ADF ¶
Tldr
Azure Data Factory is Azure's cloud ETL service for scale-out serverless data integration and data transformation.It offers a code-free UI for intuitive authoring and single-pane-of-glass monitoring and management.
Concepts¶
Integration Runtime (IR)¶
This is a configuration object stored in the ADF metastore that defines the location and type of compute that you’ll use for parts of your pipeline that require computation. This can mean VMs for copying data, executing SSIS (SQL Server Integration Services) packages, or cluster size and type for Mapping Data Flows.
Self-Hosted IR¶
Another approach to executing ADF pipeline activities in a private network or to connect to on-premises data is by using the self-hosted integration runtime or SHIR.
Pipeline 🚰¶
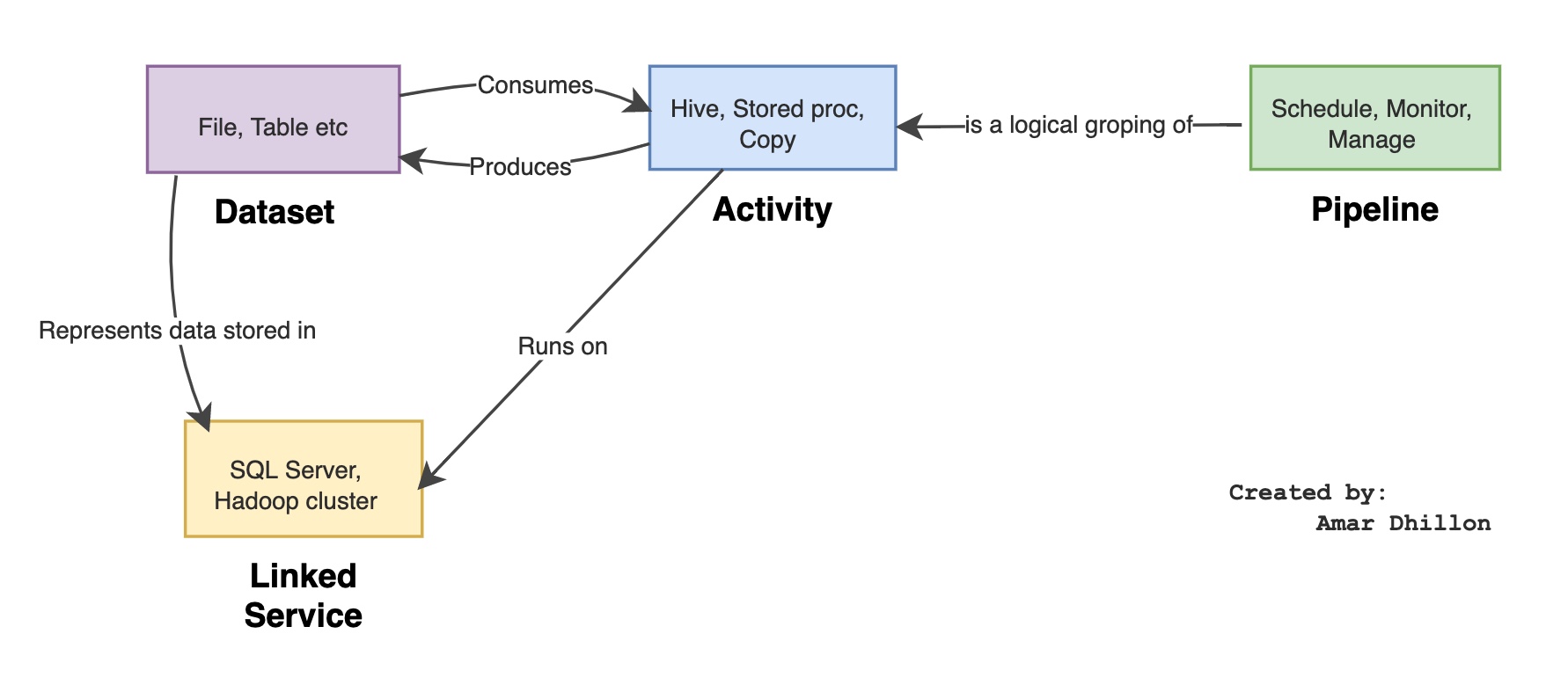
The primary unit of work in ADF is pipelines. Pipelines drive all of the actions that your data integration and ETL jobs perform. A pipeline is essentially a collection of activities that you connect together in a meaningful pattern to create a workflow. All actions in ADF are scheduled through a pipeline execution, including the Mapping Data Flows.
