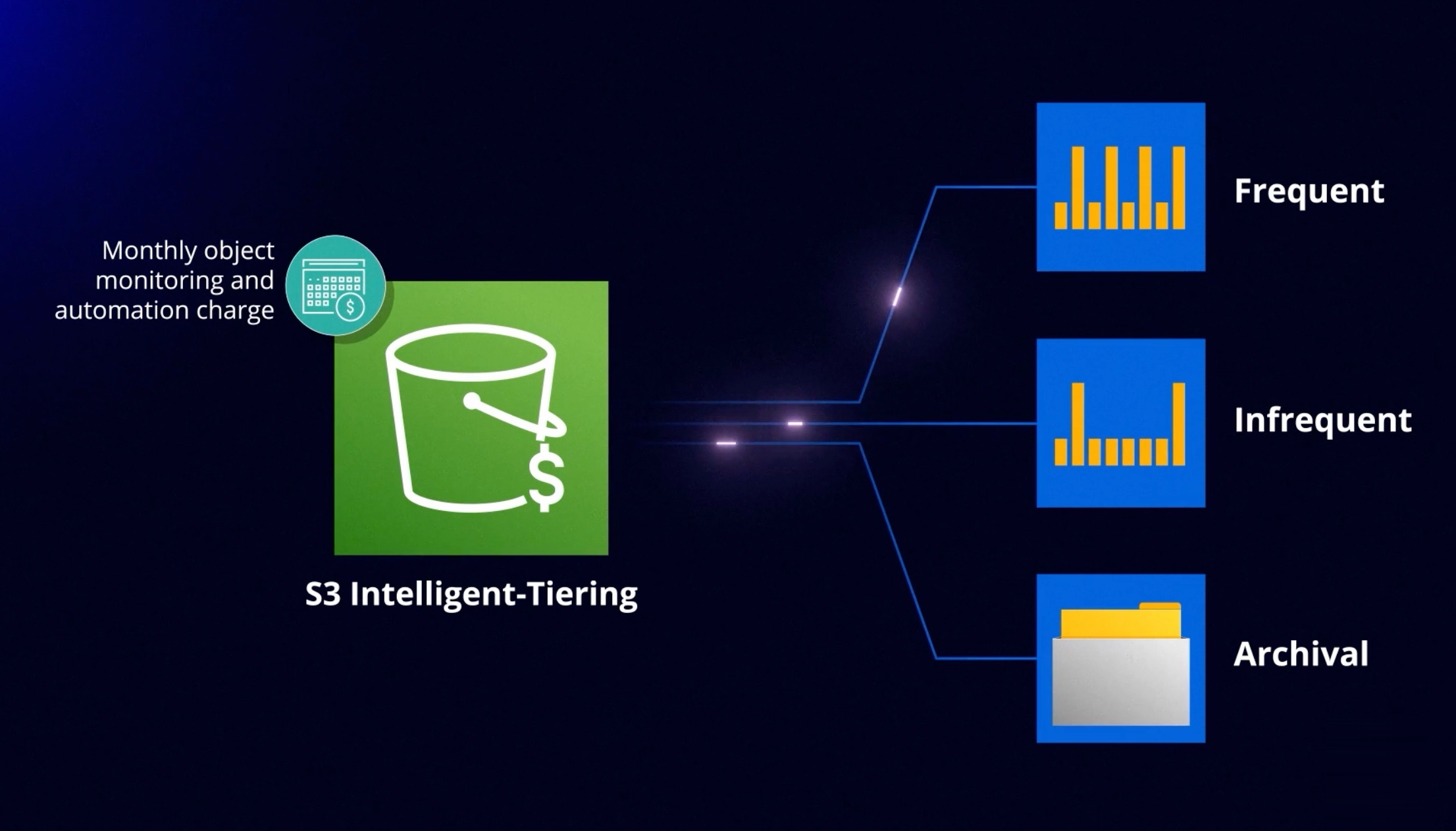
Intelligent tiering 🧠¶
- It will use ML to move data between tiers.
- Requires a small monthly monitoring and automation fee per object
- In the S3 Intelligent-Tiering storage class, Amazon S3 monitors objects’ access patterns. If you haven’t accessed an object for 30 consecutive days, Amazon S3 automatically moves it to the infrequent access tier, S3 Standard-IA. If you access an object in the infrequent access tier, Amazon S3 automatically moves it to the frequent access tier, S3 Standard.
