Service Registry Pattern ¶
Services discovery in Monolithic/SOA/Microservices¶
Services typically need to call one another.
- In a
monolithic application, services invoke one another through language-level method or procedure calls. - In a traditional
distributed systemSOA deployment, services run at fixed, well known locations (hosts and ports) and so can easily call one another using HTTP/REST or some RPC mechanism. - However, a modern
microservice-based applicationtypically runs in a virtualized or containerized environments where the number of instances of a service and their locations changes dynamically.
Why we need it?¶
Each microservice has a unique name/URL that's used to resolve its location. Your microservice needs to be addressable wherever it's running. In the same way that DNS resolves a URL to a particular computer IP, your microservice needs to have a unique name so that its current location is discoverable.
Handling service failure
If a computer fails, the registry service must be able to indicate where the service is running now.
Caching/Storing the results
The registry is a database containing the network locations of service instances. A service registry needs to be highly available and up-to-date. Clients could cache network locations obtained from the service registry.
Types of service discovery¶
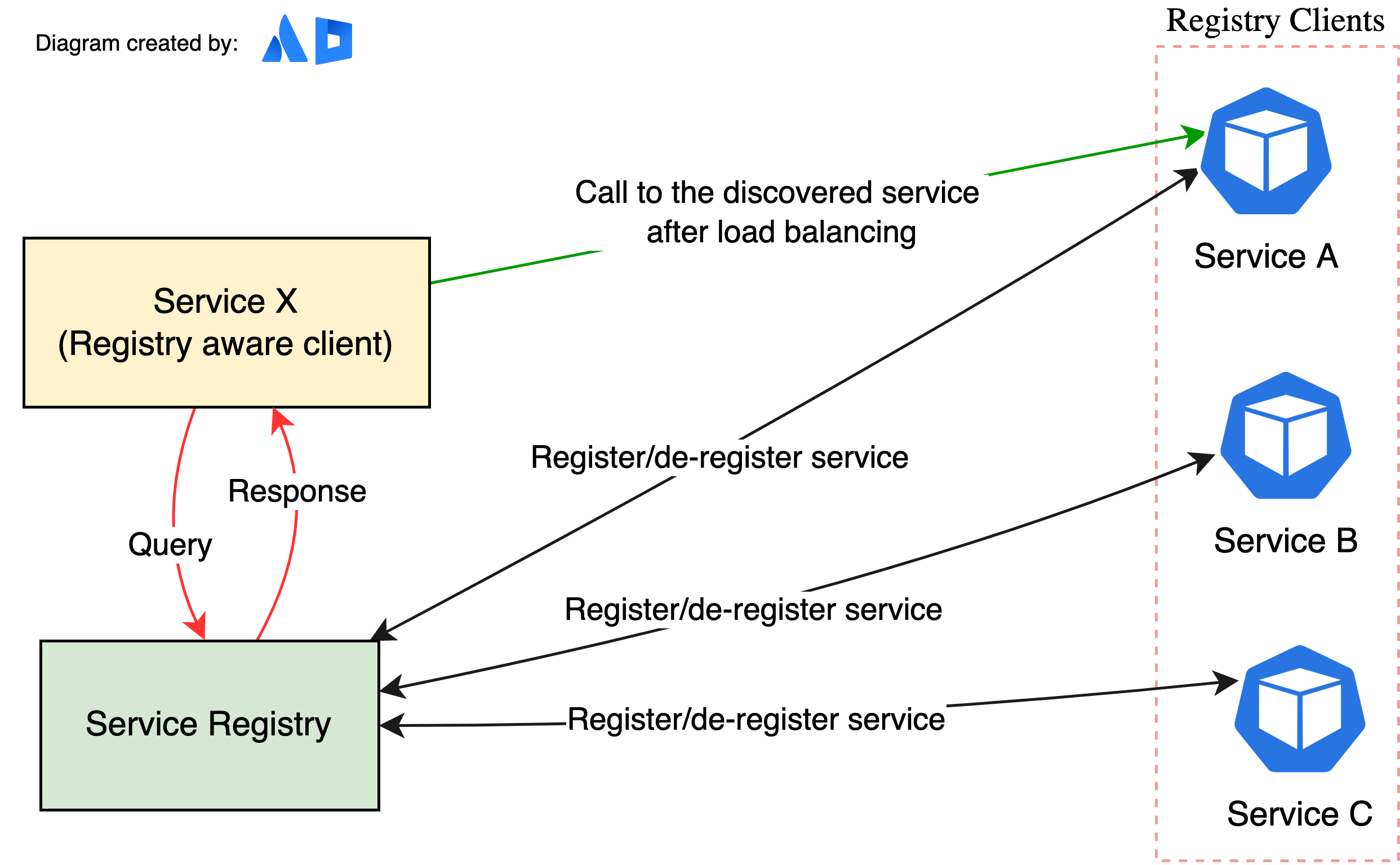
Client-side¶
When using client‑side discovery, the client is responsible for determining the network locations of available service instances and load balancing requests across them. The client queries a service registry, which is a database of available service instances. The client then uses a load‑balancing algorithm to select one of the available service instances and makes a request.
Note
The network location of a service instance is registered with the service registry when it starts up. It is removed from the service registry when the instance terminates. The service instance’s registration is typically refreshed periodically using a heartbeat mechanism.
