DB, DW, Data Lakes, Data Lakehouse ¶
Databases¶
Databases are for OLTP (operational needs). In OLTP, the emphasis is on fast processing, because OLTP databases are read, written, and updated frequently.
Characterstics of OLTP
- We need
Normalized databasesfor efficiency - Some OLTP examples are credit card activity, order entry, and ATM transactions.
Data Warehouses¶
- Data Warehouses are for OLAP (Informational needs)
- OLAP applies complex queries to large amounts of historical data, aggregated from OLTP databases and other sources, for data mining, analytics, and business intelligence projects.
- In OLAP, the emphasis is on response time to these complex queries. Each query involves one or more columns of data aggregated from many rows.
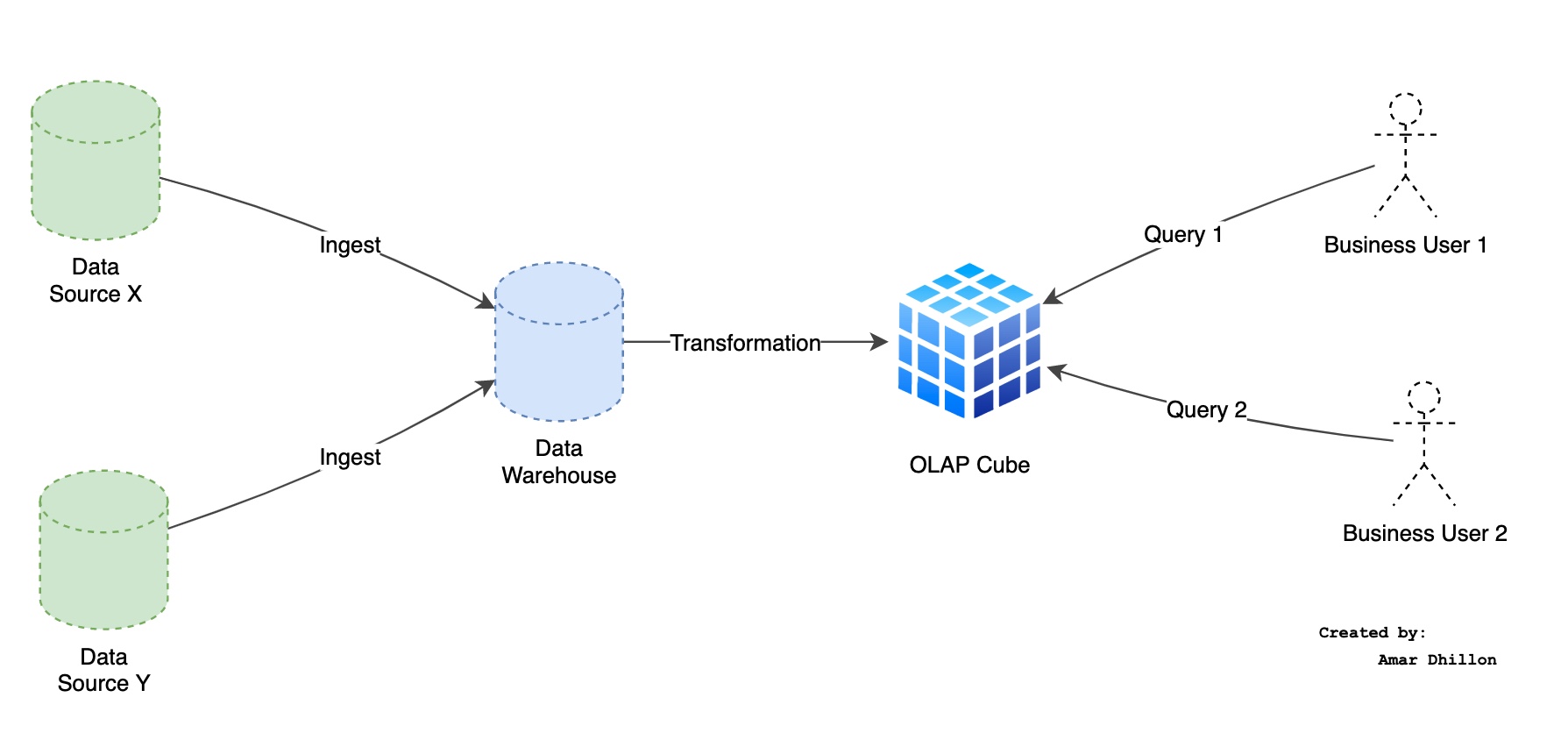
Data warehousing helps you answer those tough analytical questions that your board may be asking that aren’t possible to address with your standard data analytics tool.
