Event Hub (Pull based) ¶
Event Grid Vs Event Hub¶
A key difference between Event Grid and Event Hubs is in the way event data is made available to the subscribers. Event Grid pushes the ingested data to the subscribers whereas Event Hub makes the data available in a pull model.
What is Azure Event Hubs?
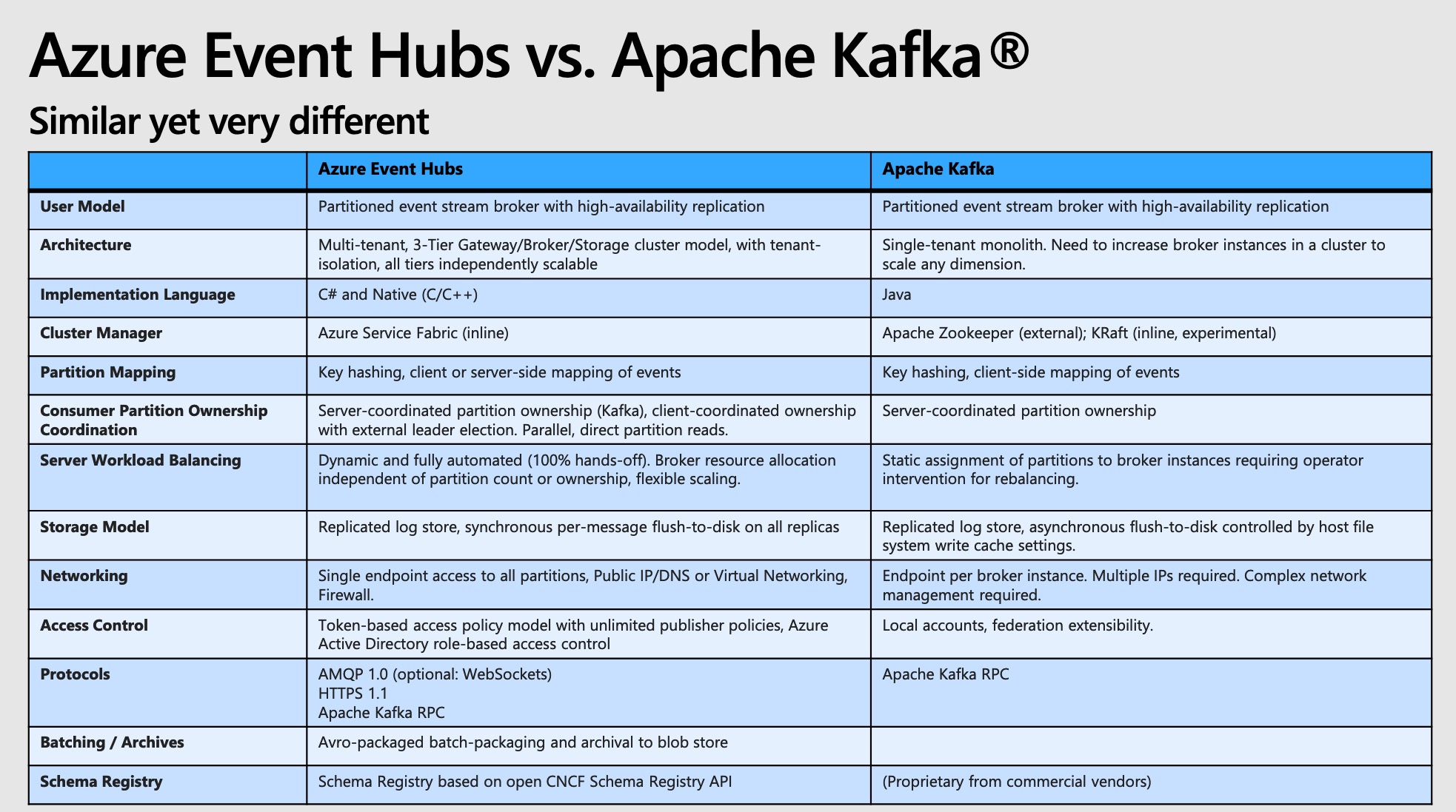
- Platform-as-a-Service Event Stream Broker Use the Apache Kafka® API, but with far lower cost and better performance.