S3 Glacier Instant Retrieval ☃️¶
You can retrieve objects stored in the S3 Glacier Instant Retrieval storage class within milliseconds, with the same performance as S3 Standard.
Glacier Flexible Retrival 🏔️¶
It is used for data archival, mainly for compliance reasons. Retrival time is from minutes to hours
Glacier deep archive 🔑¶
Long term data archieve with retrival time < 12 hours
S3 Outposts 📫¶
Amazon S3 Outposts delivers object storage to your on-premises AWS Outposts environment. Amazon S3 Outposts is designed to store data durably and redundantly across multiple devices and servers on your Outposts. It works well for workloads with local data residency requirements that must satisfy demanding performance needs by keeping data close to on-premises applications.
Lifecycle Management 🔄¶
An S3 Lifecycle configuration is a set of rules that define actions that Amazon S3 applies to a group of objects. There are two types of actions:
Transition actions– These actions define when objects transition to another storage class.
Example
You might choose to transition objects to the S3 Standard-IA storage class 30 days after creating them, or archive objects to the S3 Glacier Flexible Retrieval storage class one year after creating them.
In an S3 Lifecycle configuration, you can define rules to transition objects from one storage class to another to save on storage costs. When you don't know the access patterns of your objects, or if your access patterns are changing over time, you can transition the objects to the S3 Intelligent-Tiering storage class for automatic cost savings
Expiration actions– These actions define when objects expire. Amazon S3 deletes expired objects on your behalf. Lifecycle expiration costs depend on when you choose to expire objects.
Structure of S3 🏛️¶
S3 consist of the following:
- Key: it is the object name.
- Value: it is the actual data we are storing inside the object.
- Version id
- Metadata
- Sub-resources
- ACL
- Torrents
Consistency in S3 ♾️¶
-
Read after write: you can read after writing. -
Eventual consistencyfor update and delete.
In S3-IA, we are charged a retrieval fee.
In S3 Glacier, we can configure the retrieval time from minutes to hours.
Pricing 💰¶
Prices are S3 >S3 IA > S3 intelligent tiering > S3 one zone > S3 glacier > S3 glacier deep archive
Access ❌¶
ACL 📋¶
Amazon S3 access control lists (ACLs) enable you to manage access to buckets and objects. Each bucket and object has an ACL attached to it as a subresource. It defines which AWS accounts or groups are granted access and the type of access.
When a request is received against a resource, Amazon S3 checks the corresponding ACL to verify that the requester has the necessary access permissions.
Recommendation is not to use ACL's
A majority of modern use cases in Amazon S3 no longer require the use of ACLs. We recommend that you keep ACLs disabled, except in unusual circumstances where you need to control access for each object individually. With ACLs disabled, you can use policies to control access to all objects in your bucket, regardless of who uploaded the objects to your bucket.
Note
-
They are XML docs use to give access to both objects and the bucket.
-
Each bucket and the object has the ACL attached to it in the sub-resources part.
-
The default ACL provides full access to a resource owner
-
A grantee can be an AWS account or one of the predefined Amazon S3 groups.
-
When an object is created, then the only ACL is created not the user policy or bucket policy.
-
ACL’s can be used to grant permissions to pre-defined groups but not to an IAM user.
-
With ACL we can NOT provide the deny rules and conditional access. All we can do is provide the basic read/write permissions.
Canned ACL: Amazon S3 supports a set of predefined grants, known as canned ACLs. Each canned ACL has a predefined set of grantees and permissions. They are an easy way to grant access.
