Power BI ¶
Concepts¶
The five major building blocks of Power BI are:
- Dashboards
- Reports
- Workbooks
- Datasets
- Dataflows
They're all organized into workspaces, and they're created on capacities. It's important to understand capacities and workspaces before we dig into the five building blocks, so let's start there.
Capacity¶
Capacities are a core Power BI concept representing a set of resources (storage, processor, and memory) used to host and deliver your Power BI content. Capacities are either shared or reserved.
A shared capacity is shared with other Microsoft customers, while a reserved capacity is reserved for a single customer.
Workspaces¶
How to share powerBI content?
A workspace is like a shared folder between a team of users. This can be a place to share some of the Power BI content
There are two types of licenses for Power BI; capacity-based and user-based licensing. The capacity-based licensing is usually better for organizations with more than hundreds of users, and user-based licensing is good for small to medium size businesses
There are two types of workspaces:
- My workspace (user based)
- Workspaces (Capacity based)
My workspace¶
It is the personal workspace for any Power BI customer to work with your own content. Only you have access to your My workspace. You can share dashboards and reports from your My Workspace.
Workspaces¶
Workspaces are used to collaborate and share content with colleagues. You can add colleagues to your workspaces and collaborate on dashboards, reports, workbooks, and datasets.
Warning
Each workspace member needs a Power BI Pro or Premium Per User (PPU) license.
Dashboard¶
Tldr
A Power BI dashboard is a single page, often called a canvas, that uses visualizations to tell a story. Because it is limited to one page, a well-designed dashboard contains only the most-important elements of that story.
-
It is a single screen with tiles of interactive visuals, text, and graphics. A dashboard collects your most important metrics, on one screen, to tell a story or answer a question.
-
if a business user is given permissions to the report, they can build their own dashboards too.
-
As the capacity must share resources, limitations are imposed to ensure "fair play", such as the maximum model size (1 GB) and maximum daily refresh frequency (8 times per day).
The visualizations on a dashboard come from reports and each report is based on one dataset. In fact, one way to think of a dashboard is as an entryway into the underlying reports and datasets. Selecting a visualization takes you to the report that was used to create it.
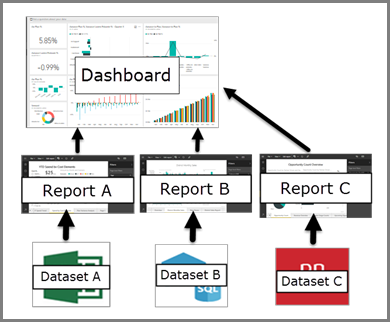
Visualization:¶
It is a type of chart built by Power BI designers. The visuals display the data from reports and datasets.
How many datasets are feasible?
All of the visualizations in a report come from a single dataset. Power BI Desktop can combine more than one data source into a single dataset in a report, and that report can be imported into Power BI.
Report¶
Report is one or more pages of interactive visuals, text, and graphics that together make up a single report. Power BI bases a report on a single dataset.
Tile¶
A tile is a snapshot of your data, pinned to a dashboard by a designer. Designers can create tiles from a report, dataset, dashboard, the Q&A question box, Excel, SQL Server Reporting Services (SSRS), and more.
DAX¶
Data Analysis Expressions (DAX) is a programming language that is used throughout Microsoft Power BI for creating calculated columns, measures, and custom tables. It is a collection of functions, operators, and constants that can be used in a formula, or expression, to calculate and return one or more values.
using DAX to calculate columns
DAX allows you to augment the data that you bring in from different data sources by creating a calculated column that didn't originally exist in the data source. This feature should be used sparingly
DAX and MScript¶
Power BI has 2 mighty hands, DAX (powered by SQL Server Analysis Service) and M Script (powered by Power Query), to perform the ETL jobs and visualization related calculations. Both of these engines are efficient with their way of performing calculations.
where not to use DAX and MScript?
When it comes to performing calculations in an optimized way, both under-perform compared to database engines, since they are in-memory calculation engines best suited to play with data. They lack indexing of data, which database handles while storing of data. Also, database engine re-uses query results of last few queries, by keeping track of changing data, which is something complex for both DAX & Power Query. As the data size grows, performance difference is quite noticeable.
Calculated column and measure¶
The fundamental difference between a calculated column and a measure is that a calculated column creates a value for each row in a table. For example, if the table has 1,000 rows, it will have 1,000 values in the calculated column. Calculated column values are stored in the Power BI .pbix file. Each calculated column will increase the space that is used in that file and potentially increase the refresh time.
Measures are calculated on demand. Power BI calculates the correct value when the user requests it. Measures do not add to the overall disk space of the Power BI .pbix file.
Dataflow¶
Tldr
Dataflow is a collection of Power Query queries that are scheduled and executed together.
It's up to you how you organize the staged data in dataflows. For example, if you need to stage some tables from Dynamics 365, you can create one dataflow that has a query for each table you want to stage. So, dataflows allow you to logically group related Power Query queries
Query folding¶
Query folding is the ability for a Power Query query to generate a single query statement that retrieves and transforms source data.