Characterstics of OLAP
- OLAP is a read heavy system
- Data is non-volatile as it wont be changes often.
- OLAP is used on data warehouse or some other centralized data store.
- Data periodically refreshed with scheduled, long-running batch jobs
- For backup: Lost data can be reloaded from OLTP database as needed in lieu of regular backups.
- Denormalized databases for analysis (most data warehouses favor denormalized data models, where each table contains as many related attributes as possible. In this way, all the information can be processed by a single pass through the data.)
- An OLAP database uses a multidimensional data model, which includes features of relational, navigational, and hierarchical databases. It also consists of an OLAP cube which consists of multiple types of data.
Unlike a database, the information isn’t updated in real-time and is better for data analysis of broader trends.
Data Lake¶
Data lake is for storing any and all raw data that may or may not yet have an intended use case. A data warehouse, on the other hand, holds data that has already been processed and filtered, so it’s ready to be used and analyzed.
Data LakeHouse¶
A data lakehouse is an open data management architecture that combines the flexibility and cost-efficiency of data lakes with the data management and structure features of data warehouses, all on one data platform.
Simply put: The data lakehouse is the only data architecture that stores all data — unstructured, semi-structured, AND structured — in your data lake while still providing the data quality and data governance standards of a data warehouse.
How to create OLAP view from OLTP?¶
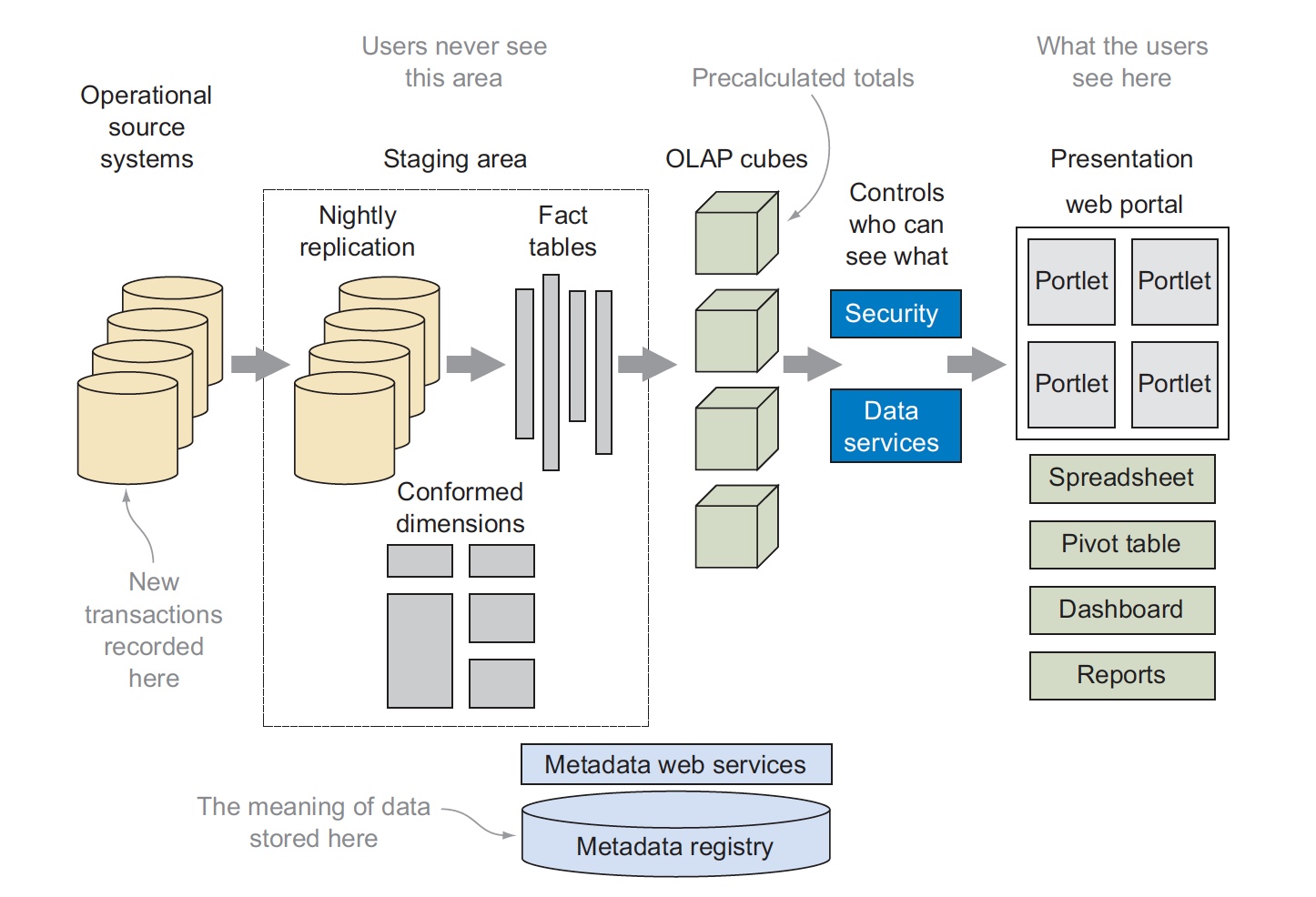
- In the first step, new transactions are copied from the operational source systems and loaded into a temporary staging area.
- Data in the staging area is then transformed to create fact and dimension tables that are used to build OLAP cube structures.
- These cubes contain precalculated aggregate structures that contain summary information which must be updated as new facts are added to the fact tables.
- The information in the OLAP cubes is then accessed from a graphical front-end tool through the security and data services layers.
- The precise meaning of data in any part of the system is stored in a separate metadata registry database that ensures data is used and interpreted consistently despite the many layers of transformation.
Issues in moving data
The ETL tools to move data between operational and analytical systems still usually run on single processors, perform costly join operations, and limit the amount of data that can be moved each night between the operational and analytical systems. These challenges and costs are even greater when organizations lack strong data governance policies or have inconsistent category definitions