When you create a bucket or an object, Amazon S3 creates a default ACL that grants the resource owner full control over the resource. This is shown in the following sample bucket ACL (the default object ACL has the same structure):
<?xml version="1.0" encoding="UTF-8"?>
<AccessControlPolicy xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<Owner>
<ID>*** Owner-Canonical-User-ID ***</ID>
<DisplayName>owner-display-name</DisplayName>
</Owner>
<AccessControlList>
<Grant>
<Grantee xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:type="Canonical User">
<ID>*** Owner-Canonical-User-ID ***</ID>
<DisplayName>display-name</DisplayName>
</Grantee>
<Permission>FULL_CONTROL</Permission>
</Grant>
</AccessControlList>
</AccessControlPolicy>
Policies 🚔¶
2 types of policies are
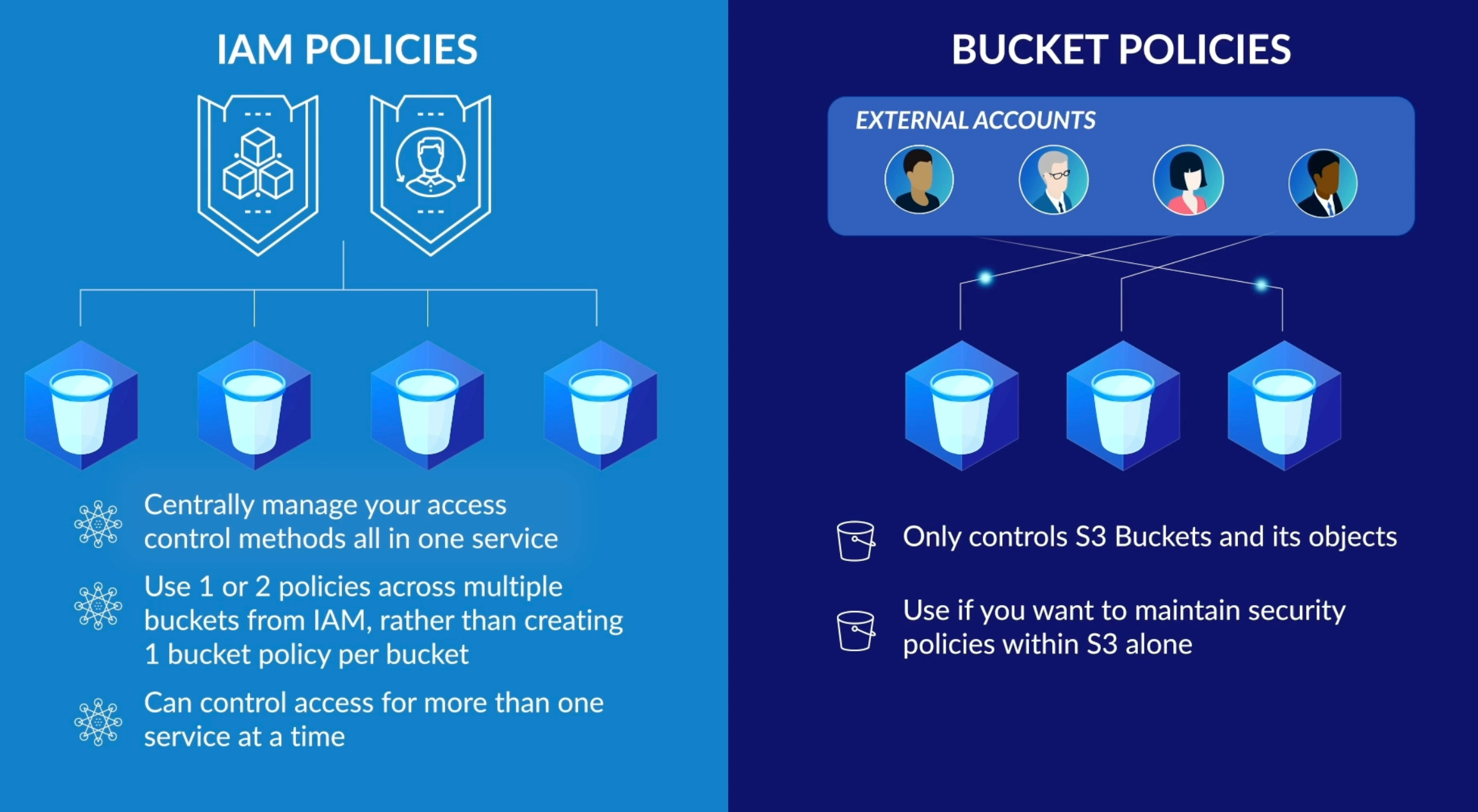
Resource-based AKA Bucket policy¶
Access control list (ACL): used for objects- Bucket policy(JSON) and bucket ACL (XML)
User/identity-based/IAM¶
By default, users and roles don't have permission to create or modify Amazon S3 resources. They also can't perform tasks by using the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS API. To grant users permission to perform actions on the resources that they need, an IAM administrator can create IAM policies. The administrator can then add the IAM policies to roles, and users can assume the roles.
- ACL is legacy while
bucket policyis new Root userdoes not have the IAM policy- Deny access always wins.
