Lambda basics ¶
- Serverless computing allows you to build and run applications and services without thinking about servers 🖥️
- With serverless computing, your application still runs on servers, but all the server management is done by AWS
- It scales out instead of scaling up ⬆️ with the number of requests.
- Lambda functions are
stateless, with no affinity to the underlying infrastructure - Lambda functions are independent, meaning that they will get replicated with each event 🔥
Tip
Using AWS and its Serverless Platform, you can build and deploy applications on cost-effective services that provide built-in application availability and flexible scaling capabilities. This lets you focus on your application code instead of worrying about provisioning, configuring, and managing servers.
Which services are serverless?¶
Lambdais serverless- RDS is not serverless as it has downtime.
- Aurora is serverless.
- Dynamo, S3 is serverless.
Concepts¶
Function ⚡️¶
- A function is a resource that you can invoke to run your code in Lambda.
- A function has code to process the events that you pass into the
functionor that other AWS services send to the function.
Configuration 💬¶
When building and testing a function, you must specify three primary configuration settings: memory, timeout, and concurrency

15 min max timeout
The AWS Lambda timeout value dictates how long a function can run before Lambda terminates the Lambda function. At the time of this publication, the maximum timeout for a Lambda function is 900 seconds. This limit means that a single invocation of a Lambda function cannot run longer than 900 seconds (which is 15 minutes).
Trigger 🔫¶
A trigger is a resource or configuration that invokes a Lambda function. Triggers include AWS services that you can configure to invoke a function and event source mappings.
Tip
An event source mapping is a resource in Lambda that reads items from a stream or queue and invokes a function.
Trigger Types
Sync ♻️¶
When you invoke a function synchronously, Lambda runs the function and waits for a response. When the function completes, Lambda returns the response from the function's code with additional data, such as the version of the function that was invoked. Synchronous events expect an immediate response from the function invocation.
Remember
With this model, there are no built-in retries. You must manage your retry strategy within your application code.
ASync ⛰️¶
When you invoke a function asynchronously, events are queued and the requestor doesn't wait for the function to complete. This model is appropriate when the client doesn't need an immediate response. With the asynchronous model, you can make use of destinations.
Polling 📊¶
With this type of integration, AWS will manage the poller on your behalf and perform synchronous invocations of your function.
Tip
With this model, the retry behavior varies depending on the event source and its configuration.
Event ☄️¶
An event is a JSON-formatted document that contains data for a Lambda function to process. The runtime converts the event to an object and passes it to your function code. When you invoke a function, you determine the structure and contents of the event.
{
"TemperatureK": 281,
"WindKmh": -3,
"HumidityPct": 0.55,
"PressureHPa": 1020
}
When an AWS service invokes your function, the service defines the shape of the event.
{
"Records": [
{
"Sns": {
"Timestamp": "2019-01-02T12:45:07.000Z",
"Signature": "tcc6faL2yUC6dgZdmrwh1Y4cGa/ebXEkAi6RibDsvpi+tE/1+82j...65r==",
"MessageId": "95df01b4-ee98-5cb9-9903-4c221d41eb5e",
"Message": "Hello from SNS!",
...
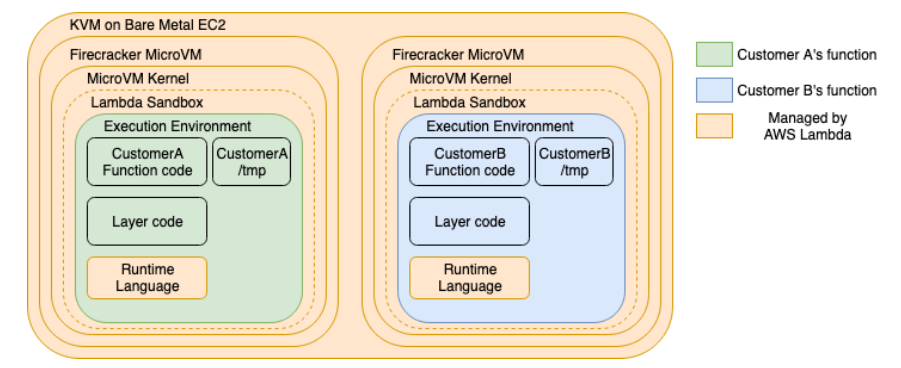
Execution environment ⚙️¶
An execution environment provides a secure and isolated runtime environment for your Lambda function. An execution environment manages the processes and resources that are required to run the function.
How execution env is setup?
When you create your Lambda function, you specify configuration information, such as the amount of available memory and the maximum invocation time allowed for your function. Lambda uses this information to set up the execution environment.
