Snowflake ¶
-
Snowflake is true Software-as-a-Service (SaaS) for data
-
Its purely cloud based. All components of Snowflake’s service (other than optional command line clients, drivers, and connectors), run in public cloud infrastructures.
-
Snowflake enables data storage, processing, and analytic solutions that are faster, easier to use, and far more flexible than traditional offerings.
Warning
Snowflake cannot be run on private cloud infrastructures (on-premises or hosted).
Architecture¶
Snowflake’s architecture is a hybrid of shared-disk + shared-nothing architecture
-
Shared-disk architecture: Snowflake uses a central data repository for persisted data that is accessible from all compute nodes in the platform. -
Shared-nothing architecture: Snowflake processes queries using MPP (massively parallel processing) compute clusters where each node in the cluster stores a portion of the entire data set locally.
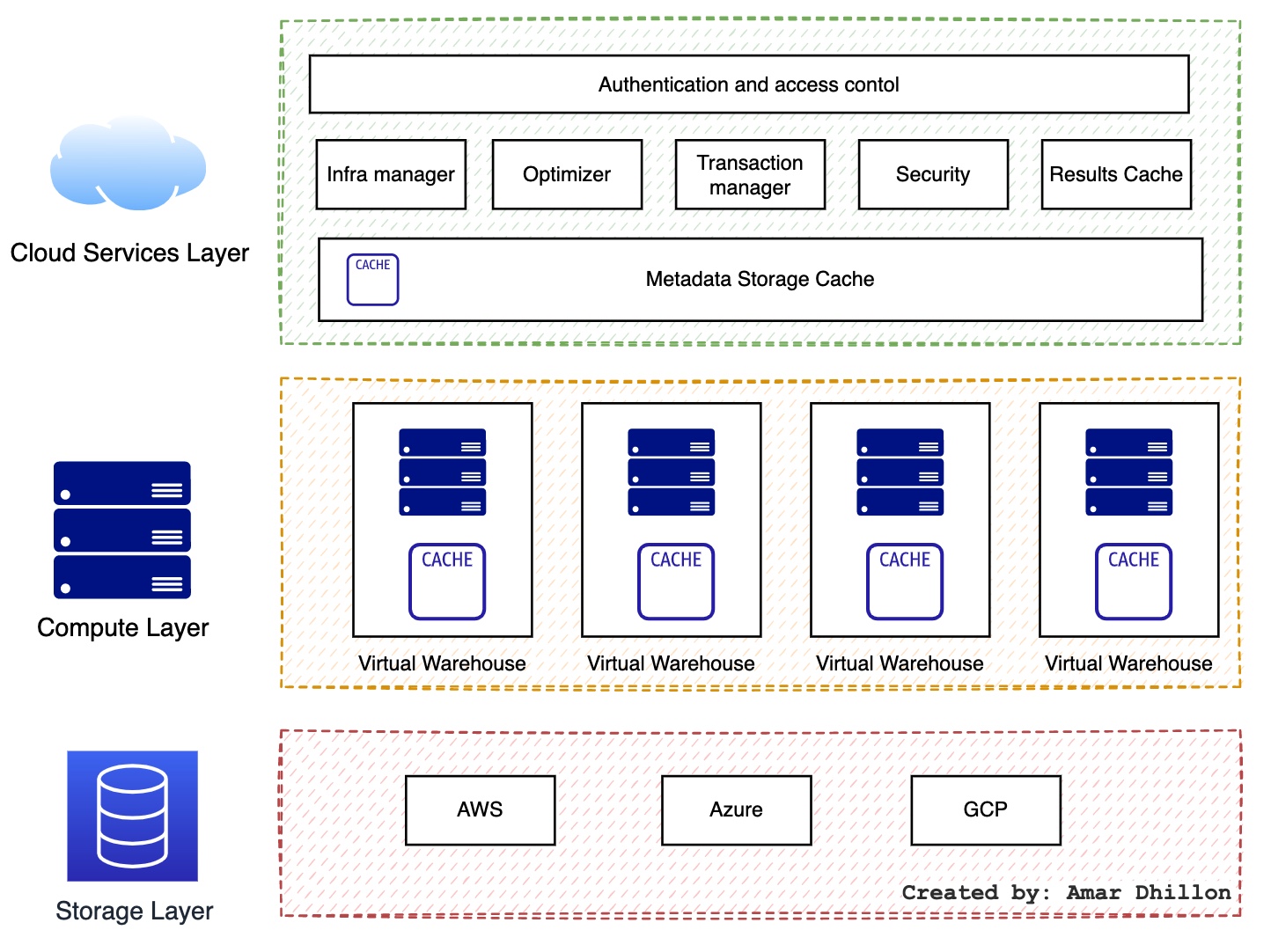
Snowflake’s unique architecture consists of three key layers:
- Storage Layer
- Query Processing Layer
- Cloud Services Layer
Storage Layer¶
-
Snowflake’s centralized database storage layer holds all data, including structured and semi-structured data.
-
As data is loaded into Snowflake, it is optimally reorganized into a compressed, columnar format and stored and maintained in Snowflake databases.
Can I view Snowflake data?
The data objects stored by Snowflake are not directly visible nor accessible by customers; they are only accessible through SQL query operations run using Snowflake
- Data stored in Snowflake databases is always compressed and encrypted. Snowflake takes care of managing every aspect of how the data is stored.
How data is stored in snowflake?
Snowflake automatically organizes stored data into micro-partitions: which are an optimized, immutable, compressed columnar format which is encrypted using AES-256 encryption
Query Processing Layer¶
- Query execution is performed in the processing layer.
- Snowflake processes queries using “virtual warehouses”. Each virtual warehouse is an MPP compute cluster composed of multiple compute nodes allocated by Snowflake from a cloud provider.