- Fully managed: You use the features, Azure deals with everything else
- AMQP 1.0 standards compliant, Apache Kafka® wire-compatible
- Polyglot Azure SDK and cross-platform client support
Event Hub Vs Kafka ⚖️¶
What Event hub is not?¶

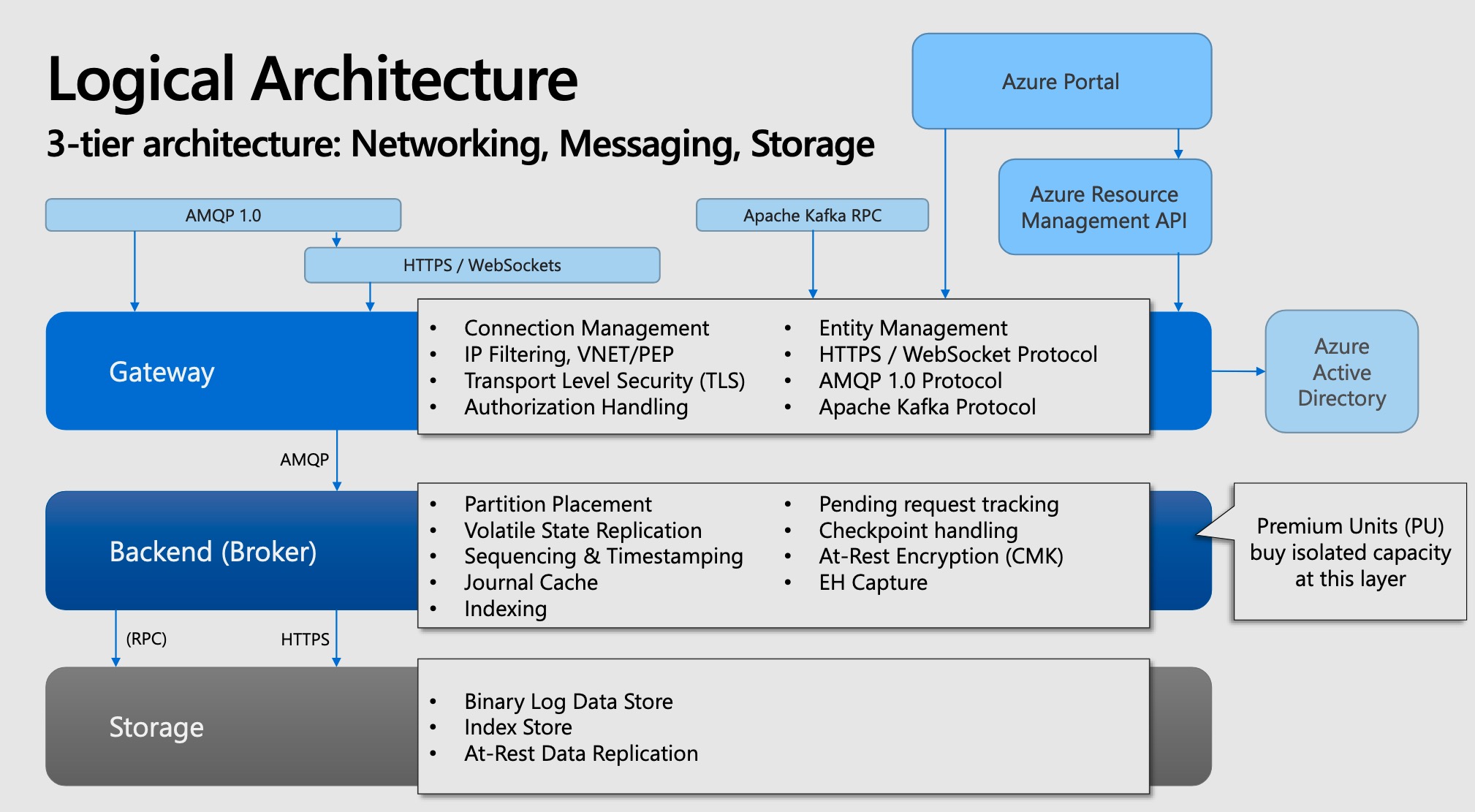
Event-hub Architecture 🏛️¶
Concepts 📕¶
Azure Event Hubs is part of a fleet of services, which also includes Azure Service Bus, and Azure Event Grid.