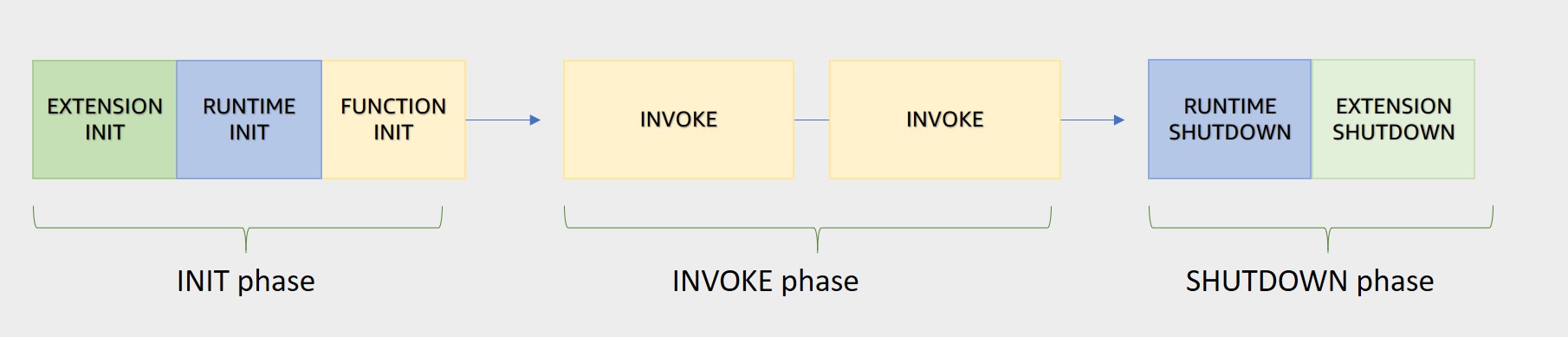
- Init Phase: In this phase, Lambda creates or unfreezes an execution environment with the configured resources, downloads the code for the function and all layers, initializes any extensions, initializes the runtime, and then runs the function’s initialization code (the code outside the main handler).
- Invoke Phase: In this phase, Lambda invokes the function handler. After the function runs to completion, Lambda prepares to handle another function invocation.
- Shutdown Phase: If the Lambda function does not receive any invocations for a period of time, this phase initiates. In the Shutdown phase, Lambda shuts down the runtime, alerts the extensions to let them stop cleanly, and then removes the environment. Lambda sends a shutdown event to each extension, which tells the extension that the environment is about to be shut down.
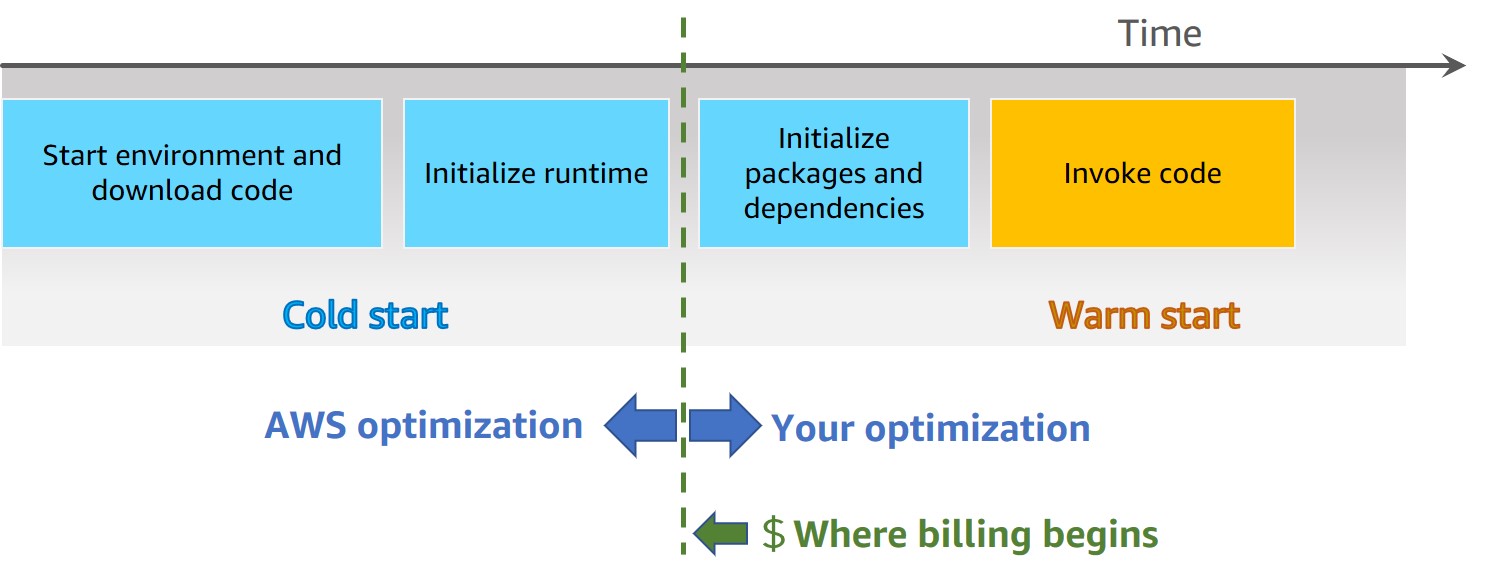
Cold Start and Warm Start ☃️¶
Cold Start: A cold start occurs when a new execution environment is required to run a Lambda functionWarm Start: In a warm start, the Lambda service retains the environment instead of destroying it immediately. This allows the function to run again within the same execution environment. This saves time by not needing to initialize the environment.