- You pay for storage, data replication, requests, management (monitoring)
- Bucket policy work at bucket level which the ACL works at the object level.
S3 Access Points ⭕️¶
Amazon S3 access points simplify data access for any AWS service or customer application that stores data in S3. Access points are named network endpoints that are attached to buckets that you can use to perform S3 object operations, such as GetObject and PutObject.
We can have multiple access points for single bucket.
Each access point has distinct permissions and network controls that S3 applies for any request that is made through that access point.
Each access point enforces a customized access point policy that works in conjunction with the bucket policy that is attached to the underlying bucket.
You can configure any access point to accept requests only from a virtual private cloud (VPC) to restrict Amazon S3 data access to a private network. You can also configure custom block public access settings for each access point.
S3 Access Analyzer¶
IAM Access Analyzer for S3 alerts you to S3 buckets that are configured to allow access to anyone on the internet or other AWS accounts, including AWS accounts outside of your organization.
For each public or shared bucket, you receive findings into the source and level of public or shared access.
IAM Access Analyzer Example
IAM Access Analyzer for S3 might show that a bucket has read or write access provided through a bucket access control list (ACL), a bucket policy, a Multi-Region Access Point policy, or an access point policy.
CORS 🙅♀️¶
Cross-origin resource sharing (CORS) defines a way for client web applications that are loaded in one domain to interact with resources in a different domain. With CORS support, you can build rich client-side web applications with Amazon S3 and selectively allow cross-origin access to your Amazon S3 resources.
How does Amazon S3 evaluate the CORS configuration on a bucket?
When Amazon S3 receives a preflight request from a browser, it evaluates the CORS configuration for the bucket and uses the first CORSRule rule that matches the incoming browser request to enable a cross-origin request. For a rule to match, the following conditions must be met:
-
The
Origin headerin a CORS request to your bucket must match the origins in theAllowedOriginselement in your CORS configuration. -
The HTTP methods that are specified in the
Access-Control-Request-Methodin a CORS request to your bucket must match the method or methods listed in theAllowedMethodselement in your CORS configuration. -
The headers listed in the
Access-Control-Request-Headersheader in a pre-flight request must match the headers in theAllowedHeaderselement in your CORS configuration.
Object Lock 🔒¶
Why do we need object locking?
S3 Object Lock can help prevent Amazon S3 objects from being deleted or overwritten for a fixed amount of time or indefinitely. Object Lock uses a write-once-read-many (WORM) model to store objects.
You can use Object Lock to help meet regulatory requirements that require WORM storage, or to add another layer of protection against object changes or deletion.
-
It can be done at time of creating bucket
-
We need to enable versioning to enable locks. If you put an object into a bucket that already contains an existing protected object with the same object key name, Amazon S3 creates a new version of that object. The existing protected version of the object
remains lockedaccording to its retention configuration.
-
Retention period – A retention period protects an object version for a fixed amount of time. When you place a retention period on an object version, Amazon S3 stores a timestamp in the object version's metadata to indicate when the retention period expires. After the retention period expires, the object version can be overwritten or deleted.
-
Legal hold – A legal hold provides the same protection as a retention period, but it has no expiration date. Instead, a legal hold remains in place until you explicitly remove it. Legal holds are independent from retention periods and are placed on individual object versions.
-
Retention modes
-
Governance mode: In governance mode, users can't overwrite or delete an object version or alter its lock settings unless they have special permissions. With governance mode, you protect objects against being deleted by most users, but you can still grant some users permission to alter the retention settings or delete the objects if necessary. You can also use governance mode to test retention-period settings before creating a compliance-mode retention period.
-
Compliance mode: In compliance mode, a protected object version can't be overwritten or deleted by any user, including the root user in your AWS account. When an object is locked in compliance mode, its retention mode can't be changed, and its retention period can't be shortened. Compliance mode helps ensure that an object version can't be overwritten or deleted for the duration of the retention period.
-
Encryption 🔐¶
- Encryption in transit is done using
SSLorTLS - Encryption in transit is optional.
What is delete marker?
If we delete the files in the S3 bucket with versioning turned on, then it will place a delete marker. We can restore the files if we delete the delete marker.
Lifecycle rules can be used in conjunction with versioning.