Query folding may occur for an entire Power Query query, or for a subset of its steps. When query folding cannot be achieved—either partially or fully—the Power Query mashup engine must compensate by processing data transformations itself. This process can involve retrieving source query results, which for large datasets is very resource intensive and slow.
PowerBI Service¶
There are two hosting options for Power BI reports
-
Cloud-based hosting (called
Power BI Serviceor website): In thePower BI Service, organizations are separated usingTenants. Tenants can be managed byAzure Active DirectoryorOffice 365. Under tenants, there will be users. These users are Azure Active Directory users. -
On-premises hosting (called
Power BI Report Server)
Storage mode¶
Today PowerBI offers 4 different storage modes for tables:
Import mode¶
In this mode, Power BI connects with underlying data source & downloads entire data from the datasource. This data is stored in Power BI model (in an in-memory cache). Fresh copy of this data can be downloaded by pressing Refresh button. PBIX file internally stores model data in compressed format. This published datset model on Power BI Service, internally is stored on Common Data Model, which is sort of Azure Managed SQL Server instance in the backend.
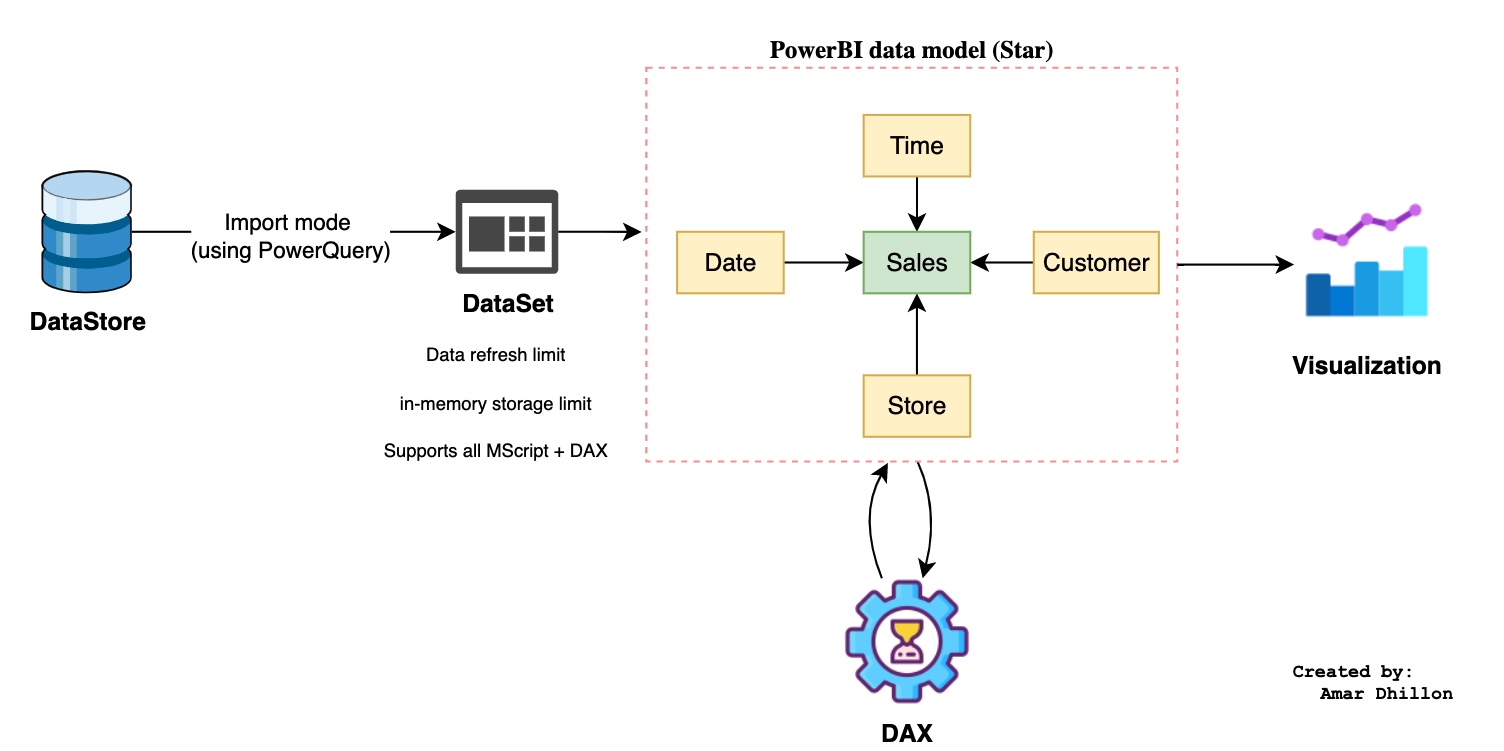
Which is the fastest method
The fastest method is Import mode. Essentially, this mode allows you to load the data once into Power BI, where it is then stored. Power BI uses the in-memory VertiPaq/xVelocity engine, which is exceptionally fast and delivers results almost immediately. It offers full DAX and PowerQuery support. A quick rule of thumb is that you can typically expect about 10x compression when importing data into Power BI
The drawback is that it only permits you to refresh data 8 times per day.