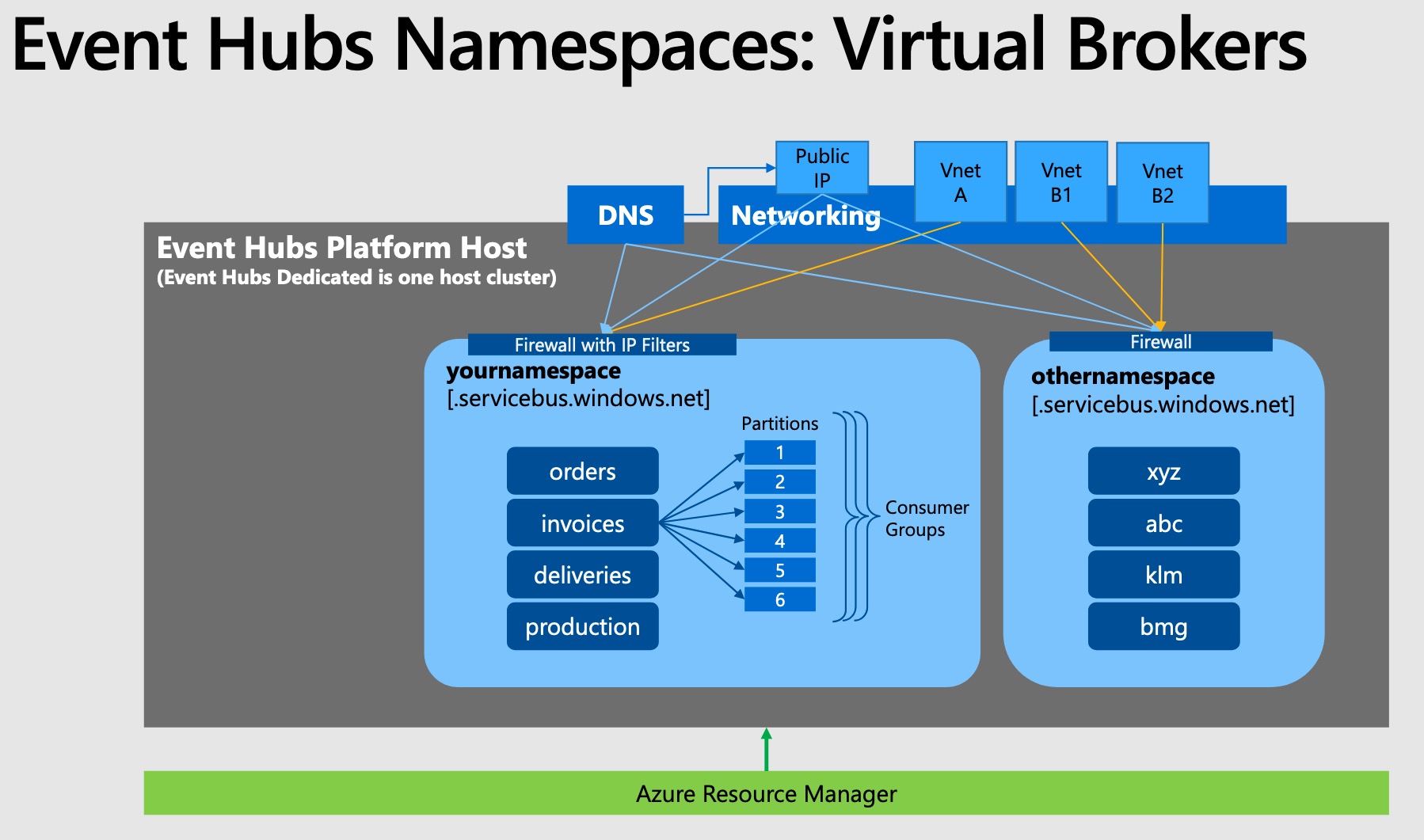
Namespaces 📇¶
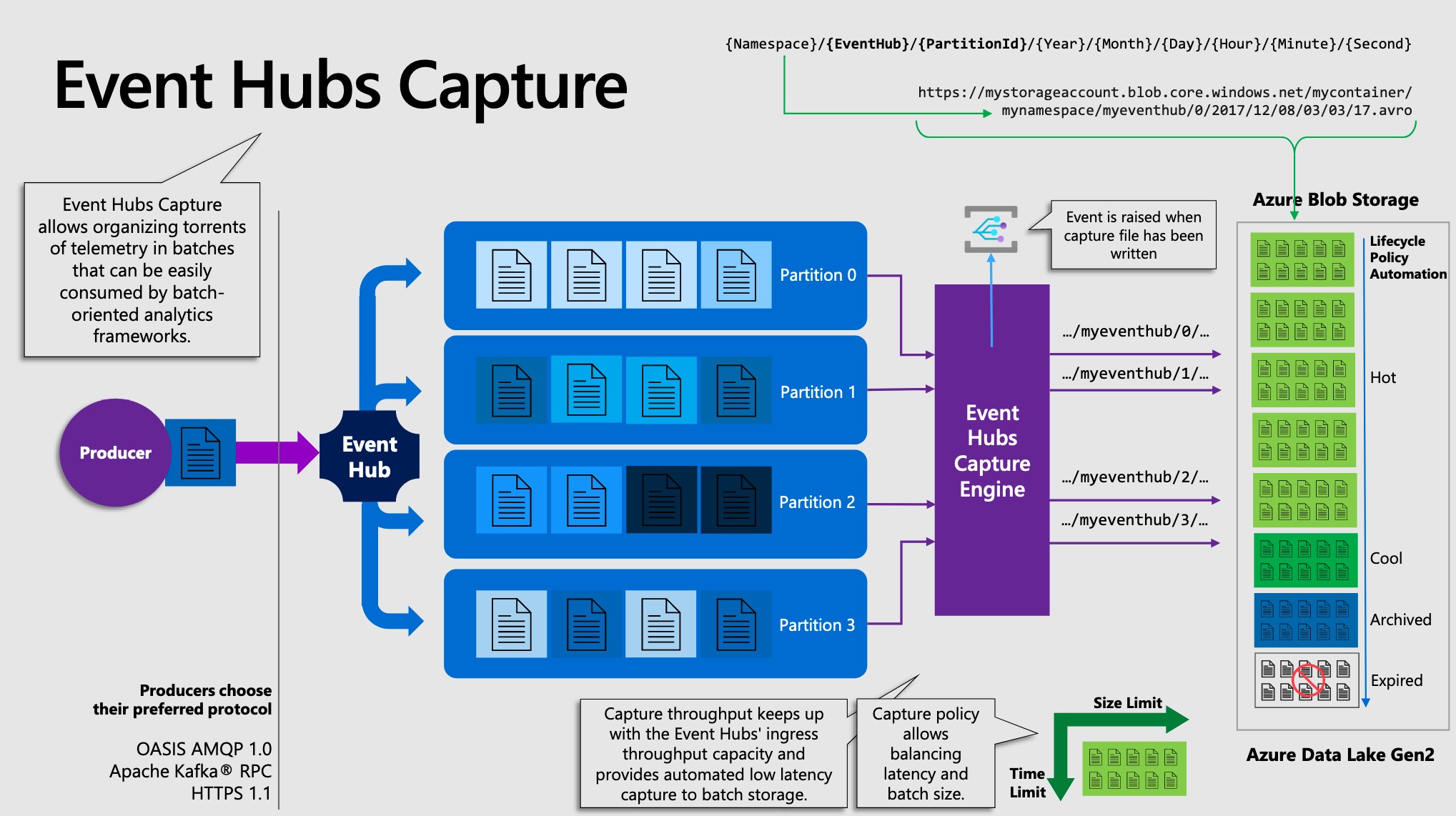
Event hub capture¶
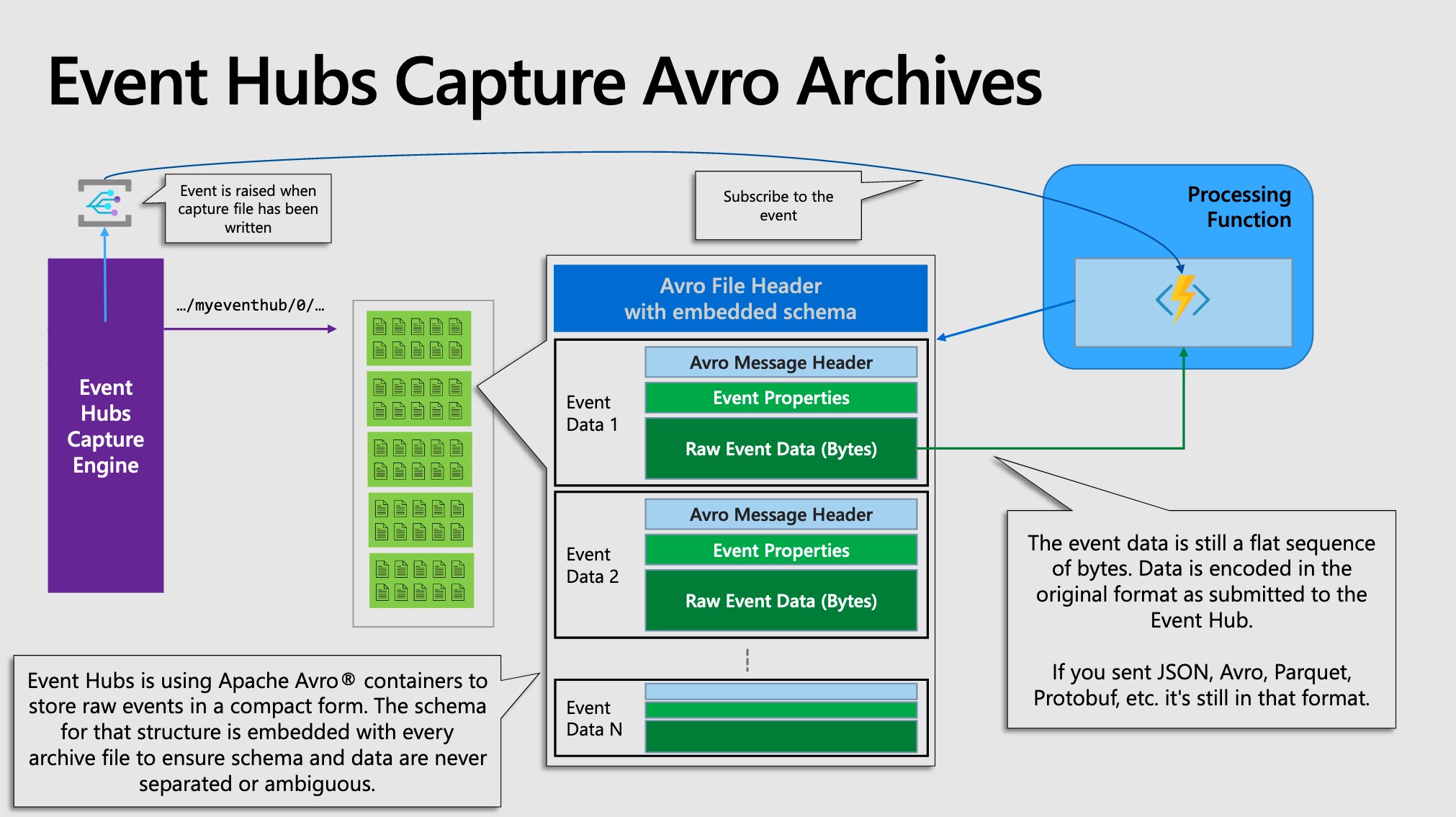
Usign the AVRO schemas as shown below
Stream Processing 🎰¶
When it comes to stream processing, there are generally two approaches to working through the infinite stream of input data (or tuples):
Tuple at a time:You can process one tuple at a time with downstream processing applications,Micro batching: You can create small batches (consisting of a few hundred or a few thousand tuples) and process these micro-batches with your downstream applications.
Kafka and Event hub mapping¶
| Kafka | Event Hub |