Policies 👮¶
Execution role 🙆♂️¶
The execution role gives your function permissions to interact with other services. You provide this role when you create a function, and Lambda assumes the role when your function is invoked. The policy for this role defines the actions the role is allowed to take — for example, writing to a DynamoDB table.

The role must include a trust policy that allows Lambda to “AssumeRole” so that it can take that action for another service.
What is trust policy
A trust policy defines what actions your role can assume. The trust policy allows Lambda to use the role's permissions by giving the service principal lambda.amazonaws.com permission to call the AWS Security Token Service (AWS STS) AssumeRole action.
This example illustrates that the principal "Service":"lambda.amazonaws.com" can take the "Action":"sts:AssumeRole" allowing Lambda to assume the role and invoke the function on your behalf.
IAM resource policy¶
A resource policy (also called a function policy) tells the Lambda service which principals have permission to invoke the Lambda function. An AWS principal may be a user, role, another AWS service, or another AWS account.
Instruction set architecture¶
The instruction set architecture determines the type of computer processor that Lambda uses to run the function. Lambda provides a choice of instruction set architectures:
-
arm64– 64-bit ARM architecture, for the AWS Graviton2 processor. -
x86_64– 64-bit x86 architecture, for x86-based processors.
Deployment package 📦¶
You deploy your Lambda function code using a deployment package. Lambda supports two types of deployment packages:
-
A .zip file archive that contains your function code and its dependencies. Lambda provides the operating system and runtime for your function.
-
A container image that is compatible with the
Open Container Initiative (OCI)specification. You add your function code and dependencies to the image. You must also include the operating system and a Lambda runtime.
Runtime ⏰¶
The runtime provides a language-specific environment that runs in an execution environment. The runtime relays invocation events, context information, and responses between Lambda and the function. You can use runtimes that Lambda provides, or build your own. If you package your code as a .zip file archive, you must configure your function to use a runtime that matches your programming language. For a container image, you include the runtime when you build the image.
Layer 📚¶
A Lambda layer is a .zip file archive that can contain additional code or other content. A layer can contain libraries, a custom runtime, data, or configuration files.
Remember
Layers provide a convenient way to package libraries and other dependencies that you can use with your Lambda functions. Using layers reduces the size of uploaded deployment archives and makes it faster to deploy your code. Layers also promote code sharing and separation of responsibilities so that you can iterate faster on writing business logic.
You can include up to five layers per function. Layers count towards the standard Lambda deployment size quotas. When you include a layer in a function, the contents are extracted to the /opt directory in the execution environment.
By default, the layers that you create are private to your AWS account. You can choose to share a layer with other accounts or to make the layer public. If your functions consume a layer that a different account published, your functions can continue to use the layer version after it has been deleted, or after your permission to access the layer is revoked. However, you cannot create a new function or update functions using a deleted layer version.
Tldr
Functions deployed as a container image do not use layers. Instead, you package your preferred runtime, libraries, and other dependencies into the container image when you build the image.
Destination 🗻¶
Destinations are AWS resources that receive a record of an invocation after success or failure. You can configure Lambda to send invocation records when your function is invoked asynchronously, or if your function processes records from a stream. The contents of the invocation record and supported destination services vary by source.
Extension¶
Lambda extensions enable you to augment your functions. For example, you can use extensions to integrate your functions with your preferred monitoring, observability, security, and governance tools.
Concurrency¶
Concurrency is the number of requests that your function is serving at any given time. When your function is invoked, Lambda provisions an instance of it to process the event. When the function code finishes running, it can handle another request. If the function is invoked again while a request is still being processed, another instance is provisioned, increasing the function's concurrency.