OLAP Concepts¶
Fact table¶
A central table of events that contains foreign keys to other tables and integer and decimal values called measures.
Dimension table¶
A table used to categorize every fact. Examples of dimensions include time, geography, product, or promotion.
Star schema¶
An arrangement of tables with one fact table surrounded by dimension tables. Each transaction isrepresented by a single row in the central fact table.
Categories¶
A way to divide all the facts into two or more classes. For example, products may have a Seasonal category indicating they’re only stocked part of the year.
Measures¶
A number used in a column of a fact table that you can sum or average. Measures are usually things like sales counts or prices.
Aggregates¶
Precomputed sums used by OLAP systems to quickly display results to users.
Data warehouse performance reasons 🤔¶
We will take Amazon Redshift as an example.
Info
Amazon Redshift is a column-oriented, fully managed, petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data using your existing business intelligence tools.
MPP¶
Massively parallel processing (MPP) enables fast run of the most complex queries operating on large amounts of data. Multiple compute nodes handle all query processing leading up to final result aggregation, with each core of each node running the same compiled query segments on portions of the entire data.
Columnar data storage¶
Storing database table information in a columnar fashion reduces the number of disk I/O requests and reduces the amount of data you need to load from disk.
Data compression¶
Because columnar storage stores similar data sequentially, Amazon Redshift is able to apply adaptive compression encodings specifically tied to columnar data types
Query optimizer¶
The Amazon Redshift query run engine incorporates a query optimizer that is MPP-aware and also takes advantage of the columnar-oriented data storage.
Results Caching¶
To reduce query runtime and improve system performance, Amazon Redshift caches the results of certain types of queries in memory on the leader node. When a user submits a query, Amazon Redshift checks the results cache for a valid, cached copy of the query results. If a match is found in the result cache, Amazon Redshift uses the cached results and doesn't run the query. Result caching is transparent to the user.
No SQL data patterns¶
Key-value¶
At its core, S3 is a simple key-value store with some enhanced features such as metadata and access control
- A key-value store is a simple database that when presented with a simple string (the key) returns an arbitrary large BLOB of data (the value).