DirectQuery mode¶
With DirectQuery datasets, no data is imported into Power BI. Instead, your Power BI dataset is simply metadata (e.g., tables, relationships) of how your model is structured to query the data source. Data is only brought into Power BI reports and dashboards at query-time (e.g., a user runs a report, or changes filters).
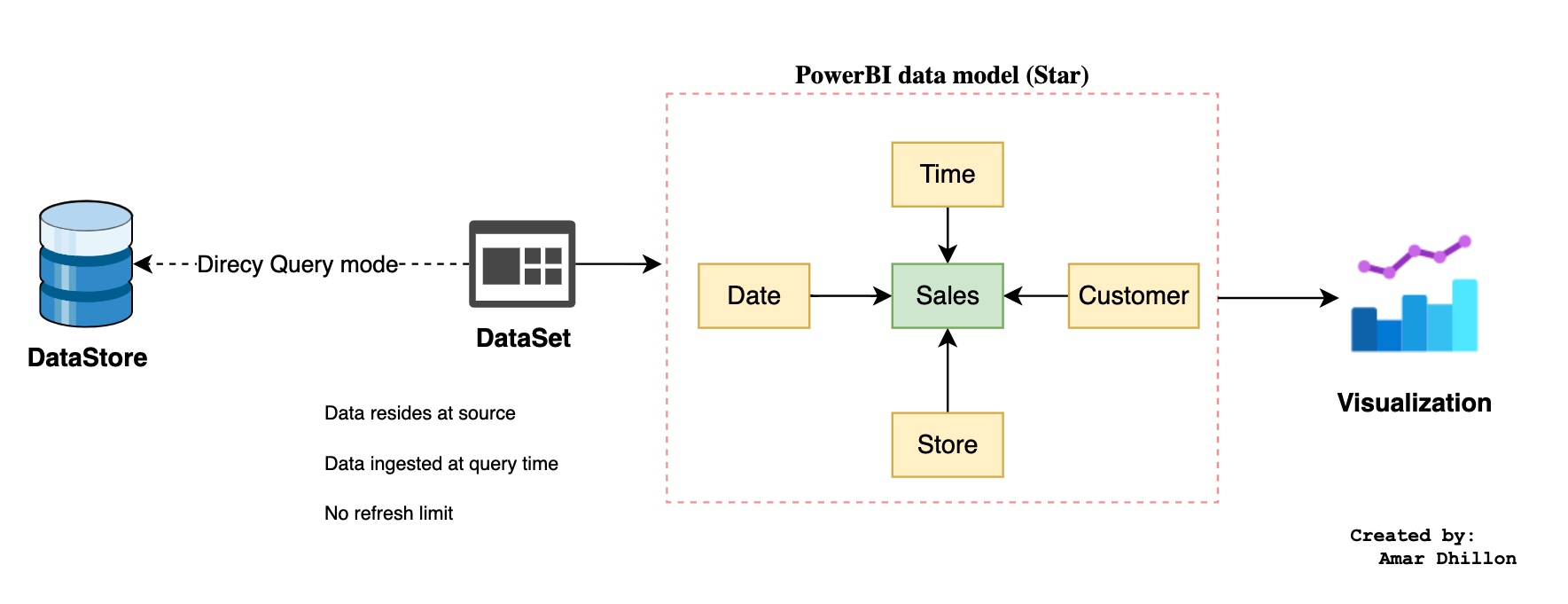
Pros: - Dataset size limits do not apply as all data still resides in the underlying database. - Datasets do not require a scheduled refresh as data is only retrieved at query-time.
Cons: - Typically, query-time performance will suffer, even when querying a cloud data warehouse like Snowflake. - Concurrency (e.g., multiple users running reports) against DirectQuery datasets could cause performance issues against the underlying database.
Dual mode¶
Dudata is imported into cache memory, but can also be served directly from the data source at the query time
Hybrid tables/ Composite mode¶
Tldr
- Cold data in
Import mode, Hot data inDirectQuery. - Hybrid tables can only be applied on a table that incremental refresh is set on it.
- Hybrid tables are partitioned, so their most recent partition is a DirectQuery from the data source, and their historical data is imported into other partitions.
- If your data source doesn’t support query folding, For example, it is a CSV file. Then Power BI, when connected to it, reads the entire data anyway.
- Incremental Refresh doesn’t need a Premium or PPU license. You can even set it up using a Power BI Pro license. However, Hybrid tables require a Power BI Premium capacity or PPU.