Throtlling ⚠️¶
what is Throtlling?
At the highest level, throttling just means that Lambda will intentionally reject one of your requests and so what we see from the user side is that when making a client call, Lambda will throw a throttling exception, which you need to handle. Typically, people handle this by backing off for some time and retrying. But there are also some different mechanisms that you can use, so that’s interesting, Lambda will reject your request.
Why does it occur?
Throttling occurs when your concurrent execution count > concurrency limit.
Now, just as a reminder, if this wasn’t clear, Lambda can handle multiple instance invocations at the same time and the sum of all of those invocations amounts to your concurrency execution count. So, assume we’re at a particular instant in time if you have more invocations that are running that exceed your configured limit, all new requests to your Lambda function will get a throttling exception.
What are the configure limits?
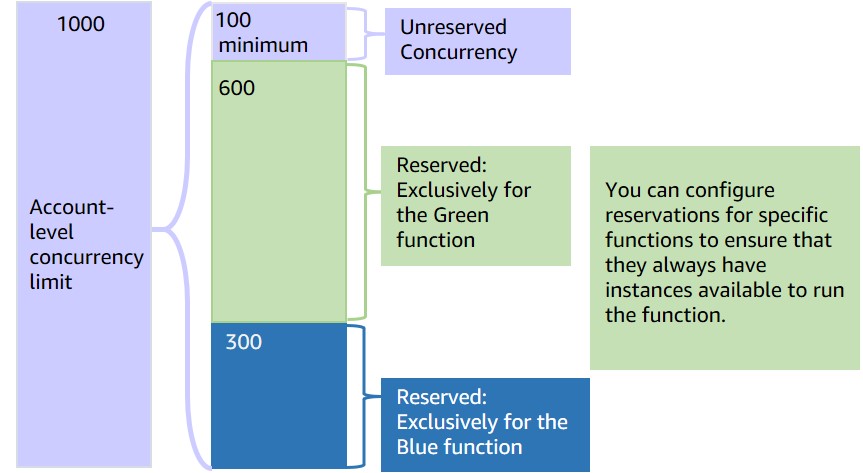
Lambda has a default 1000 concurrency limit that’s specified per region within an account. But it does get a little bit more complicated in terms of how this rule applies when you have multiple Lambda functions in the same region and the same account.
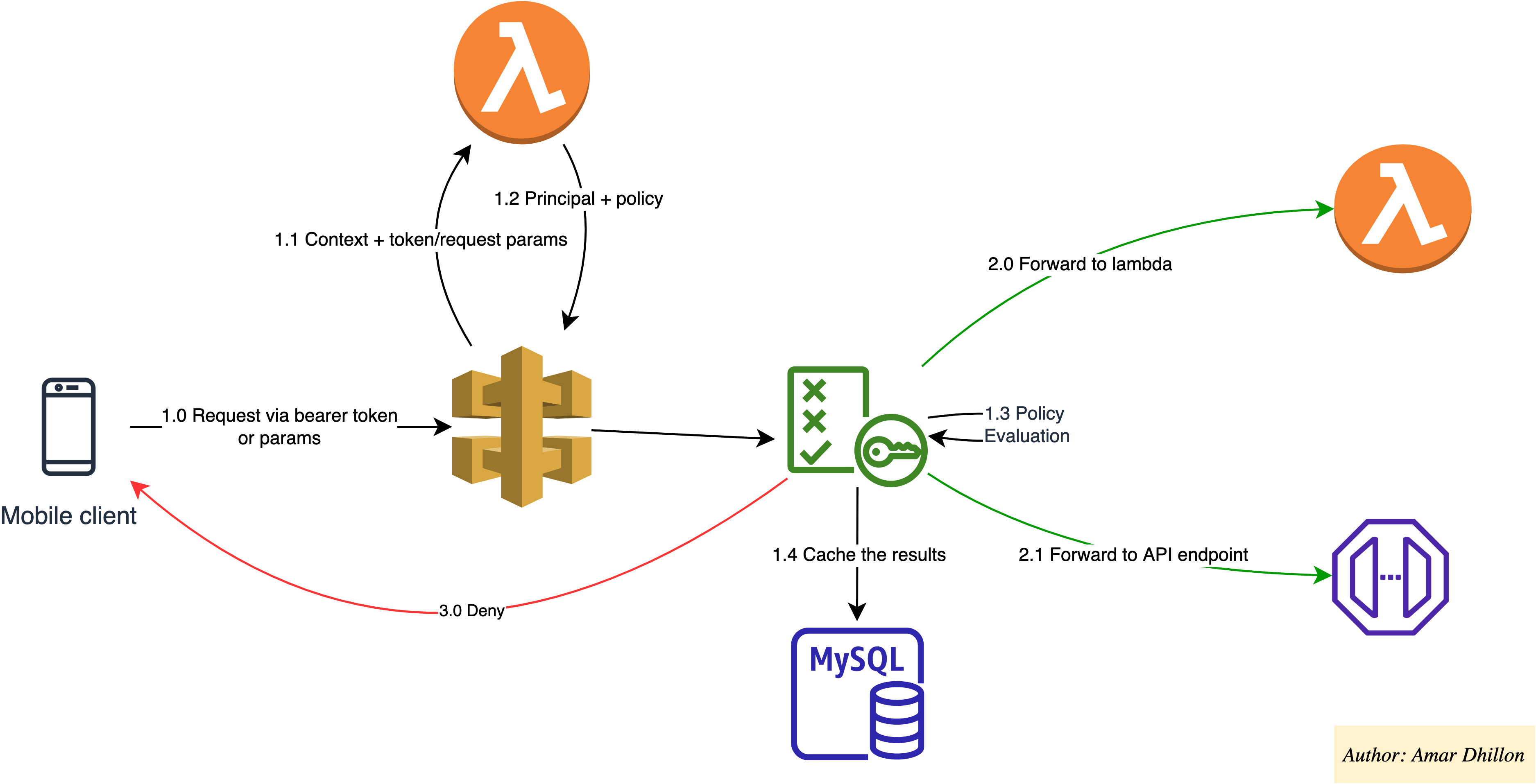
Authentication in Lambda 🔑¶
We have 3 options:
Use Cognito¶
As an alternative to using IAM roles and policies or Lambda authorizers (formerly known as custom authorizers), you can use an Amazon Cognito user pool to control who can access your API in Amazon API Gateway.
Use IAM¶
IAM is best for clients that are within your AWS environment or can otherwise retrieve IAM temporary credentials to access your environment.
Use Custom Authorizer¶
Use this when you are using other IDP such as AAD
Function URL 🔗¶