- Key-value stores have no query language; they provide a way to add and remove key-value pairs (a combination of key and value where the key is bound to the value until a new value is assigned) into/from a database.
- The dictionary is a simple key-value store where word entries represent keys and definitions represent values.
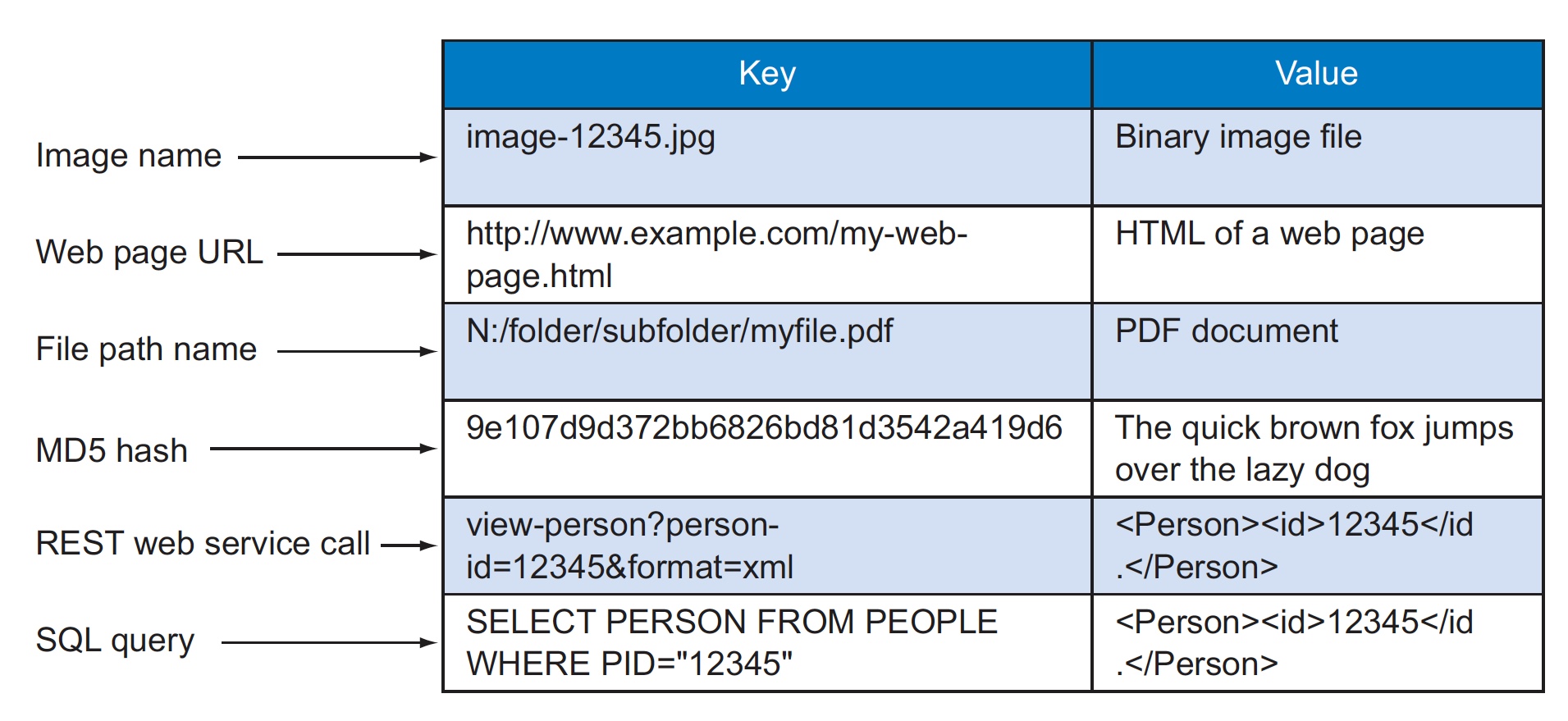
Various operations on Key value are
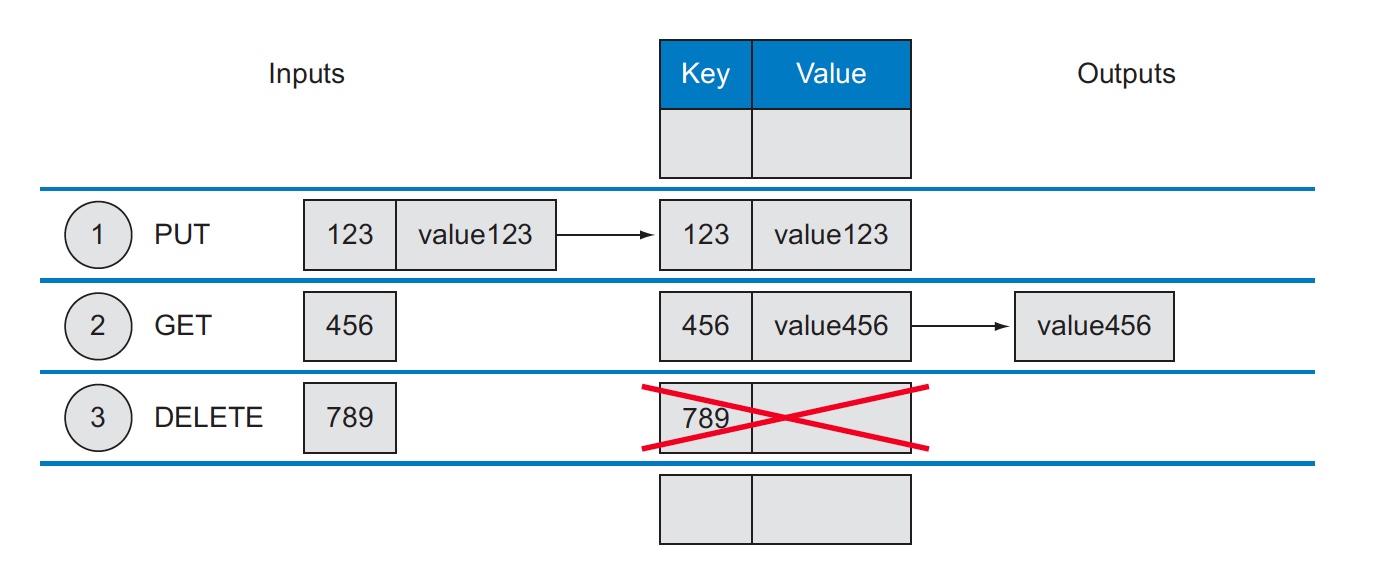
One of the benefits of not specifying a data type for the value of a key-value store is that you can store any data type that you want in the value. The system will store the information as a BLOB and return the same BLOB when a GET (retrieval) request is made. It’s up to the application to determine what type of data is being used, such as a string, XML file, or binary image.
Document store¶
Column Family¶
Examples:
- Cassandra
- PostgreSQL
- HBase
- Google BigTable
- Amazon Redshift: Amazon Redshift is based on PostgreSQL.
While a relational database is optimized for storing rows of data, typically for transactional applications, a columnar database is optimized for fast retrieval of columns of data, typically in analytical applications.
Remember
Column-oriented storage for database tables is an important factor in analytic query performance because it drastically reduces the overall disk I/O requirements and reduces the amount of data you need to load from disk.