Composite models aka hybid tables attempt to combine the best aspects from Import and DirectQuery modes into a single dataset. With Composite models, data modelers can configure the storage mode for each table in the model
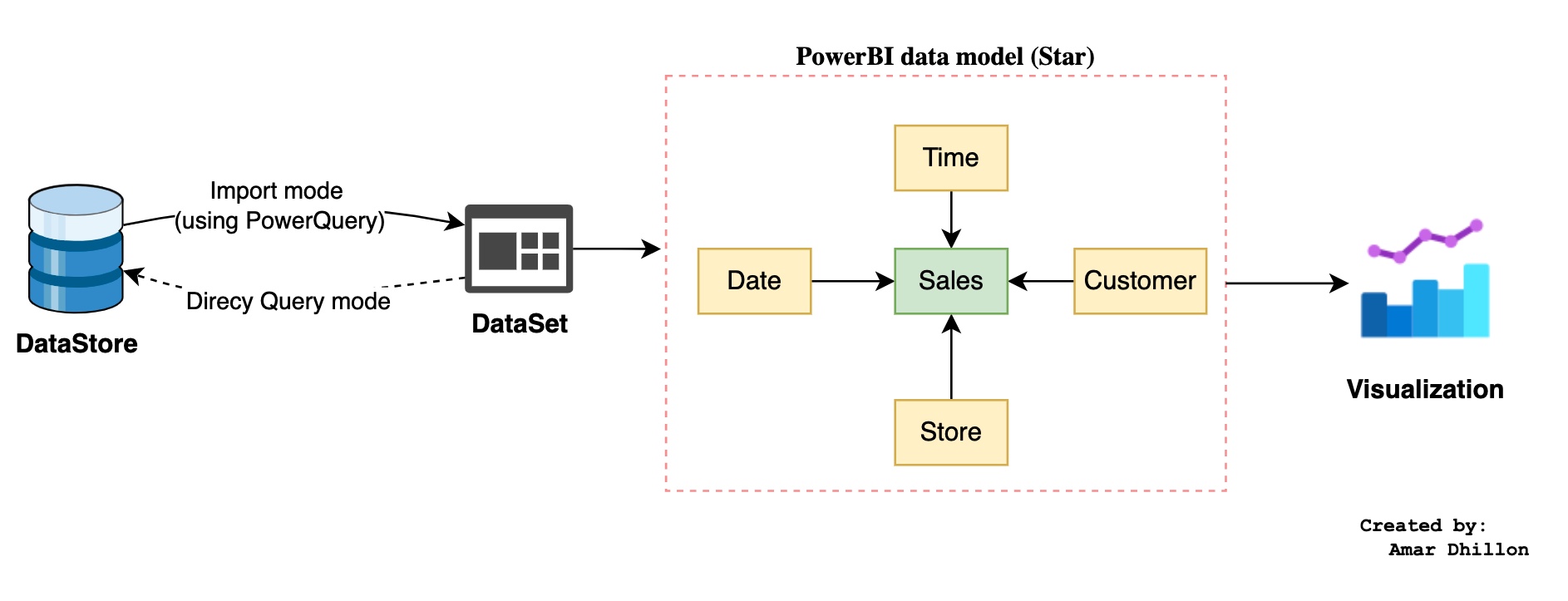
PowerBI Architecture¶
Front-end cluster¶
The overall technical architecture consists of two clusters:
- a Web Front End (WFE) cluster
- a Back End cluster
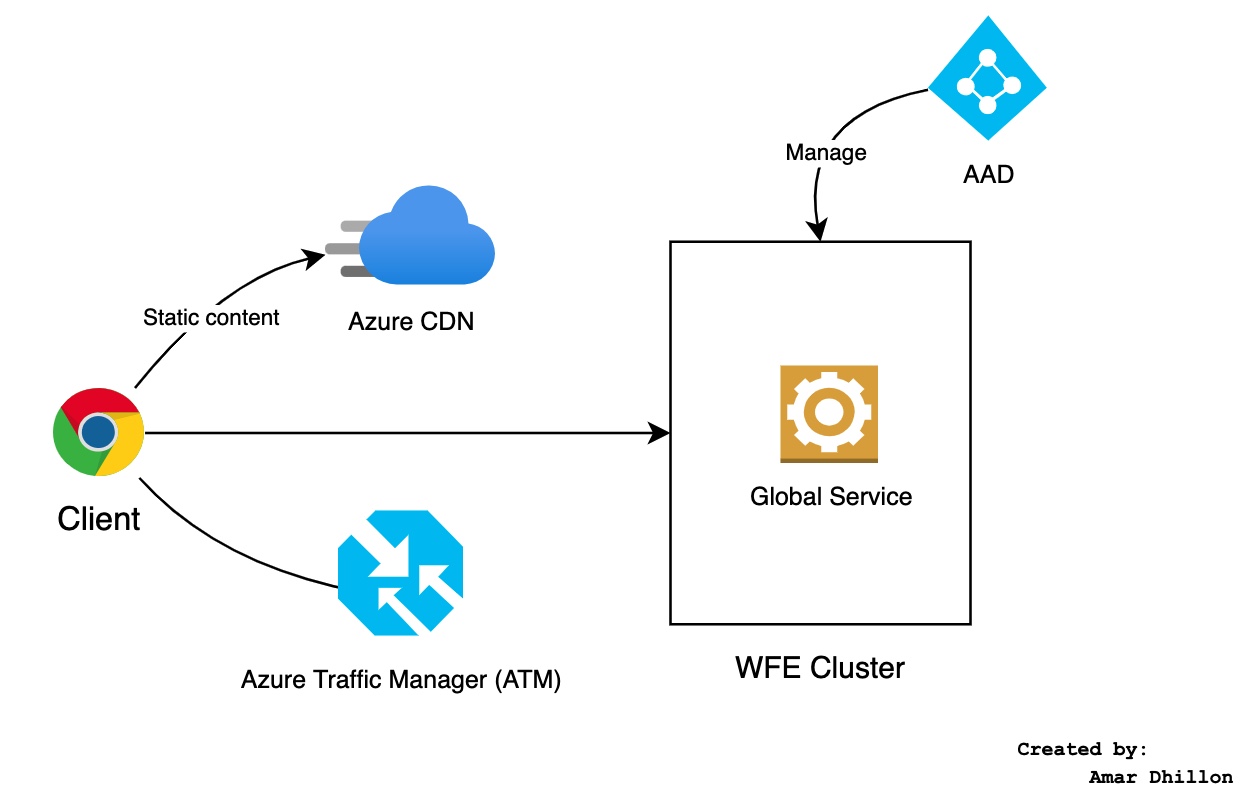
AAD¶
The WFE cluster manages connectivity and authentication. Power BI relies on Azure Active Directory (AAD) to manage account authentication and management.
