Dynamo DB ¶
Amazon DynamoDB is a serverless, NoSQL, fully managed database with single-digit millisecond performance at any scale.
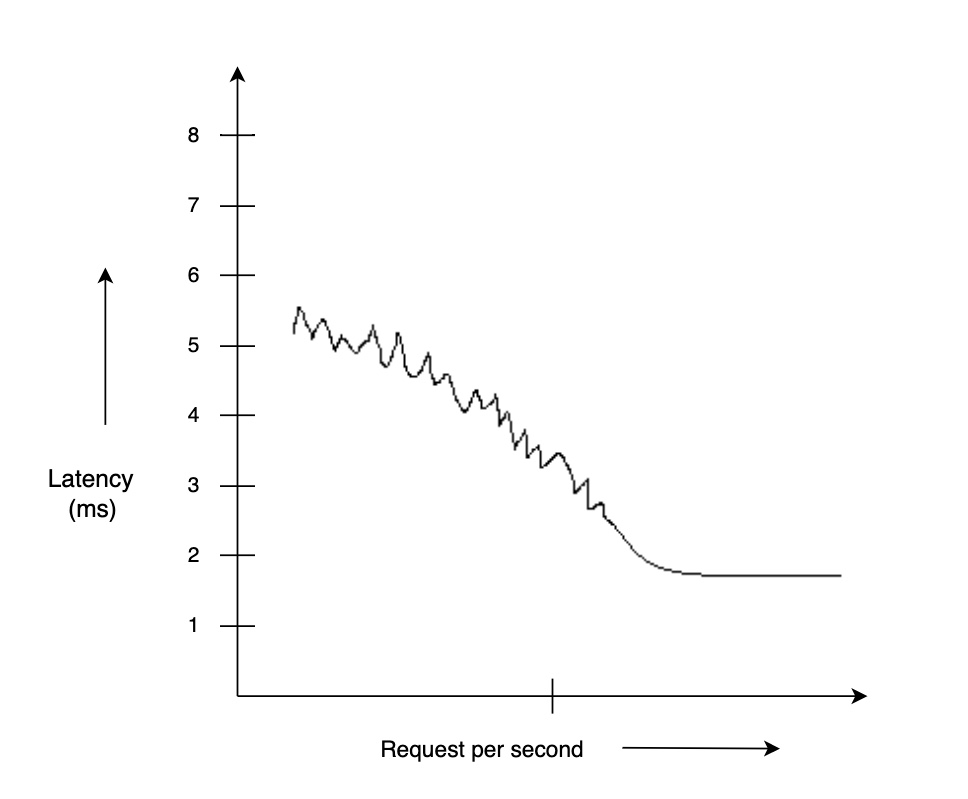
DynamoDB is a database that supports key-value and document-based table design. It is fully-managed and provides high performance at scale. Interestingly, its performance improves with scale
Schema¶
The only schema constraint you have when inserting an item in a table is that the item should have a unique primary key. As long as we provide a unique primary key, we can insert whatever data we want to insert.
Scaling 📈¶
It works better on large scale due to consistent hashing.
You can choose on-demand or provisioned mode, depending on how predictable your capacity needs are.
-
On demand: When you choose
on-demand mode, your tables automatically scale read and write throughput based on each prior peak. On-demand capacity instantly handles up to double the previous traffic peak on a table and will then use the latest peak as the baseline from which it can instantly double capacity for the next peak.Warning
If you get a new peak that is more than double the previous, DynamoDB will still give you more capacity, but your requests could get throttled if you exceed double your previous peak within 30 minutes.
-
Provisioned: If you choose
provisioned modefor your DynamoDB tables, you specify capacity in terms ofread capacity units (RCU)andwrite capacity units (WCU). Provisioned throughput is the maximum amount of capacity the table can consume. If you exceed this in a table or index, requests will get throttled. Throttled requests will return an error, and the AWS SDK has built in support for retries and exponential backoff.
You can use auto scaling with provisioned capacity to define lower and upper capacity limits and target a utilization percentage within the range. DynamoDB auto scaling will work to maintain the target utilization as the workload increases or decreases. You can set the target between 20 and 90 percent. With auto scaling, a table will increase its read and write capacity to handle sudden increases in traffic without getting throttled.
Which one to choose?
On-demand is a really great fit for serverless applications because you don’t have to worry about provisioning any capacity. You pay a set amount for each read and write. This simplifies evaluating the cost of a transaction, because the cost is directly reflected in the reads and writes performed by that transaction.
Provisioned capacity may be the better choice if you have a very consistent, predictable workload. With provisioned capacity you are paying a set rate for the amount of read and write capacity you have provisioned.
DAX ⏩¶
If your application is really read heavy and requires even lower latency than DynamoDB offers, you can add Amazon DynamoDB Accelerator, called DAX.