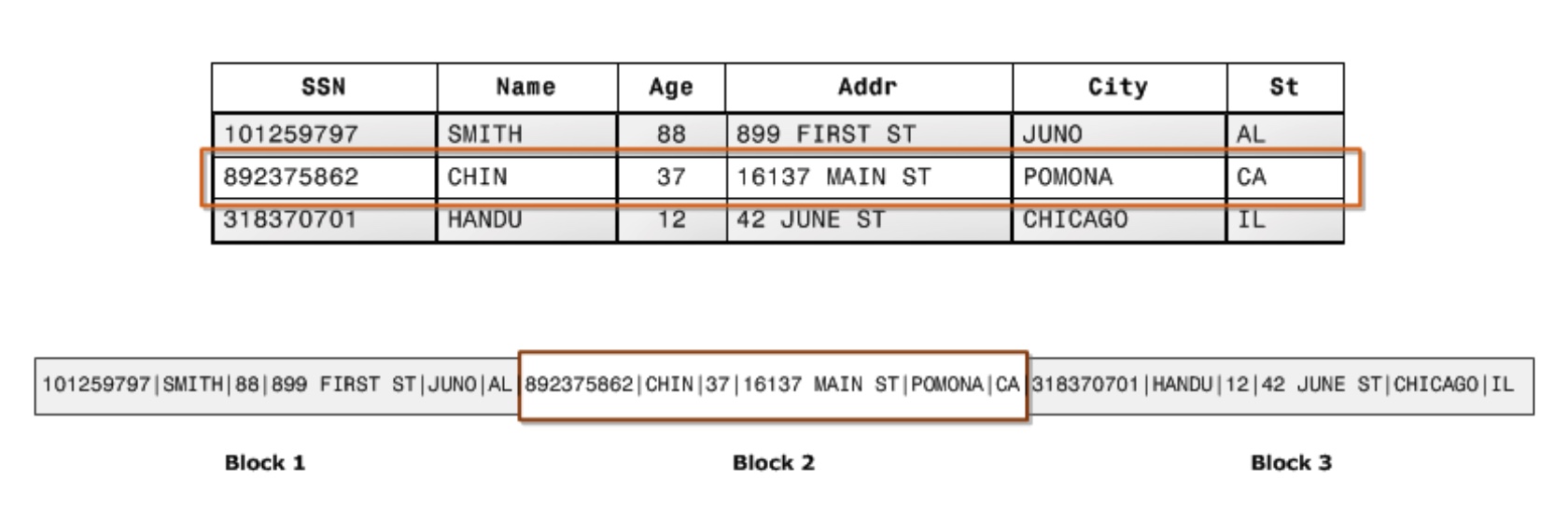
This is how data is stored for RDBMS in disk (sectors and blocks)
Data storage pattern for columnar family in disk
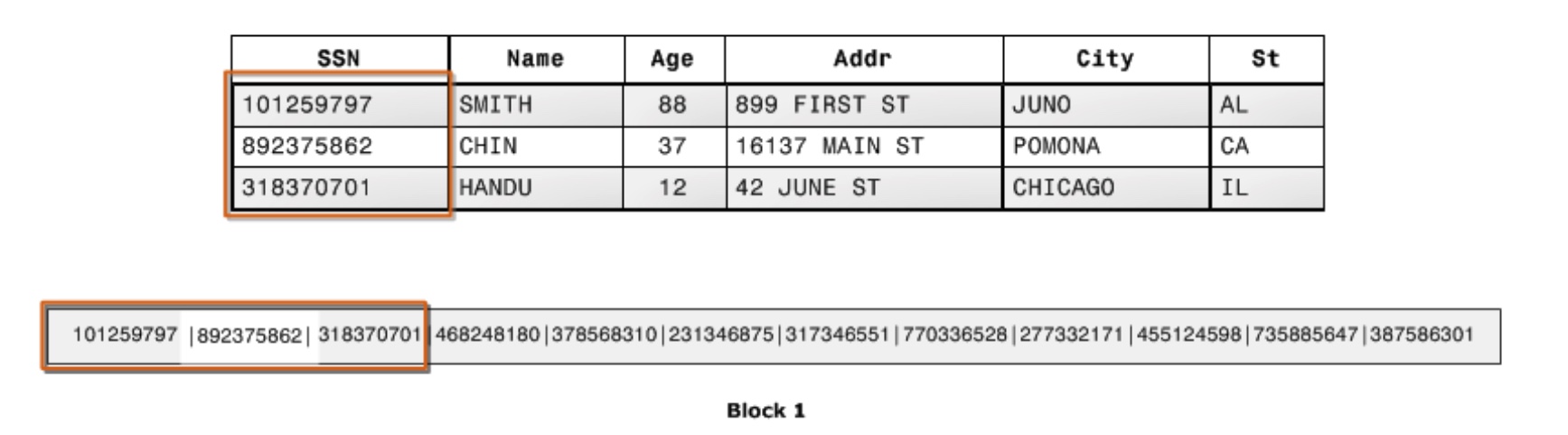
An added advantage is that, since each block holds the same type of data, block data can use a compression scheme selected specifically for the column data type, further reducing disk space and I/O.
Graph DB¶
A graph store is a system that contains a sequence of nodes and relationships that, when combined, create a graph. You know that in a key-value store there two data fields: the key and the value. In contrast, a graph store has three data fields: nodes, relationships, and properties.