A function URL is a dedicated HTTP(S) endpoint for your Lambda function. You can create and configure a function URL through the Lambda console or the Lambda API. When you create a function URL, Lambda automatically generates a unique URL endpoint for you. Once you create a function URL, its URL endpoint never changes. Function URL endpoints have the following format:
https://<url-id>.lambda-url.<region>.on.aws
Info
Function URLs are dual stack-enabled, supporting IPv4 and IPv6.
Code editor¶
The code editor supports languages that do not require compiling, such as Node.js and Python. The code editor suppports only .zip archive deployment packages, and the size of the deployment package must be less than 3 MB.
Lambda and Private Link¶
- To establish a private connection between your VPC and Lambda, create an interface VPC endpoint.
- Interface endpoints are powered by
AWS PrivateLink, which enables you to privately access Lambda APIs without an internet gateway, NAT device, VPN connection, or AWS Direct Connect connection.
State Store (not Data Store) 🗳️¶
No information about state should be saved within the context of the function itself. Because your functions only exist when there is work to be done, it is particularly important for serverless applications to treat each function as stateless.
Consider one of the following options for storing state data:
-
Amazon DynamoDBis serverless and scales horizontally to handle your Lambda invocations. It also has single-millisecond latency, which makes it a great choice for storing state information. -
Amazon ElastiCachemay be less expensive thanDynamoDBif you have to put your Lambda function in a VPC. -
Amazon S3can be used as an inexpensive way to store state data if throughput is not critical and the type of state data you are saving will not change rapidly.