ATM¶
Power BI uses the Azure Traffic Manager (ATM) to direct user traffic to the nearest data center. Which data center is used is determined by the DNS record of the client attempting to connect. The DNS Service can communicate with the Azure Traffic Manager to find the nearest data center with a Power BI deployment
CDN¶
Power BI uses the Azure Content Delivery Network (CDN) to deliver the necessary static content and files to end users based on their geographical locale. The WFE cluster nearest to the user manages the user login and authentication and provides an access token to the user once authentication is successful. The ASP.NET component within the WFE cluster parses the request to determine which organization the user belongs to, and then consults the Power BI Global Service
Global Service¶
The Global Service is implemented as a single Azure Table that is shared among all worldwide WFE and Back End clusters. This service maps users and customer organizations to the datacenter that hosts their Power BI tenant. The WFE specifies to the browser which backend cluster houses the organization's tenant.
Once a user is authenticated, subsequent client interactions occur with the backend cluster directly and the WFE cluster is not used.
Back-end cluster¶
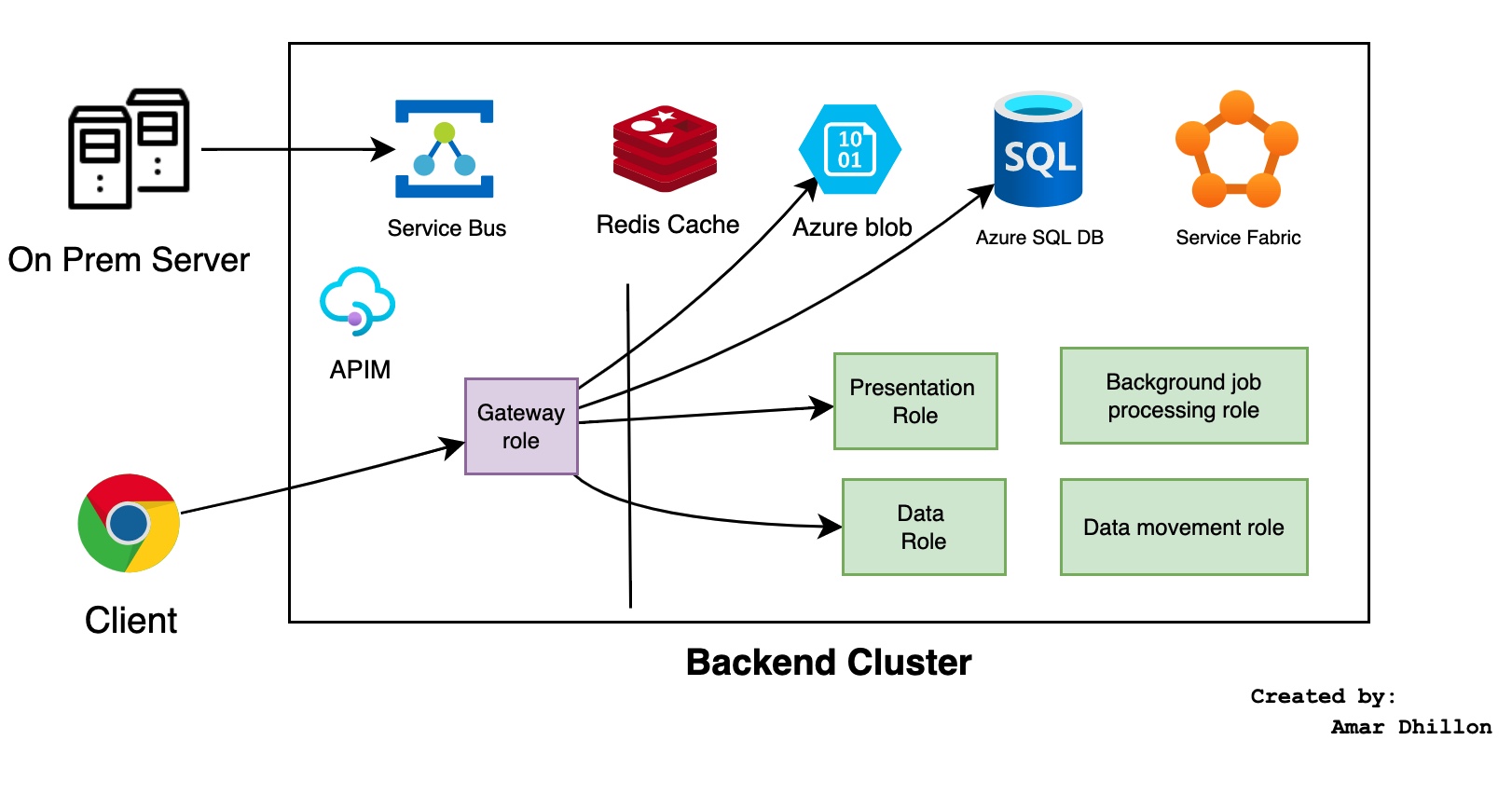
The backend cluster manages all actions the user does in Power BI Service, including visualizations, dashboards,datasets, reports, data storage, data connections, data refresh, and others.