|---|---|
| Cluster | Namespace |
| Topic | Event hub |
| Partition | Partition |
| Consumer Group | Consumer Group |
| Offset | Offset |
Pubsub 🚄¶
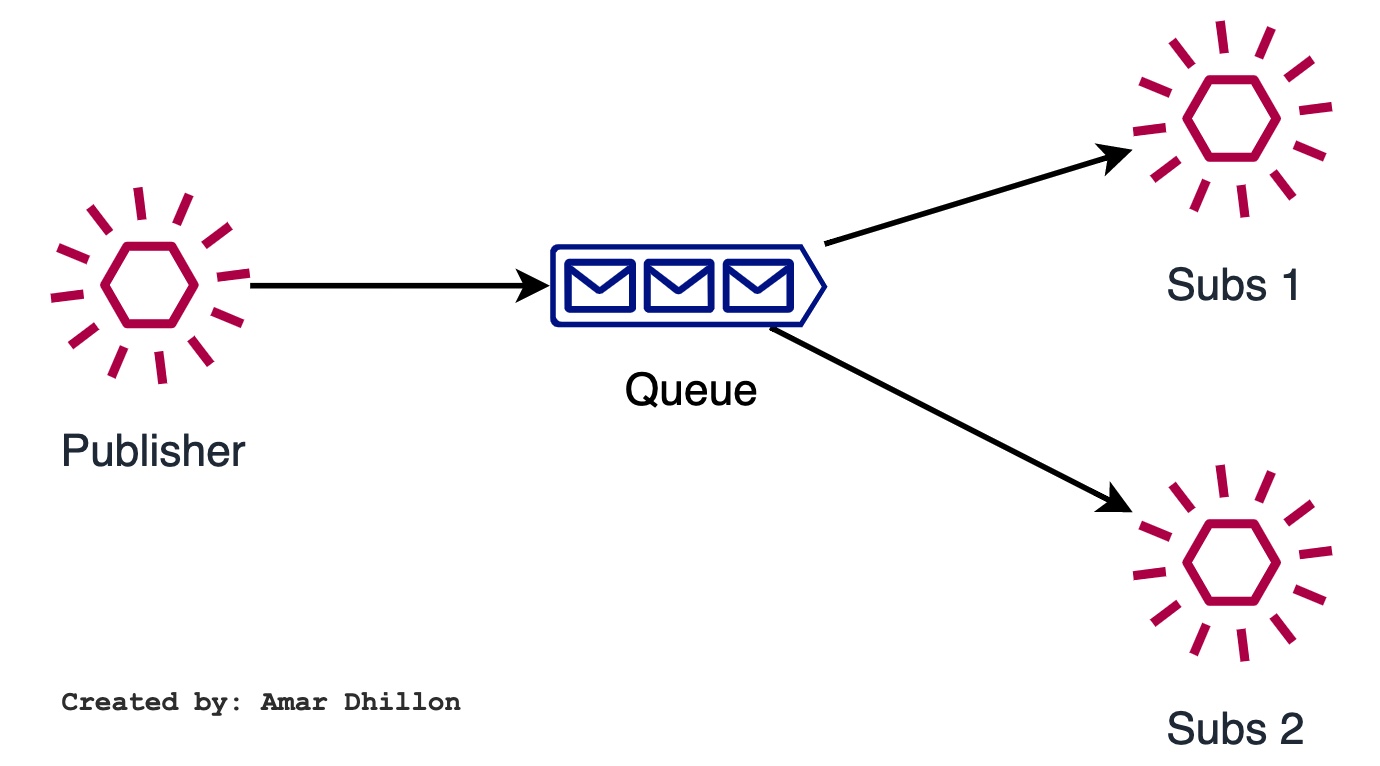
The producer (known as the publisher in this context) has no expectations that the events will result in any action.
Interested consumer(s), can subscribe, listen for events, and take actions depending on their consumption scenario. Events can have multiple subscribers or no subscribers at all. Two different subscribers can react to an event with different actions and not be aware of one another.
The producer and consumer are loosely coupled and managed independently. The consumer isn't expected to acknowledge the event back to the producer. A consumer that is no longer interested in the events, can unsubscribe. The consumer is removed from the pipeline without affecting the producer or the overall functionality of the system.
How loose coupling is ensured?
A message broker provides temporal decoupling. The producer and consumer don't have to run concurrently. A producer can send a message to the message broker regardless of the availability of the consumer. Conversely, the consumer isn't restricted by the producer's availability.
Event publishers¶
Any entity that sends data to an event hub is an event publisher (synonymously used with event producer). Event publishers can publish events using HTTPS or AMQP 1.0 or the Kafka protocol. Event publishers use AAD based authorization with OAuth2-issued JWT tokens or an Event Hub-specific Shared Access Signature (SAS) token to gain publishing access.
HTTPS or AMQP
AMQP requires the establishment of a persistent bidirectional socket in + transport level security (TLS). AMQP has higher network costs when initializing the session, however HTTPS requires extra TLS overhead for every request. AMQP has higher performance for frequent publishers and can achieve much lower latencies when used with asynchronous publishing code.