AWS SAM 🧙♀️¶
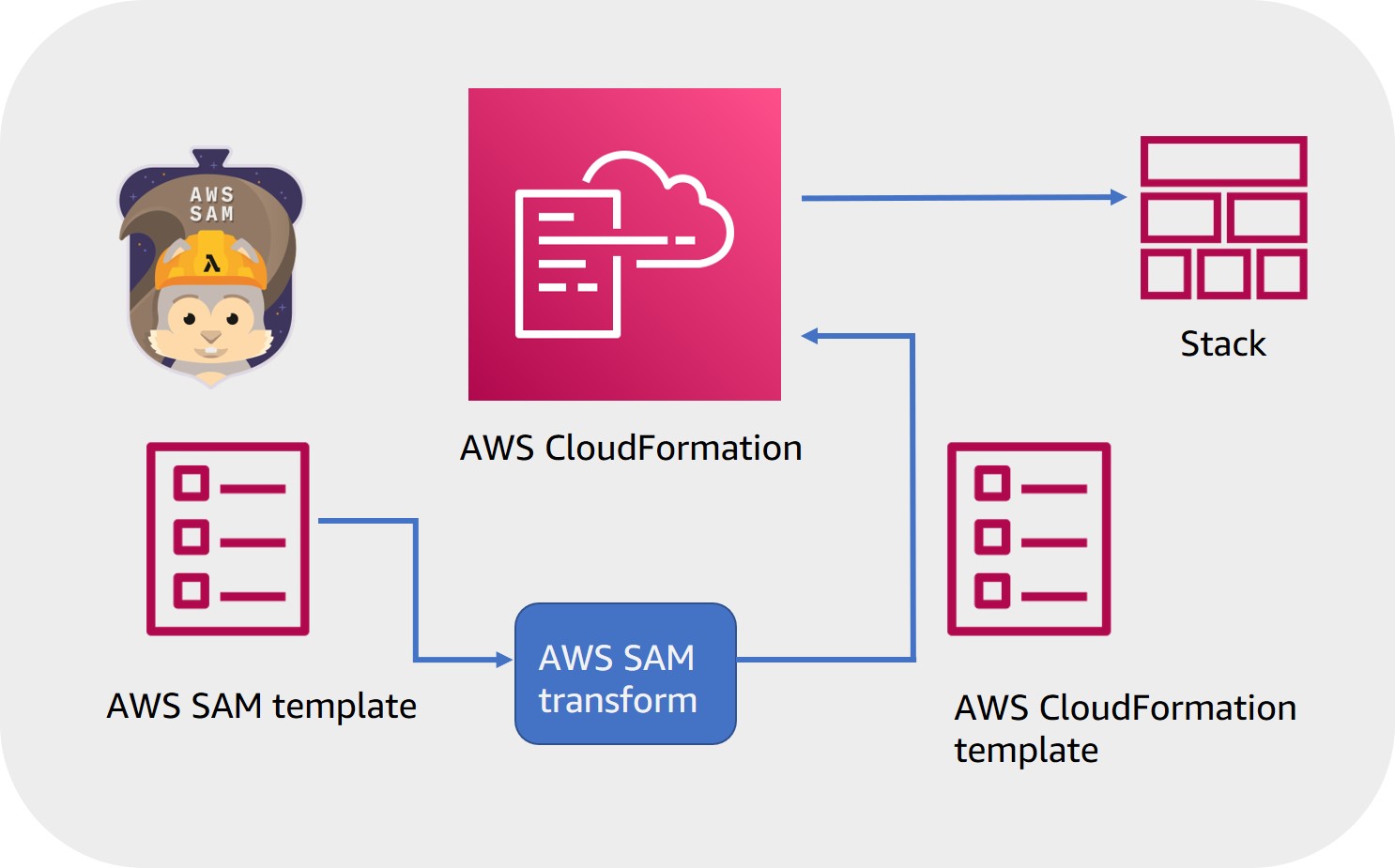
AWS SAM is an open-source framework for building serverless applications. It provides shorthand syntax to express functions, APIs, databases, and event source mappings. With just a few lines per resource, you can define the application you want and model it using YAML.
You provide AWS SAM with simplified instructions for your environment and during deployment AWS SAM transforms and expands the AWS SAM syntax into AWS CloudFormation syntax (a fully detailed CloudFormation template)
Testing made easy with SAM
AWS SAM CLI launches a Docker container that you can interact with to test and debug your Lambda function code before deploying to the cloud.With AWS SAM CLI for testing, you can do the following:
- Invoke functions and run automated tests locally.
- Generate sample event source payloads.
- Run API Gateway locally.
- Debug code.
- Review Lambda function logs.
- Validate AWS SAM templates.