Gateway and APIM¶
The Gateway Role acts as a gateway between user requests and the Power BI service. As you can see in the diagram, only the Gateway Role and Azure API Management (APIM) services are accessible from the public Internet.
When an authenticated user connects to the Power BI Service, the connection and any request by the client is accepted and managed by the Gateway Role, which then interacts on the user's behalf with the rest of the Power BI Service. For example, when a client attempts to view a dashboard, the Gateway Role accepts that request, and then sends a request to the Presentation Role to retrieve the data needed by the browser to render the dashboard.
Data Storage¶
As far as data storage in the cloud goes, Power BI uses two primary repositories for storing and managing data. Data that is uploaded from users or generated by dataflows is stored in Azure BLOB storage, but all the metadata definitions (dashboards, reports, recent data sources, workspaces, organizational information, tenant information) are stored in Azure SQL Database.
Performance Optimization of PowerBI¶
Analyze the results¶
-
Power BI Performance Analyzer: The natural starting point is Power BI Performance Analyzer, a built-in feature of Power BI Desktop. Select the View ribbon, and then select Performance Analyzer to display the Performance Analyzer pane. -
DAX Studio: You can analyze performance using in another tool calledDAX Studio. This is a a great tool for performance analysis.
Using direct query?¶
There's another situation that can slow down your report. You might be creating tables that use DirectQuery as the connection mode. This means that the data is not loaded into Power BI. Instead, it is loaded using a query that runs on a database server. This means additional time to fetch the data.
This shows up as another item on the report, since Power BI first needs to fetch the data, process it using a PowerQuery and pass it on to a DAX command.
Avoid Joins¶
People essentially just load all the tables into Power BI and start creating relationships. Then, they need to write complex DAX formulas to tie everything together. To make everything run faster, however, you need to combine tables and merge them before you even load them into Power BI.
De-normalize data model¶
Combine or append the tables that are similar in structure and used for the same purpose. For example, fact tables like sales, actuals, plan and different forecasts can be combined or appended into a single table.
Incremental Refresh¶
When you load data from the source into the destination (Power BI), there are two methods: Full Load or Incremental Refresh. Full Load means fetching the entire dataset each time and wiping out the previous data.
Incremental refresh is an important feature to consider when working with large tables that you would like to import into memory. With Incremental Refresh, partitions are automatically created on your Power BI table based on the amount of history to retain, as well as the partition size you would like to set. Since data modelers can define the size of each partition, refreshes will be faster, more reliable, and able to build history over time.
When to use incremental refresh/
Consider you have a large dataset including 20 years of data. From that dataset, probably the data from 20 years ago won’t change anymore, or even the data from 5 years ago, sometimes even a year ago. So why re-processing it again? Why re-loading data that doesn’t update? Incremental Refresh is the process of loading only part of the data that might change and adding it to the previous dataset, which is no longer changing.
When setting up Incremental Refresh, keep in mind the following:
- You must create RangeStart and RangeEnd date/time parameters. These parameters must be set to a date/time data type and must be named RangeStart and RangeEnd.
- The initial refresh in the Power BI service will take the longest due to the creation of partitions and loading of historical data. Subsequent refreshes will only process the latest partition(s) based on how the feature was configured.
Partitioning¶
Incremental Load will split the table into partitions. The quantity of the partitions will be based on the settings applied at the time of Incremental refresh. For example, if you want to have the last year’s data refreshed only, a yearly partition will likely be created for every year, and the one for the current year will be refreshed on a scheduled basis.
Hybrid tables¶
Are you using hybrid tables?
Query folding¶
Are you using query folding and is ti finishing completely?
Avoid row-level security¶
Last but not least, avoid row-level security, which can be a performance killer.
Dimentional modelling¶
It is a set of guidelines to design database table structure for easier and faster data retrieval.
Remember
Data is stored in de-normalized form here.
-
Dimentions: Descriptive entity.
-
Facts: Quantitative entity value. They are mostly values.
Dimentional model vs Normal form models
| Syntax | Normal form models | Dimentional |
|---|---|---|
| Purpose | Transactional systems | For reporting |
| Structure | Complex | Less comples (Denormalized data) |
| Operations | Insert, upate and delete | Mostly Select (read only) |
| Bitmap Index | Not used | Heavily used |
Various kinds of dimentional modelling are =:
Star Schema¶
In this data model, you use a fact table, which is the table like sales that contains facts, meaning your measures. The fact table is related to your dimensions, which are things like your salespeople, products, business units, customers and so on. The fact table then has one-to-many relationships to your dimension tables.