Encryption is of 2 types as shown below
Server-side 🤖¶
- S3 managed keys AKA SSE- S3 (USE AES-256): Here keys are managed by AWS
- Key management service (KMS): Here client has more transparency
Client-side 👨¶
- Here we use your own keys
- Once versioning is enabled, It can not be disabled but can only be suspended.
Server Access Logs 💿¶
Server access logs provides detailed records for the requests that are made to an Amazon S3 bucket. Server access logs are useful for many applications.
For example, access log information can be useful in security and access audits. This information can also help you learn about your customer base and understand your Amazon S3 bill.
This feature is not enabled by default
By default, Amazon S3 doesn't collect server access logs.
When you enable logging, Amazon S3 delivers access logs for a source bucket to a destination bucket (also known as a target bucket) that you choose.
The destination bucket must be in the same AWS Region and AWS account as the source bucket.
Here are some key points to remember
Key points
-
There is no extra charge for enabling server access logging on an Amazon S3 bucket. However, any log files that the system delivers to you will accrue the usual charges for storage.
-
You can delete the log files at any time. We do not assess data-transfer charges for log file delivery, but we do charge the normal data-transfer rate for accessing the log files.
-
Your destination bucket should NOT have server access logging enabled. You can have logs delivered to any bucket that you own that is in the same Region as the source bucket, including the source bucket itself. However, delivering logs to the source bucket will cause an infinite loop of logs and is not recommended.
-
S3 buckets that have
S3 Object Lockenabled can't be used as destination buckets for server access logs. Your destination bucket must NOT have a default retention period configuration.
File replication ⏩️¶
-
Cross-region replicationneeds theversioningto be enabled for both the source and destination buckets. -
The existing files in the bucket which were added before the replication are not replicated, so we have to replicate them manually.
-
The subsequently updated files will be replicated automatically.
-
For the replicated files, if you put a
delete marker/or delete a file, then the file is not deleted on the replicated.
Static File Hosting 🌏¶
You can use Amazon S3 to host a static website. On a static website, individual webpages include static content. They might also contain client-side scripts.
By contrast, a dynamic website relies on server-side processing, including server-side scripts, such as PHP, JSP, or ASP.NET. Amazon S3 does not support server-side scripting, but AWS has other resources for hosting dynamic websites.
Remember
When you configure a bucket as a static website, you must enable static website hosting, configure an index document, and set permissions.
Requester Pays 💳¶
In general, bucket owners pay for all Amazon S3 storage and data transfer costs that are associated with their bucket. However, you can configure a bucket to be a Requester Pays bucket.
With Requester Pays buckets, the requester instead of the bucket owner pays the cost of the request and the data download from the bucket. The bucket owner always pays the cost of storing data.
Typically, you configure buckets to be Requester Pays buckets when you want to share data but not incur charges associated with others accessing the data. For example, you might use Requester Pays buckets when making available large datasets, such as zip code directories, reference data, geospatial information, or web crawling data
Anonymous access is not allowed with Requester Pays
You must authenticate all requests involving Requester Pays buckets. The request authentication enables Amazon S3 to identify and charge the requester for their use of the Requester Pays bucket.
S3 Transfer Acceleration 🚅¶
It uses the CloudFront to fasten the process of uploading. The users will first upload to the edge location from where the files are uploaded to bucked using Amazon’s backbone network.
!!! question 'Which policies should I use?' We should use the User policy or the bucket policy as it will help in providing us in access at a much fine-grained level. ACL’s are the legacy tech.
User Groups 👱¶
S3 pre-defined groups: Amazon S3 has a set of predefined groups. When granting account access to a group, you specify one of our URIs instead of a canonical user ID. We provide the following predefined groups:
- Authenticated Users group: all AWS accounts
- All Users group: authenticated and anonymous users.
- Log Delivery group
Tip
The canonical user ID is an alpha-numeric identifier, such as 79a59df900b949e55d96 , that is an obfuscated form of the AWS account ID. You can use this ID to identify an AWS account when granting cross-account access to buckets and objects using Amazon S3.