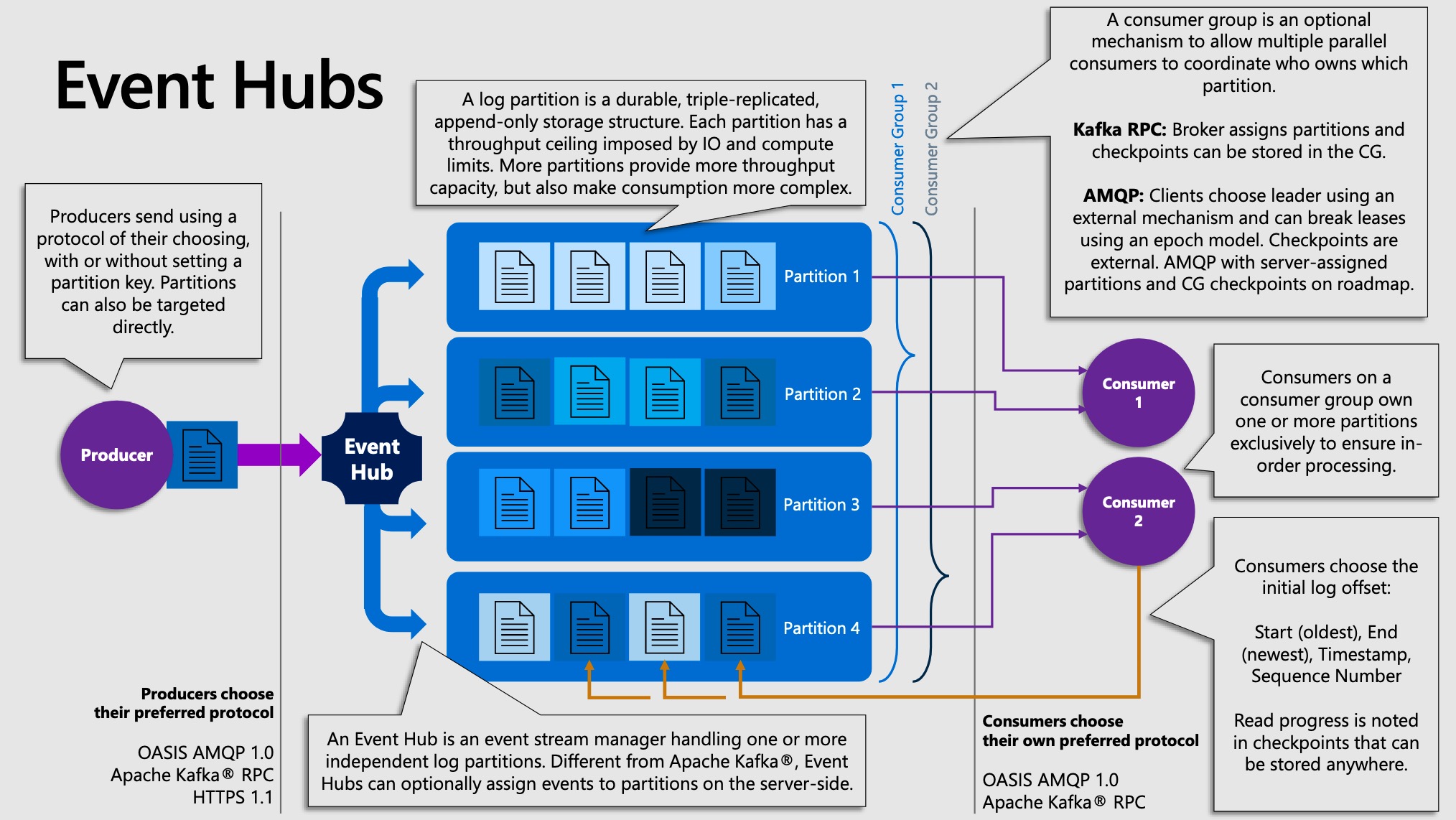
Consumer Groups 🧑🏫¶
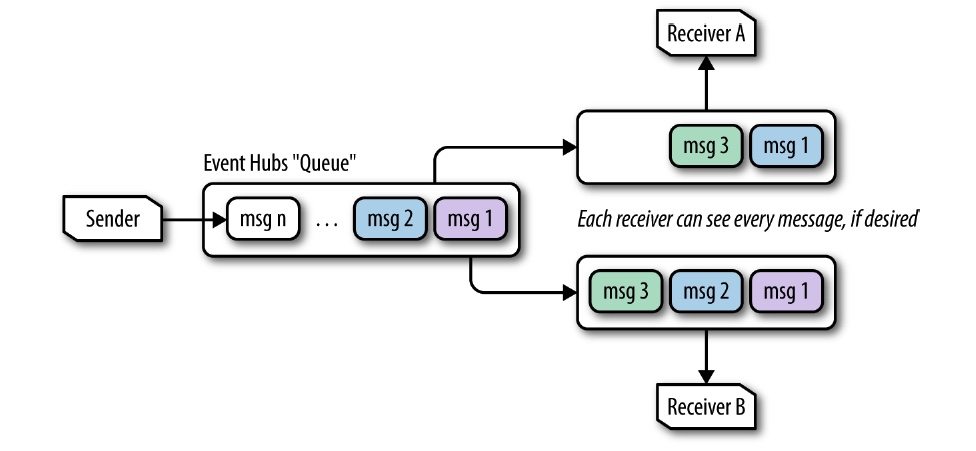
The logical group of consumers that receive messages from each Event Hub partition is called a consumer group. The intention of a consumer group is to represent a single downstream processing application, where that application consists of multiple parallel processes, each consuming and processing messages from a partition.