Snowflake schema¶
In a snowflake schema, each property of entries in a dimension table is assigned to a new table, creating what seems like a snowflake.
Snowflake and PowerBI¶
We need to used datawarehouse in front of PowerBI
Data storage mode
For larger datasets, DirectQuery and Hybrid tables is a good option. Snowflake will handle the heavy lifting.
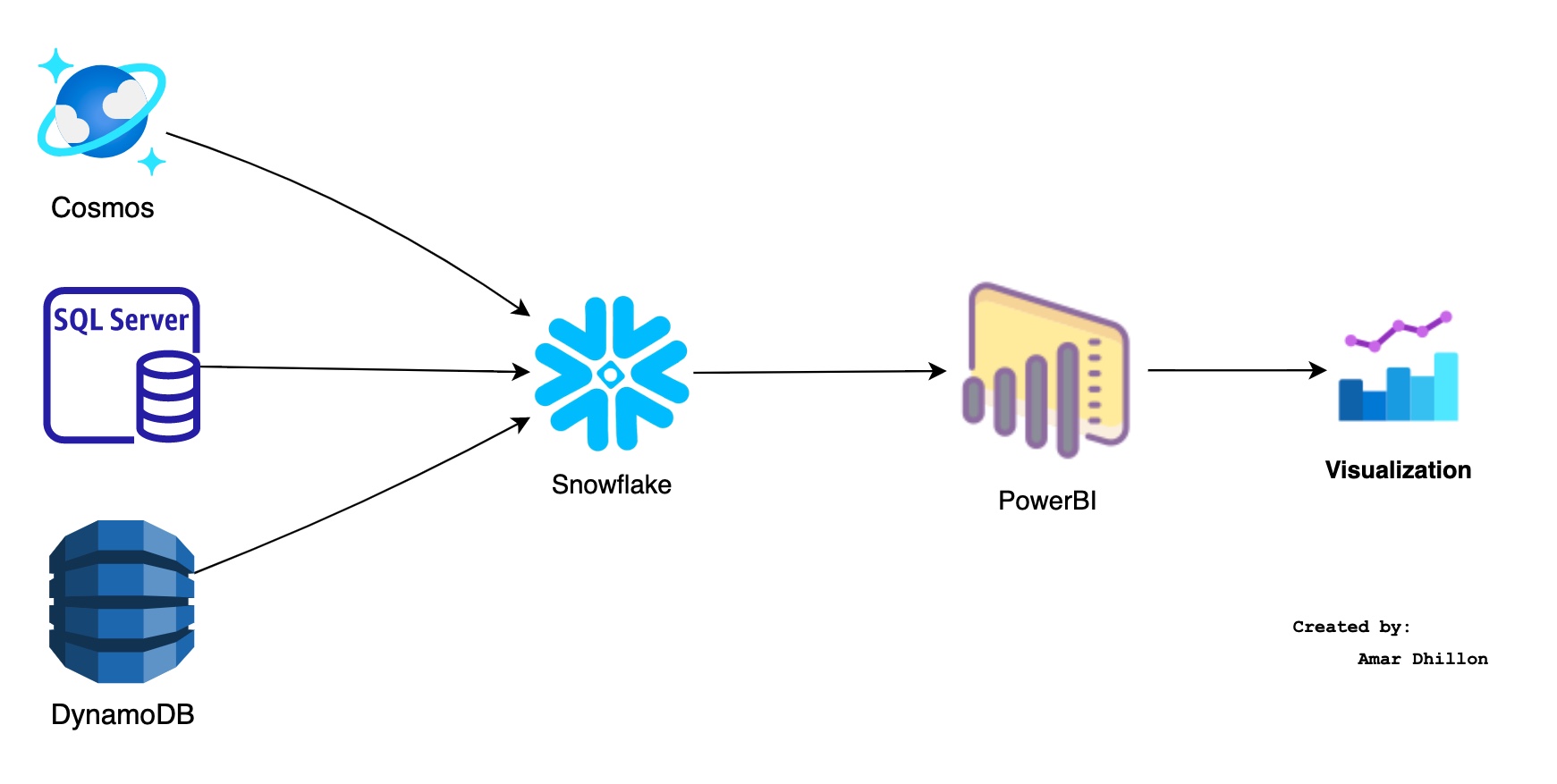
Best Practices when using DW with PowerBI¶
- Make sure the data visualizations are use case driven, this includes the timing of the data, number of visualizations and other components.
-
Data Model Design: How you design your data model will have a major impact on query performance in Power BI.
-
Ideally, use a
Star Schema Designfor your data in Power BI withFacts and Dimensions. It is also important to have a more relational, normalized Data Vault type of an ODS model in Snowflake to get the best performance in Power BI. -
Use
Import modefor dimension tables andDirect querymode for Fact tables. -
Use
aggregationsin Power BI for pre-aggregated data to get better query performance -
Keep the dashboard simple by limiting the number of data points, visuals and queries in a page to a minimum. This will also help query performance as there will be lesser number of queries to run while refreshing the visualization.