Deploy using SAM¶
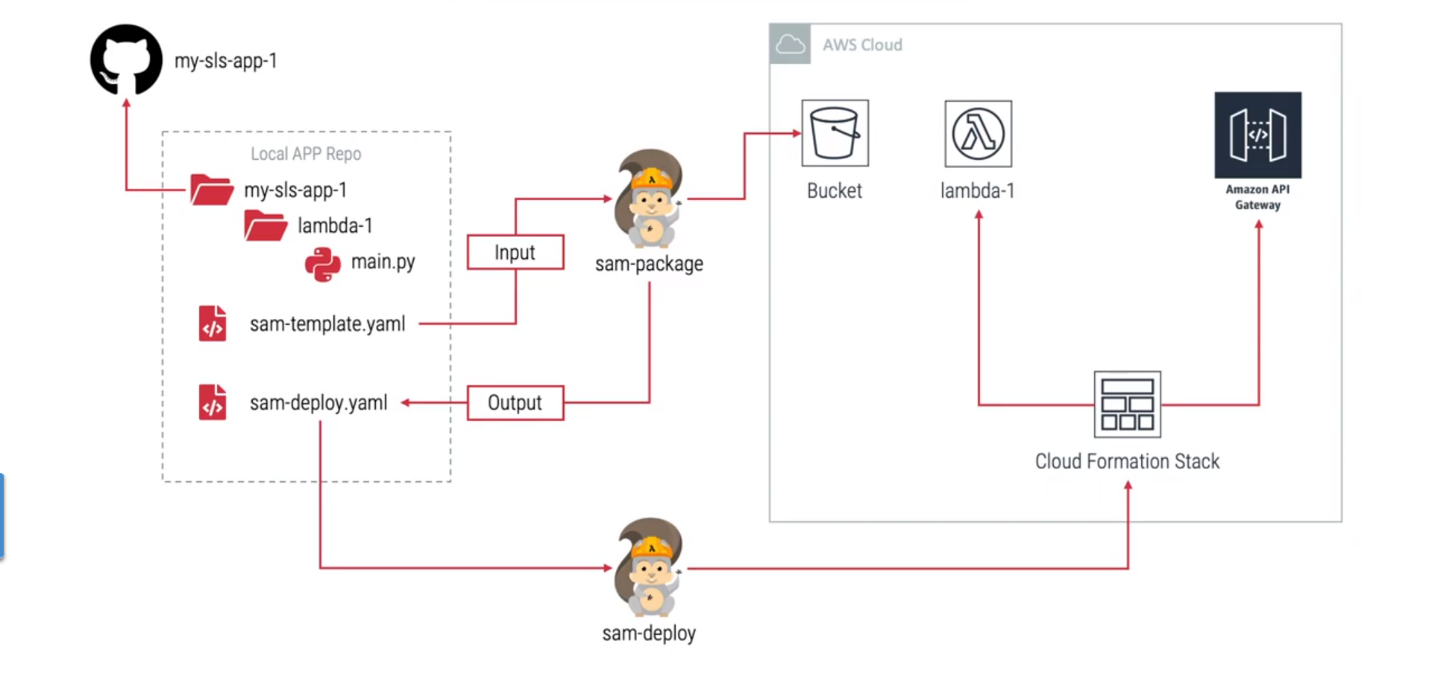
- You begin by writing your Lambda function code and defining all of your serverless resources inside an AWS SAM template.
- You can use the SAM CLI to emulate the Lambda environment and perform local tests on your Lambda functions.
- After the code and templates are validated, you can then use the SAM package command to create a deployment package, which is essentially a
.zip filethat SAM stores in Amazon S3. - After that, the SAM deploy command instructs AWS CloudFormation to deploy the .zip file to create resources inside of your AWS console.
Pricing 🤑¶
Price depends on the amount of memory you allocate to your function, not the amount of memory your function uses. If you allocate 10 GB to a function and the function only uses 2 GB, you are charged for the 10 GB. This is another reason to test your functions using different memory allocations to determine which is the most beneficial for the function and your budget.
Lambda Monitoring 📊¶
Cloud Watch ⌚️¶
AWS Lambda automatically monitors Lambda functions on your behalf and reports metrics through Amazon CloudWatch. To help you monitor your code when it runs, Lambda automatically tracks the following:
- Number of requests: The number of times your function code is run, including successful runs and runs that result in a function error. If the invocation request is throttled or otherwise resulted in an invocation error, invocations aren't recorded.