All consumers must belong to a consumer group. The consumer group also acts to limit concurrent access to a given partition by multiple consumers, which is desired for most applications, because two consumers could mean data is being redundantly processed by downstream components and could have unintended consequences.
A diagam of non-competing consumers is shown below:
Whos responsibility to state management?
In competing consumers, the queue system itself keeps track of the delivery state of every message. In Event Hubs, no such state is tracked, so managing the state of progress through the queue becomes the responsibility of the individual consumer.
Event retention ⬇️¶
Published events are removed from an event hub based on a configurable, timed-based retention policy. Here are a few important points:
- The default value and shortest possible retention period is 1 day (24 hours).
- For Event Hubs Standard, the maximum retention period is 7 days.
- For Event Hubs Premium and Dedicated, the maximum retention period is 90 days.
- If you change the retention period, it applies to all events including events that are already in the event hub
I need to hold my events
If you need to archive events beyond the allowed retention period, you can have them automatically stored in Azure Storage or Azure Data Lake by turning on the Event Hubs Capture feature.
Publisher policy 🧑💼¶
Event Hubs enables granular control over event publishers through publisher policies. Publisher policies are run-time features designed to facilitate large numbers of independent event publishers
Event Hubs Capture 🎏¶
Event Hubs Capture enables you to automatically capture the streaming data in Event Hubs and save it to your choice of either a Blob storage account, or an Azure Data Lake Storage account. You can enable capture from the Azure portal, and specify a minimum size and time window to perform the capture.
Using Event Hubs Capture, you specify your own Azure Blob Storage account and container, or Azure Data Lake Storage account, one of which is used to store the captured data. Captured data is written in the Apache Avro format.
Event Hubs Capture uses Avro format for the data it captures. Avro is a row-oriented format that is suitable for various data types, it's compact, fast, binary, and enables efficient and fast serialization of data.
Partitions 📥¶
Event Hubs organizes sequences of events sent to an event hub into one or more partitions. As newer events arrive, they're added to the end of this sequence.
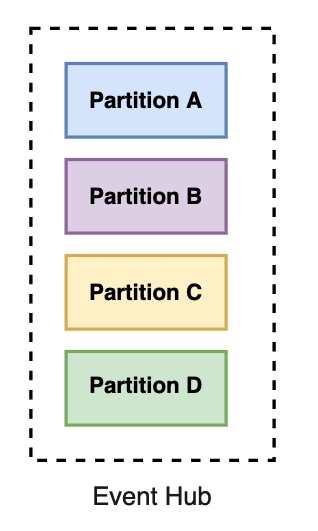
You can't change the partition count for an event hub after its creation except for the event hub in a dedicated cluster and premium tier
A partition can be thought of as a "commit log". Partitions hold event data that contains body of the event, a user-defined property bag describing the event, metadata such as its offset in the partition, its number in the stream sequence, and service-side timestamp at which it was accepted.
Mapping of events to partitions¶
You can use a partition key to map incoming event data into specific partitions for the purpose of data organization. The partition key is a sender-supplied value passed into an event hub. It is processed through a static hashing function, which creates the partition assignment. If you don't specify a partition key when publishing an event, a round-robin assignment is used.
The event publisher is only aware of its partition key, not the partition to which the events are published. This decoupling of key and partition insulates the sender from needing to know too much about the downstream processing.
Throughput units 📦¶
Tldr
The throughput capacity of Event Hubs is controlled by throughput units. Throughput units are pre-purchased units of capacity. A single throughput unit lets you:
Ingress: Up to 1 MB per second or 1000 events per second (whichever comes first).Egress: Up to 2 MB per second or 4096 events per second.
Beyond the capacity of the purchased throughput units, ingress is throttled and a ServerBusyException is returned
Dead-letter queue (DLQ) 💀¶
A Service Bus queue has a default subqueue, called the dead-letter queue (DLQ) to hold messages that couldn't be delivered or processed. Service Bus or the message processing logic in the consumer can add messages to the DLQ. The DLQ keeps the messages until they are retrieved from the queue.
QOS¶
- At least once
- At most once
- Exactly once