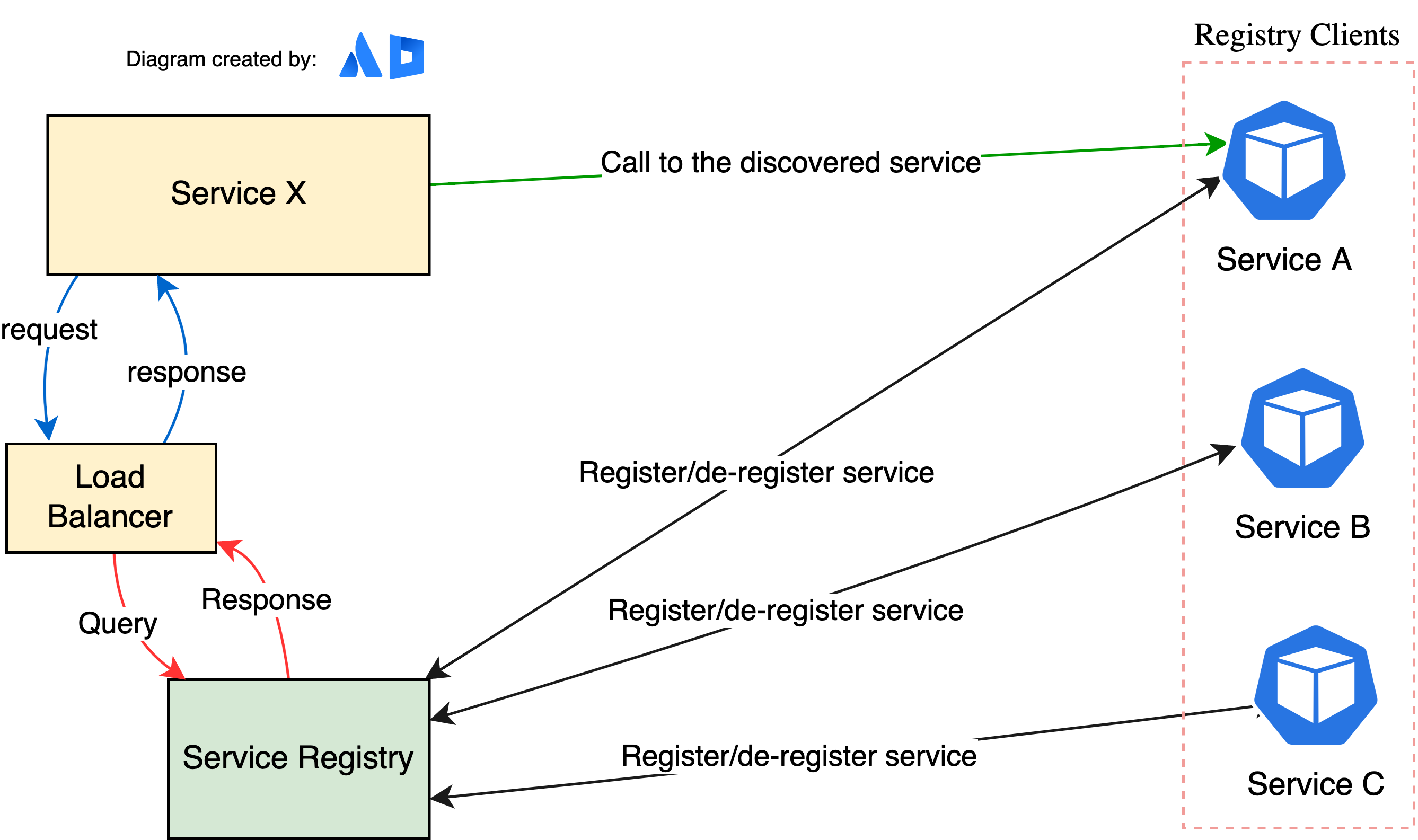
Sever-side¶
When making a request to a service, the client makes a request via a router (a.k.a load balancer) that runs at a well known location. The router queries a service registry, which might be built into the router, and forwards the request to an available service instance.
Registry for AKS¶
Using service registy in AKS
In some microservice deployment environments (called clusters, to be covered in a later section), service discovery is built in. For example, an Azure Kubernetes Service (AKS) environment can handle service instance registration and deregistration. It also runs a proxy on each cluster host that plays the role of server-side discovery router.
servcie discovery example¶
ELB as Service registry and server-side discovery router
An AWS Elastic Load Balancer (ELB) is an example of a server-side discovery router. A client makes HTTP requests (or opens TCP connections) to the ELB, which load balances the traffic amongst a set of EC2 instances. An ELB can load balance either external traffic from the Internet or, when deployed in a VPC, load balance internal traffic.
An ELB also functions as a Service Registry. EC2 instances are registered with the ELB either explicitly via an API call or automatically as part of an auto-scaling group.
Service Registry¶
The service registry is a key part of service discovery. It is a database containing the network locations of service instances.
A service registry needs to be highly available and up to date. Clients can cache network locations obtained from the service registry. However, that information eventually becomes out of date and clients become unable to discover service instances.
How to stay updated?
A service registry consists of a cluster of servers that use a replication protocol to maintain consistency.
Examples¶
-
Netflix Eureka: it is a RESTful (Representational State Transfer) service that is primarily used in the AWS cloud for the purpose of discovery, load balancing and failover of middle-tier servers. It plays a critical role in Netflix mid-tier infra.
-
Etcd – A highly available, distributed, consistent, key‑value store that is used for shared configuration and service discovery. Two notable projects that use etcd are Kubernetes and Cloud Foundry.
-
Consul – A tool for discovering and configuring services. It provides an API that allows clients to register and discover services. Consul can perform health checks to determine service availability.
-
Apache Zookeeper – A widely used, high‑performance coordination service for distributed applications. Apache Zookeeper was originally a subproject of Hadoop but is now a top‑level project.