- Invocation duration per request
- Number of requests that result in an error
Xray 🦴¶
You can use X-Ray for: - Tuning performance - Identifying the call flow of Lambda functions and API calls - Tracing path and timing of an invocation to locate bottlenecks and failures
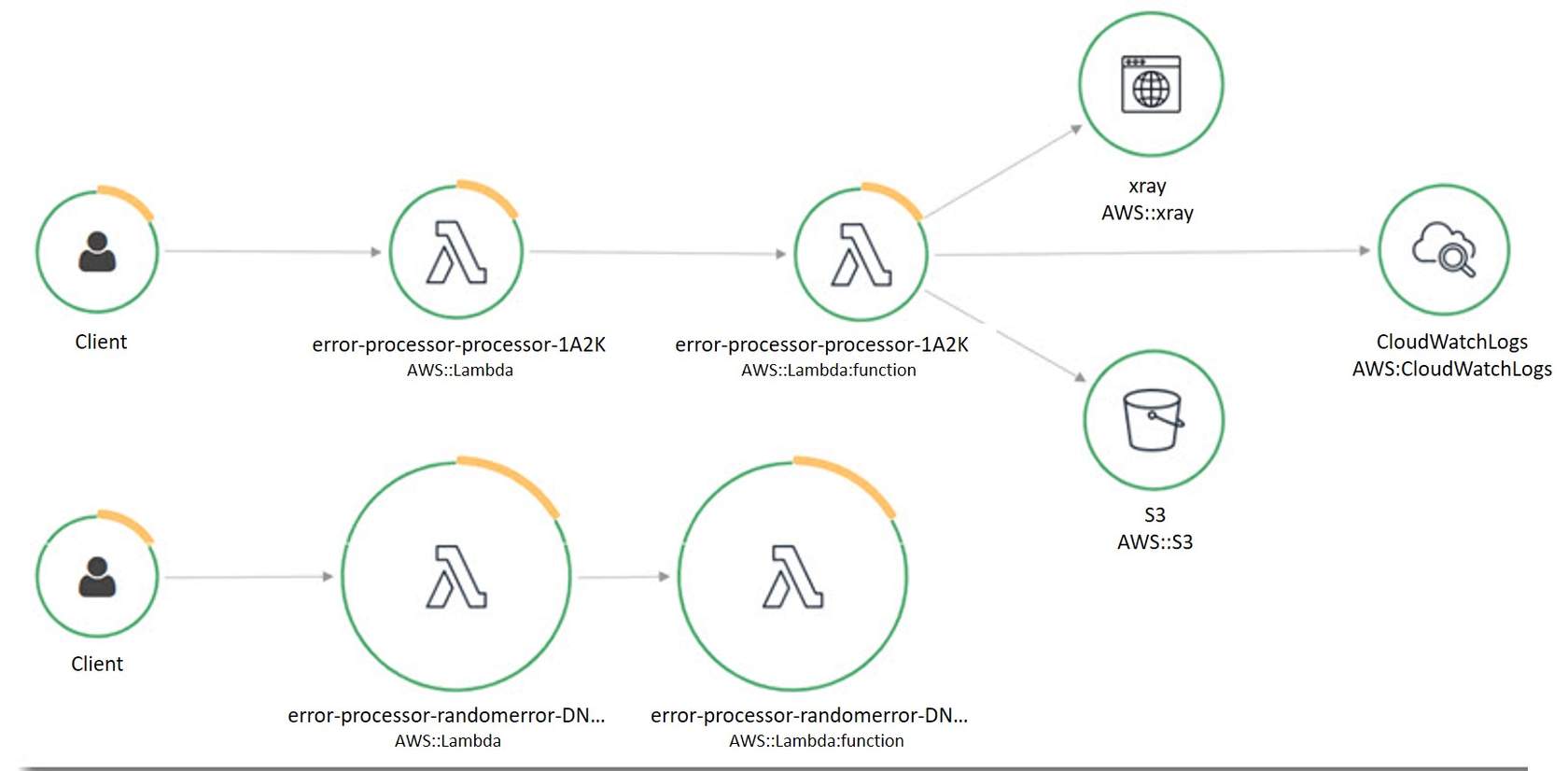
DLQ ☠️¶
Dead-letter queues (DLQ) help you capture application errors that must receive a response, such as an ecommerce application that processes orders. If an order fails, you cannot ignore that order error. You move that error into the dead-letter queue and manually look at the queue and fix the problems.
Performance tuning ⚙️¶
Concurrency limits 📈¶
Account concurrency limits are in place to help avoid unexpected consequences if you have a "function gone wild" scenario. For example, a runaway function could incur very high costs, and impact the performance of downstream resources.
You can also set function concurrency limits to reserve a part of your account limit pool for a function. You might do this to guarantee concurrency availability for a function, or to avoid overwhelming a downstream resource that your function is interacting with.
Competing functions
If your test results uncover situations where functions from different applications or different environments are competing with each other for concurrency, you probably need to rethink your account segregation strategy and consider moving to a multi-account strategy. You don’t want to end up with a non-production function impacting production functions because they’re in the same account.
Memory config¶
When you configure functions, there is only one setting that can impact performance—memory. However, both CPU and I/O scale linearly with memory configuration. For example, a function with 256 MB of memory has twice the CPU and I/O as a 128 MB function.
Memory assignment will impact how long your function runs and, at a larger scale, can impact when functions are throttled.
Alias¶
- A Lambda alias is a pointer to a specific function version.
- By default, an alias points to a single Lambda version.
- When the alias is updated to point to a different function version, all incoming request traffic will be redirected to the updated Lambda function version.