-
Use
Query reductionto limit the number of queries generated. This is especially helpful when using slicers in your visualization, where you only want the filters applied when the “Apply” button is used. -
To make modeling easier, use the
Assume referential integrityproperty on relationships. While the default property on a relationship in Power BI is to generate aleft outer join, by using the “Assume referential integrity” property, you can force an inner join. This can make the queries faster. This property is available only in a Direct Query mode. -
Use bi-directional filter on relationships with discretion. More bi-directional filters mean you will generate more SQL queries. These can increase the complexity of the model and increase compute costs in Snowflake.
-
Pruning micro partitions on large data sets in Snowflake, creating additional tables with larger data with alternate sets of keys driven by the end users ad-hoc query needs can result in better performance
Auth flow¶
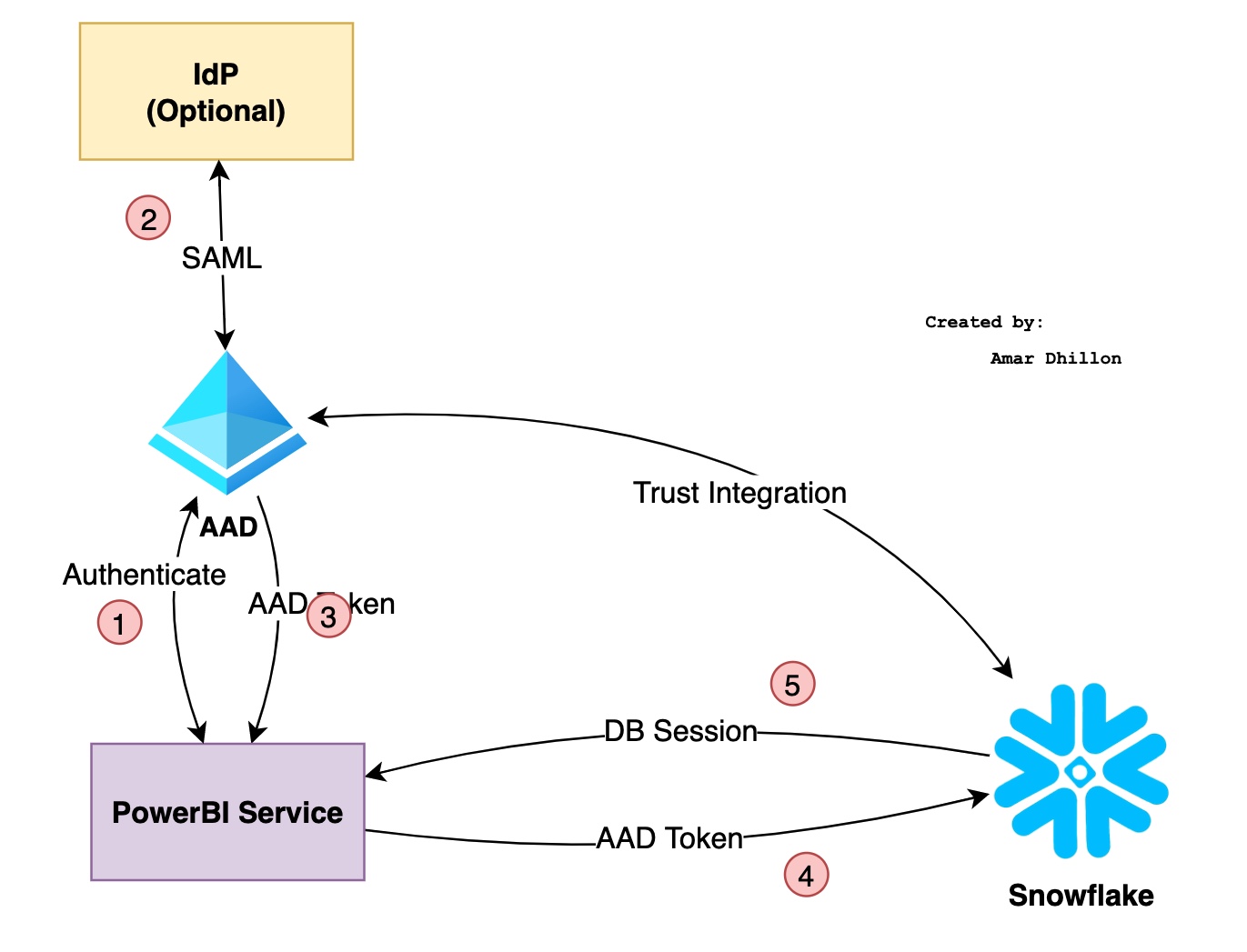
- The user logs into Power BI service using Microsoft Azure Active Directory (Azure AD).
- (Optional) If the identity provider is not Azure AD, then Azure AD verifies the user through SAML authentication before logging the user into the Power BI service.
- When the user connects to Snowflake, the Power BI service asks Azure AD to give it a token for Snowflake
- The
Power BIservice uses the embedded Snowflake driver to send the Azure AD token to Snowflake as part of the connection string. Snowflakevalidates the token, extracts the username from the token, maps it to the Snowflake user, and creates a Snowflake session for the Power BI service using the user’s default role.