You deploy and schedule the pipeline instead of the activities independently.
Pipeline run¶
A pipeline run in Azure Data Factory defines an instance of a pipeline execution.
For example, say you have a pipeline that executes at 8:00 AM, 9:00 AM, and 10:00 AM. In this case, there are three separate runs of the pipeline or pipeline runs. Each pipeline run has a unique pipeline run ID. A run ID is a GUID that uniquely defines that particular pipeline run.
On-demand execution¶
The manual execution of a pipeline is also referred to as on-demand execution.
Activities¶
Pipelines are constructed from individual activities. Activities define the individual action that you wish to perform. There are many activities that you can use to compose a pipeline. Examples of activities include copying data (Copy activity), transforming data (Mapping Data Flows), “For Each,” “If Then,” and other control flow activities.
How to call external activities?
You can also call out to external compute activities like Databricks Notebook and Azure Functions to execute custom code.
Copy activity¶
Copy Activity in Data Factory copies data from a source data store to a sink data store.
Data Flow ⏳¶
Mapping Data Flows provide a way to transform data at scale without any coding required. You can design a data transformation job in the data flow designer by constructing a series of transformations. Start with any number of source transformations followed by data transformation steps. Then, complete your data flow with sink to land your results in a destination.
Triggers¶
Triggers allow you to set the conditions for your pipeline to execute. You can create schedule triggers, tumbling window, storage events, and custom events.
Triggers can be shared across pipelines inside your factory, and there is a separate monitoring view organized by trigger
Schedule Triggers¶
They allow you to set the execute frequency and times for your pipeline.
Tumbling windows¶
Tumbling window allows for time intervals. ADF will establish windows of time for the recurrence that you choose starting on the date that you choose.
Storage Events¶
Storage events will allow you to trigger your pipeline when a file arrives or is deleted from a storage account.
Custom Events¶
You can create custom topics in Azure Event Grid and then subscribe to those events. When a specific event is received by your custom event trigger, your pipeline will be triggered automatically.
Linked Service¶
Tldr
They are used to store credentials, location, and authentication mechanisms to connect to your data. Linked services are used by datasets and activities in ADF pipelines so that it can be determined where and how to connect to your data. You can share linked service definitions across objects in your factory.
Linked services are much like connection strings, which define the connection information needed for the service to connect to external resources.
Think of it this way; the dataset represents the structure of the data within the linked data stores, and the linked service defines the connection to the data source. For example, an Azure Storage linked service links a storage account to the service. An Azure Blob dataset represents the blob container and the folder within that Azure Storage account that contains the input blobs to be processed
Datasets 📀¶
Datasets define the shape of your data. In ADF, datasets do not contain or hold any data. Instead, they point to the data and provide ADF information about the schema for your data.
In ADF, your data does not require schema. You can work with data in a schema-less manner. When you build ETL jobs using schema-less datasets, you will build data flows that are known as “late binding” and working with “schema drift.”
Data Drift¶
Similar to metadata schema drift, data drift occurs when values inside of existing columns begin to arrive outside of a set domain or boundaries. In ADF, you can establish Assert expectations that define data ranges. When those domains or ranges of metadata rules are breached in the data, you can fail the job or tag the rows as data quality errors and make downstream decisions on how to handle those errors.