- The Snowflake compute resources are created and deployed on demand to the Snowflake user, to whom the process is transparent.
Tip
Snowflake’s unique architecture allows for separation of storage and compute, which means any virtual warehouse can access the same data as another, without any contention or impact on performance of the other warehouses. This is because each Snowflake virtual warehouse operates independently and does not share compute resources with other virtual warehouses
Cloud services Layer¶
All interactions with data in a Snowflake instance begin in the cloud services layer, also called the global services layer. The Snowflake cloud services layer is a collection of services that coordinate activities such as authentication, access control, and encryption.
Each time a user requests to log in, the request is handled by the cloud services layer. When a user submits a Snowflake query, the SQL query will be sent to the cloud services layer optimizer before being sent to the compute layer for processing.
Managing cache across AZ's¶
The Snowflake cloud services layer runs across multiple availability zones in each cloud provider region and holds the result cache, a cached copy of the executed query results. The metadata required for query optimization or data filtering are also stored in the cloud services layer.
Auto Suspend and Auto resume¶
Auto Suspend is the number of seconds that the virtual warehouse will wait if no queries need to be executed before going offline.
Auto Resume will restart the virtual warehouse once there is an operation that requires compute resources.
Features¶
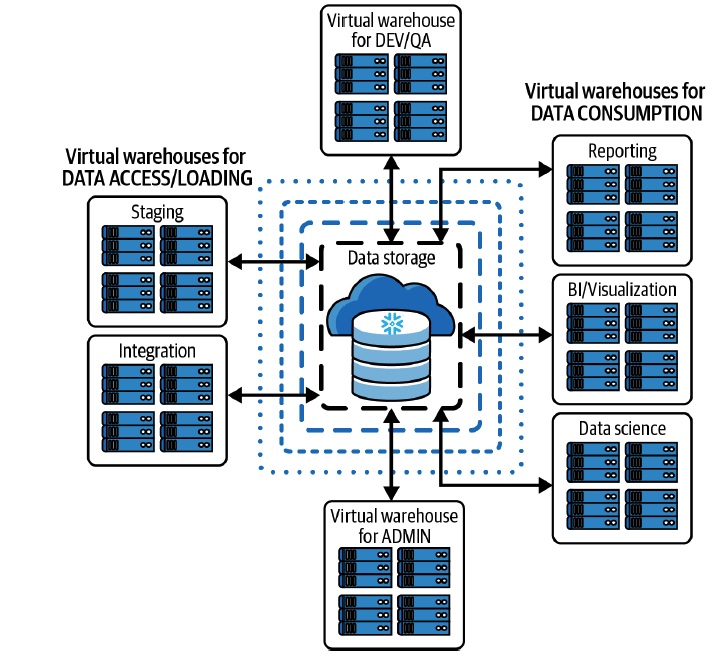
- A multicluster virtual warehouse allows Snowflake to scale in and out automatically.
- We can use different kinds of Warehouses in the snowflake to hanlde different kinds of requirements
Compression¶
Another fundamental engineering work from Snowflake was the proprietary and sizeable compression. Faster compression and less data transfer led to less Input Output (IO) costs and an overall faster architecture. It is not uncommon to see 5x compression when migrating data to Snowflake.
Common Table Expressions:¶
A Common Table Expression, also called as CTE in short form, is a temporary named result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement. The CTE can also be used in a View.
The WITH clause, an optional clause that precedes the SELECT statement, is used to define common table expressions (CTEs) which are referenced in the FROM clause
WITH expression_name [ ( column_name [,...n] ) ]
AS
( CTE_query_definition )
To view the CTE result we use a Select query with the CTE expression name.
Select [Column1,Column2,Column3 …..] from expression_name
Zero-Copy Cloning¶
Zero-copy cloning offers the user a way to snapshot a Snowflake database, schema, or table along with its associated data. There is no additional storage charge until changes are made to the cloned object, because zero-copy data cloning is a metadataonly operation
Time Travel¶
Time Travel allows you to restore a previous version of a database, table, or schema. This is an incredibly helpful feature that gives you an opportunity to fix previous edits that were done incorrectly or restore items deleted in error.
Caching¶
When you submit a query, Snowflake checks to see whether that query has been previously run and, if so, whether the results are still cached. Snowflake will use the cached result set if it is still available rather than executing the query you just submitted
There are three Snowflake caching types:
-
Query result cache: The fastest way to retrieve data from Snowflake is by using the query result cache. The results of a Snowflake query are cached, or persisted, for 24 hours and then purged.The result cache is fully managed by the Snowflake global cloud services (GCS) layer, as shown in Figure 2-18, and is available across all virtual warehouses since virtual warehouses have access to all data.
-
Virtual warehouse cache: Running virtual warehouses use SSD storage to store the micro-partitions that are pulled from the centralized database storage layer when a query is processed.Danger
This cache is dropped once the virtual warehouse is suspended, so you’ll want to consider the trade-off between the credits that will be consumed by keeping a virtual warehouse running and the value from maintaining the cache of data from previous queries to improve performance.
-
Metadata cache: The Snowflake metadata repository includes table definitions and references to the micro-partition files for that table.
Commands¶
USE ROLE SYSADMIN;
CREATE WAREHOUSE AmarBlog_WH_S WITH WAREHOUSE_SIZE = MEDIUM
AUTO_SUSPEND = 300 AUTO_RESUME = true INITIALLY_SUSPENDED = true;
USE ROLE SYSADMIN;
ALTER WAREHOUSE AmarBlog_WH_S
SET WAREHOUSE_SIZE = LARGE;
USE WAREHOUSE AmarBlog_WH_M