DAX is an in-memory cache. Things like real-time bidding, social gaming, and trading applications are good candidates for using DAX.
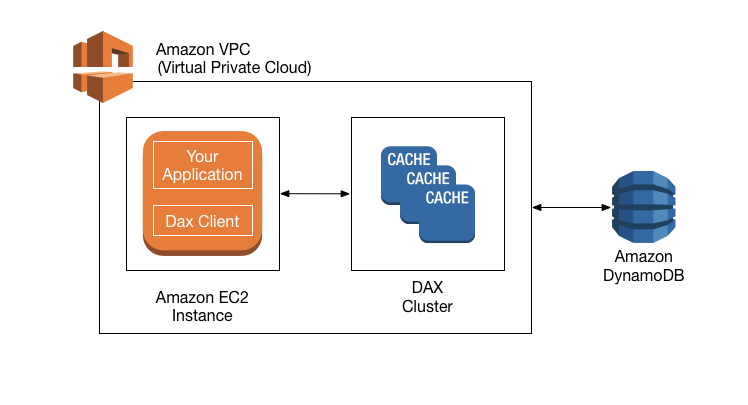
How DAX processes requests?
A DAX cluster consists of one or more nodes. Each node runs its own instance of the DAX caching software. One of the nodes serves as the primary node for the cluster. Additional nodes (if present) serve as read replicas. For more information, see Nodes.
Your application can access DAX by specifying the endpoint for the DAX cluster. The DAX client software works with the cluster endpoint to perform intelligent load balancing and routing. Read operations
DAX can respond to the following API calls:
- GetItem
- BatchGetItem
- Query
- Scan
If the request specifies eventually consistent reads (the default behavior), it tries to read the item from DAX:
-
If DAX has the item available (a cache hit), DAX returns the item to the application without accessing DynamoDB.
-
If DAX does not have the item available (a cache miss), DAX passes the request through to DynamoDB. When it receives the response from DynamoDB, DAX returns the results to the application. But it also writes the results to the cache on the primary node.
Change data capture ⚡️¶
DynamoDB supports streaming of item-level change data capture (CDC) records in near-real time.
It offers two streaming models for CDC: 1. DynamoDB Streams 2. Kinesis Data Streams for DynamoDB.
Whenever an application creates, updates, or deletes items in a table, streams records a time-ordered sequence of every item-level change in near-real time. This makes DynamoDB Streams ideal for applications with event-driven architecture to consume and act upon the changes.
Partitioning/Re-partitioning 🎬¶
AS we know that data is horizontally scaled across multiple servers in Dynamo. This means that the data needs to be partitioned. Also, servers are added and removed all the time, which means that they have to be re-partitioned frequently. You don’t have to worry about that this either, since the partitioning and repartitioning processes are managed by AWS without downtime.
Storing large files in Dynamo
Although we can save up to 400 KB of data in one item, if we are trying to save larger files in DynamoDB, we will be at a loss in terms of cost. It would be better for us to use AWS S3 to store the files and have links to the files in our database 😄
Tip
DynamoDb is running on SSD and have minimum of 3 instances.
Secondary Indexes 📇¶
DynamoDB offers the option to create both global and local secondary indexes, which let you query the table data using an alternate key. With these secondary indexes, you can access data with attributes other than the primary key, giving you maximum flexibility in accessing your data.
Global Tables 🌍¶
DynamoDB global tables enable a 99.999% availability SLA and multi-Region resilience. This helps you build resilient applications and optimize them for the lowest recovery time objective (RTO) and recovery point objective (RPO).
Global tables also integrates with AWS Fault Injection Service (AWS FIS) to perform fault injection experiments on your global table workloads.
Access Patterns 🔐¶
As mentioned earlier in this guide, you can choose from three access patterns to perform create, read, update, and delete (CRUD) operations on DynamoDB tables:
- Object persistence interface
- Document interfaces
- Low-level API interface
Dynamo Data Model 𝌭¶
Items 🔠¶
Items in DynamoDB are similar to the rows in relational databases. An item belongs to a table and can contain multiple attributes. An item in DynamoDB can also be represented as a JSON object (a collection of key-value pairs).
Attributes 🎛️¶
Each individual key-value pair of an item is known as an attribute. An item is built from multiple attributes. We can think of attributes as the properties of the item when we think of the item as a JSON object. Values of attributes can have many scalar and composite data types
Primary key 🔑¶
Each table in DynamoDB contains a primary key. A primary key is a special set of attributes. Its value is unique for every item and is used to identify the item in the database. Under the hood, it is used to partition and store the data in order.
