AWS Glue ¶
-
AWS Glue is a
fully-managed ETL(extract, transform, and load) service that makes it simple and cost-effective to categorize your data, clean it, enrich it, and move it reliably between variousdata storesand data streams -
AWS Glue consists of a central metadata repository known as the
Glue Data Catalog, anETL enginethat automatically generates Python or Scala code, and a flexibleschedulerthat handles dependency resolution, job monitoring, and retries -
AWS Glue is serverless
How it works¶
-
AWS Glue is designed to work with semi-structured data.
-
It introduces a component called a dynamic frame, which you can use in your ETL scripts.
-
A dynamic frame is similar to an
Apache Spark dataframe, which is a data abstraction used to organize data into rows and columns, except that each record is self-describing so no schema is required initially. -
With dynamic frames, you get schema flexibility and a set of advanced transformations specifically designed for dynamic frames.
-
You can convert between dynamic frames and Spark dataframes, so that you can take advantage of both
AWS GlueandSpark transformationsto do the kinds of analysis that you want.
Use cases¶
-
You can use the AWS Glue console to discover data, transform it, and make it available for search and querying. The console calls the underlying services to orchestrate the work required to transform your data.
-
You can also use the AWS Glue API operations to interface with AWS Glue services. Edit, debug, and test your Python or Scala Apache Spark ETL code using a familiar development environment.
Reference architecture for streaming data pipeline¶
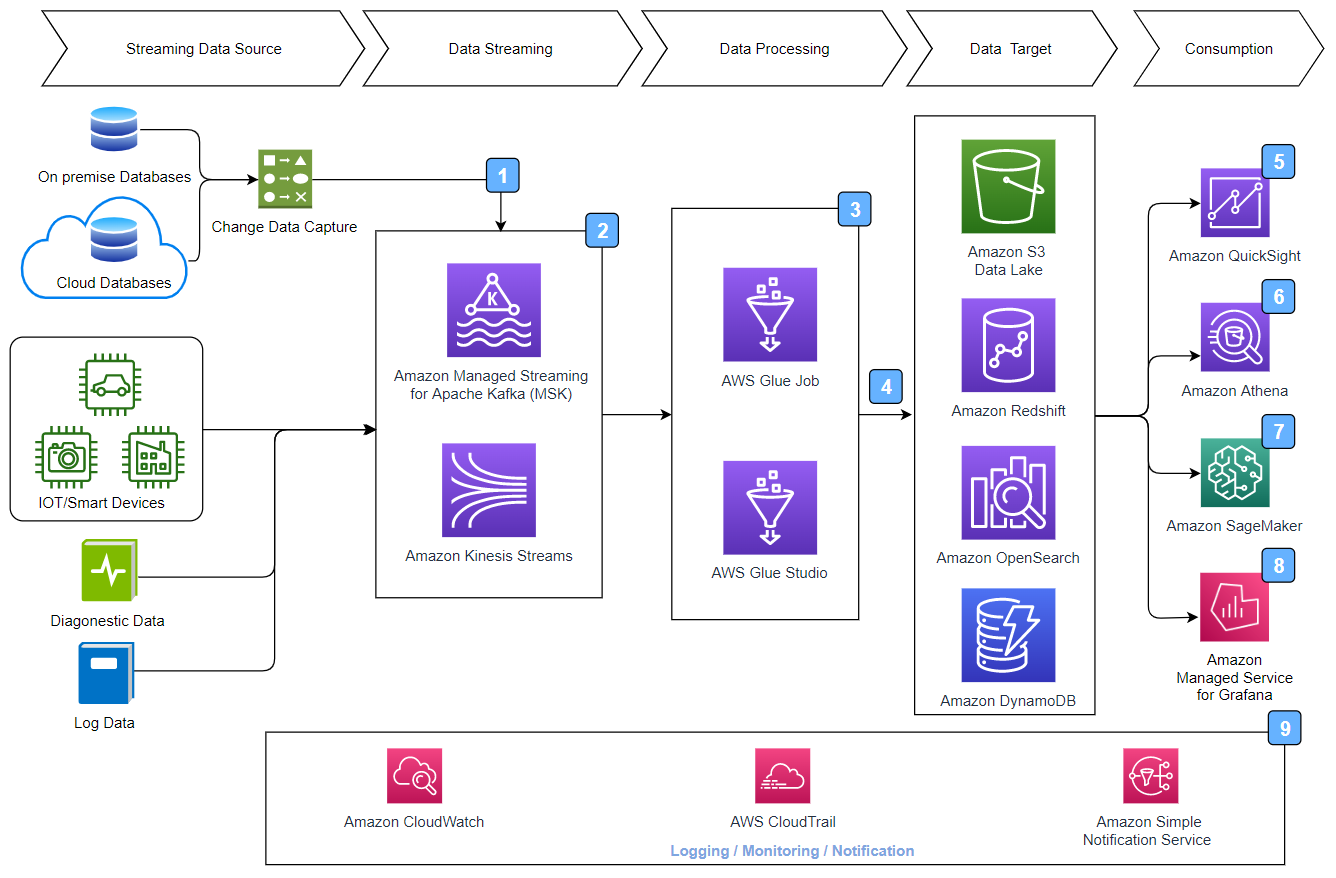
-
Data Source— In the previous architecture, there are multiple data sources. Near real-time data is generated through streaming data sources such as IoT devices, log and diagnostic data from application servers, and change data capture (CDC) from transactional data stores.
-
Data steaming — Messages and events are streamed into streaming services such as Amazon Kinesis Data Streams or Amazon MSK.
-
Stream data processing — In this step, you can create streaming ETL jobs that run continuously and consume data from streaming sources such as Amazon Kinesis Data Streams and Amazon MSK. The jobs cleanse and transform the data.
-
Stream data loading— The processed data is typically loaded into S3 data lakes or joint database connectivity (JDBC) data stores such as Amazon Redshift or NoSQL data sources such as Amazon DynamoDB or Amazon OpenSearch Service. After the data is loaded, the data can be consumed using services such as Amazon QuickSight, Amazon Athena, Amazon SageMaker, Amazon Managed Grafana, and so on.
-
Amazon QuickSight — Amazon QuickSight allows everyone in your organization to understand your data by asking questions in their native language, exploring through interactive dashboards, or automatically looking for patterns and outliers powered by ML.
-
Amazon Athena— Amazon Athena provides capability for ad hoc querying capability on the data stored in the data lake.
-
Amazon SageMaker — Amazon SageMaker and AWS AI services can be used to build, train, and deploy ML models, and add intelligence to your applications.
-
Amazon Managed Grafana — Amazon Managed Grafana is an open-source analytics platform that can be used to query, visualize, alert on, and understand metrics, no matter where they are stored.
-
Logging, monitoring, and notification — Amazon CloudWatch can be used for monitoring, Amazon SNS can be used for notification, and AWS CloudTrail can be used for event logging.