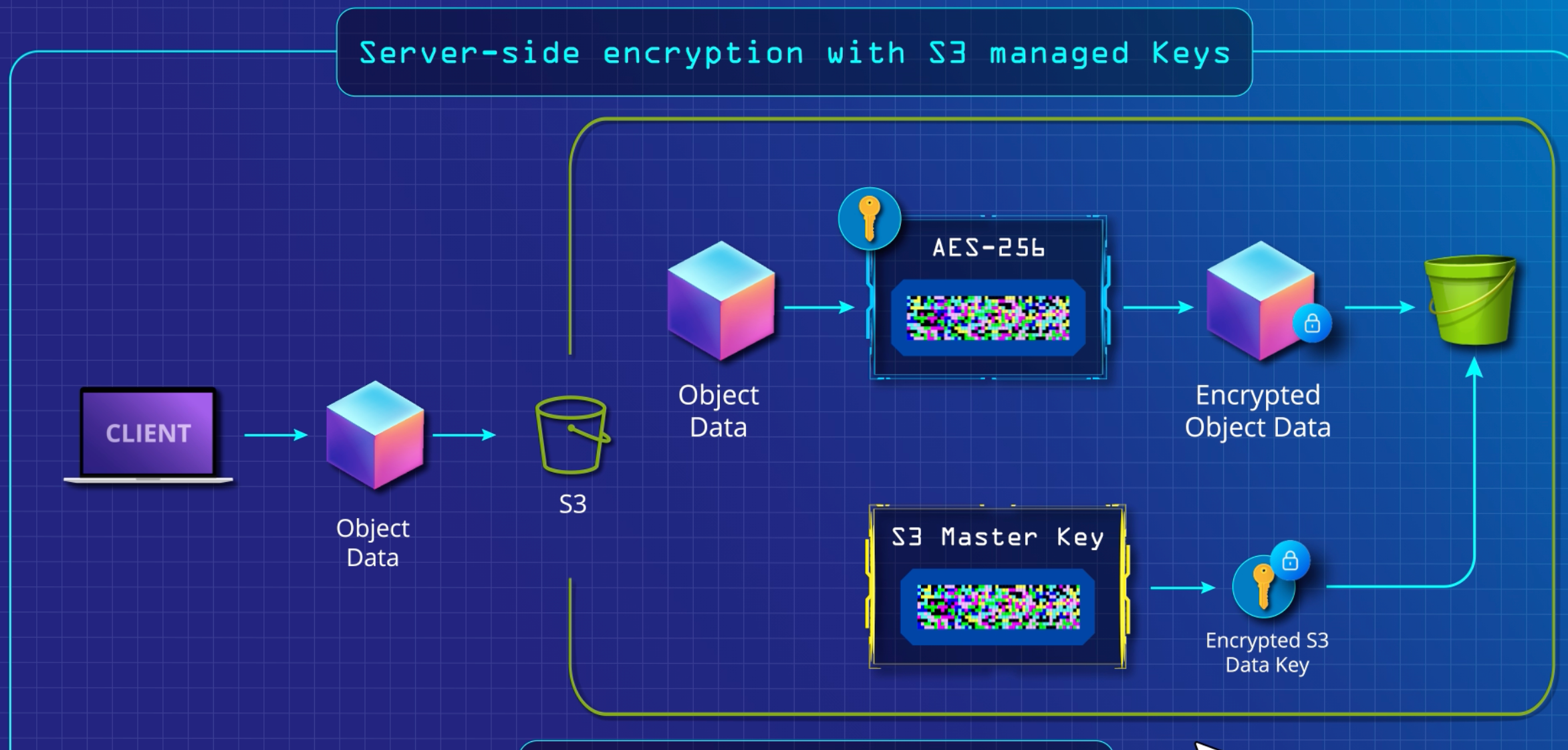
Server-side encryption 🪄¶
Server-side encryption is the encryption of data at its destination by the application or service that receives it. Amazon S3 encrypts your data at the object level as it writes it to disks in its data centers and decrypts it for you when you access it.
SSE-S3 🪣¶
Server-Side Encryption with Amazon S3-Managed Keys (SSE-S3): When you use SSE-S3, each object is encrypted with a unique key. As an additional safeguard, it encrypts the key itself with a master key that it regularly rotates.
- All the objects are encrypted using different keys
- We can not manage keys in this case
SSE-KMS 🔐¶
Server-Side Encryption with Customer Master Keys (CMKs) Stored in AWS Key Management Service (SSE-KMS): The SSE-KMS is similar to SSE-S3, but with some additional benefits and charges for using this service. There are separate permissions for the use of a CMK that provides added protection against unauthorized access of your objects in Amazon S3.
-
We can create and use data keys, master keys, and rotate keys as well.