There are two types of primary keys:
-
Partition key: Here, we have a unique key of scalar type (string, number, boolean), which determines the storage partition the item will go into. -
Partition key and Sort key: Here, we have two keys. The partition key determines the partition where the item goes into the storage and the sort key determines the rank of the item in the partition. Neither of these two keys need to be unique. However, their combination should be unique.
Dynamo DB Limitations ‼️ ♾️¶
There are a few limits you must understand to model properly in DynamoDB. If you're not aware of them, you can run into a brick wall 🧱. But if you understand them and account for them, you remove the element of surprise once your app hits production.
Those limits are:
- The item size limit:
- The page size limit for Query and Scan operations: It is about a collection of items that are read together in a single request
- The partition throughput limits: It is about the number and size of concurrent requests in a single DynamoDB partition.
Item Size Limit 📦¶
The first important limit to know is the item size limit. An individual record in DynamoDB is called an item, and a single DynamoDB item cannot exceed 400KB.
While 400KB is large enough for most normal database operations, it is significantly lower than the other options. MongoDB allows for documents to be 16MB, while Cassandra allows blobs of up to 2GB. And if you really want to get beefy, Postgres allows rows of up to 1.6TB (1600 columns X 1GB max per field)!
So what accounts for this limitation? DynamoDB is pointing you toward how you should model your data in an OLTP database.
Online transaction processing (or OLTP) systems are characterized by large amounts of small operations against a database. They describe most of how you interact with various services -- fetch a LinkedIn profile, show my Twitter timeline, or view my Gmail inbox. For these operations, you want to quickly and efficiently filter on specific fields to find the information you want, such as a username or a Tweet ID. OLTP databases often make use of indexes on certain fields to make lookups faster as well as holding recently-accessed data in RAM.
How to store large objects in Dynamo?
But if you have a large piece of data associated with your record, such as an image file, some user-submitted prose, or just a giant blob of JSON, it might not be best to store that directly in your database. You'll clog up the RAM and churn your disk I/O as you read and write that blob.
Put the blob in an object store instead. Amazon S3 is a cheap, reliable way to store blobs of data. Your database record can include a pointer to the object in S3, and you can load it out when it's needed. S3 has a better pricing model for reading and writing large blobs of data, and it won't put extra strain on your database.
Page size limit for Query & Scan 🖨️¶
While the first limit we discussed involved an individual item, the second limit involves a grouping of items.
DynamoDB has two APIs for fetching a range of items in a single request. The Query operation will fetch a range of items that have the same partition key, whereas the Scan operation will fetch a range of items from your entire table.
For both of these operations, there is a 1MB limit on the size of an individual request. If your Query parameters match more than 1MB of data or if you issue a Scan operation on a table that's larger than 1MB, your request will return the initial matching items plus a LastEvaluatedKey property that can be used in the next request to read the next page.
Partition throughput limits 🚰¶
A DynamoDB table isn't running on some giant supercomputer in the cloud. Rather, your data will be split across multiple partitions. Each partition contains roughly 10GB of data.
Each item in your DynamoDB table will contain a primary key that includes a partition key. This partition key determines the partition on which that item will live. This allows for DynamoDB to provide fast, consistent performance as your application scales.
Designing No-SQL Schema 🎨¶
NoSQL design requires a different mindset than RDBMS design. For an RDBMS, you can go ahead and create a normalized data model without thinking about access patterns.
In particular, it is important to understand three fundamental properties of your application's access patterns before you begin:
Data size: Knowing how much data will be stored and requested at one time will help determine the most effective way to partition the data.Data shape: Instead of reshaping data when a query is processed (as an RDBMS system does), a NoSQL database organizes data so that its shape in the database corresponds with what will be queried. This is a key factor in increasing speed and scalability.Data velocity: DynamoDB scales by increasing the number of physical partitions that are available to process queries, and by efficiently distributing data across those partitions. Knowing in advance what the peak query loads will be might help determine how to partition data to best use I/O capacity.
No-SQL best practices 🗒️¶
Keep related data together¶
The single most important factor in speeding up response time: keeping related data together in one place.
Tip
As a general rule, you should maintain as few tables as possible in a DynamoDB application.Exceptions are cases where high-volume time series data are involved, or datasets that have very different access patterns. A single table with inverted indexes can usually enable simple queries to create and retrieve the complex hierarchical data structures required by your application.
Use sort order ⧡¶
Related items can be grouped together and queried efficiently if their key design causes them to sort together.
Distribute queries 𝌭¶
It is also important that a high volume of queries not be focused on one part of the database, where they can exceed I/O capacity. Instead, you should design data keys to distribute traffic evenly across partitions as much as possible, avoiding "hot spots."
Use global secondary indexes 🌐¶
By creating specific global secondary indexes, you can enable different queries than your main table can support, and that are still fast and relatively inexpensive.