-
It gives us a lot of control as a user can choose a key to encrypt the object.
-
We have access to data keys and master keys.
-
AWS does not have access to the keys in this case.
-
We can audit the use of KMS using Cloudtrail that shows when your CMK was used and by whom.
SSE-C 👨🦰¶
Server-Side Encryption with Customer-Provided Keys (SSE-C): with SSE-C you manage the encryption keys and Amazon S3 manages the encryption, as it writes to disks and decryption when you access your objects.
-
The Key is managed by the user.
-
A user generates the key and uploads it with data.
-
Must use
HTTPSto upload the objects. -
If we lose the key, so we lose the data.
-
S3 will discard the key after using it in this case.
S3 and EBS difference 🪣¶
S3 (Simple Storage Service) and EBS (Elastic Block Store) are two file storage services provided by Amazon. The main difference between them is with what they can be used with. EBS is specifically meant for EC2 (Elastic Computing Cloud) instances and is not accessible unless mounted to one.
On the other hand, S3 is not limited to EC2. The files within an S3 bucket can be retrieved using HTTP protocols and even with BitTorrent. Many sites use S3 to hold most of their files because of its accessibility to HTTP clients; web browsers for example.
As already stated above, you need some type of software in order to read or write information with S3. With EBS, a volume can be mounted on an EC2 instance and it would appear just like a hard disk partition. It can be formatted with any file system and files can be written or read by the EC2 instance just like it would to a hard drive.
When it comes to the total amount that you can store, S3 still has the upper hand. EBS has a standard limit of 20 volumes with each volume holding up to 1TB of data. With S3, the standard limit is at 100 buckets with each bucket having an unlimited data capacity. S3 users do not need to worry about filling a bucket and the only concern is having enough buckets for your needs.
S3 can't be used concurrently
A limitation of EBS is its inability to be used by multiple instances at once. Once it is mounted by an instance, no other instance can use it.
S3 can have multiple images of its contents so it can be used by many at the same time.
An interesting side-effect of this capability is something called ‘eventual consistency’. With EBS, data read or write occurs almost instantly. With S3, the changes are not written immediately so if you write something, it may not be the data that a read operation returns.
-
EBS can only be used with EC2 instances while S3 can be used outside EC2.
-
EBS appears as a
mountable volumewhile the S3 requires software to read and write data. -
EBS can accommodate a smaller amount of data than S3.
-
EBS can only be used by one EC2 instance at a time while S3 can be used by multiple instances.
-
S3 typically experiences write delays while EBS does not as EBS is attached to an instance.
Limits ⅀¶
Until 2018 there was a hard limit on S3 puts of 100 PUTs per second. To achieve this care needed to be taken with the structure of the name Key to ensuring parallel processing.
As of July 2018, the limit was raised to 3500 and the need for the Key design was basically eliminated.
Notes 📕¶
Some points to remember
-
The
S3 policyis a JSON doc. -
HTTP and HTTPS are both enabled in S3 by default, but we can disable the HTTP by using the bucket policy.
-
IAM is Universal.
-
S3 is not suitable to install OS or a database as it is object-based.
-
By default, the
buckets are privateand we have to make thempublic(remember this). -
We can log the requests made to the S3 and then later these logs can be sent to another account as well.
-
S3 supports
bittorrent protocolto retrieve any publicaly available object using torrent files (peer-to-peer). -
Data is encrypted by the client and the encrypted data is uploaded in case of Client-side encryption.
-
HTTPS uses asymmetric encryption.
-
We can apply
lifecycle rulesto a whole bucket or a subset. -
We can have 1000 lifecycle policies per bucket.
-
Lifecycle is defined as XML and is stored in the sub-resources section.
-
Lifecycle configuration on
multi-factor authentication (MFA)-enabled bucketsis NOT supported. This is because the MFA needs human intervention. -
For glacier, we are charged for at least 90 days(3 months) and 180 days(6 months) for the deep archive.
-
The difference between
Security GroupandACLsis that the Security Group acts as a firewall for associated Amazon EC2 instances, controlling both inbound and outbound traffic at the instance level, while ACLs act as a firewall for associated subnets, controlling both inbound and outbound traffic at the subnet level. -
A particular folder cannot be tagged separately from other folders; only an entire bucket can be tagged.
-
With the exception of Glacier, retrieving data from the various S3 storage classes should be virtually identical (network issues notwithstanding).