Form Recognizer¶
What is Azure Document Intelligence?¶
Azure Document Intelligence uses Optical Character Recognition (OCR) capabilities and deep learning models to extract text, key-value pairs, selection marks, and tables from documents.
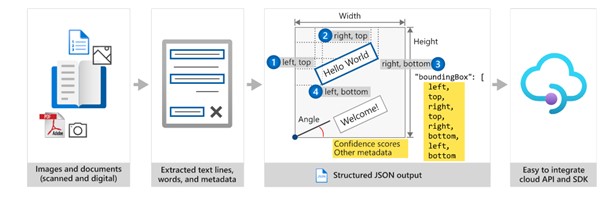
OCR captures document structure by creating bounding boxes around detected objects in an image. The locations of the bounding boxes are recorded as coordinates in relation to the rest of the page. Azure Document Intelligence services return bounding box data and other information in a structured form with the relationships from the original file.

When to use Vison or Document Intelligence?
if you want to extract simple words and text from a picture of a form or document, without contextual information, Azure AI Vision OCR is an appropriate service to consider. If you want to deploy a complete document analysis solution that enables users to both extract and understand text, consider Azure AI Document Intelligence.
Document Intelligence Studio¶
If you want to try many features of Azure AI Document Intelligence without writing any code, you can use Azure AI Document Intelligence Studio. This provides a visual tool for exploring and understanding the capabilities of Azure AI Document Intelligence and its support for your forms.
To integrate Azure AI Document Intelligence into your own applications you'll need to write code. For example, you could enable users of your sales mobile app to scan receipts with their device's camera and call Azure AI Document Intelligence to obtain prices, costs, and custom details. The app could store this information in your customer relationship management database.
How to consume the app¶
When you write an application that uses Azure AI Document Intelligence, you need two pieces of information to connect to the resource:
Endpoint. This is the URL where the resource can be contacted.Access key. This is unique string that Azure uses to authenticate the call to Azure AI Document Intelligence.
Model types¶
Prebuilt¶
Several of the prebuilt models are trained on specific form types:
Invoice model: Extracts common fields and their values from invoices.Receipt model: Extracts common fields and their values from receipts.W2 model: Extracts common fields and their values from the US Government's W2 tax declaration form.ID document model: Extracts common fields and their values from US drivers' licenses and international passports.Business card model: Extracts common fields and their values from business cards.Health insurance card model: Extracts common fields and their values from health insurance cards.
The other models are designed to extract values from documents with less specific structures:
Read model: Extracts text and languages from documents.
The Azure AI Document Intelligence read model extracts printed and handwritten text from documents and images. It's used to provide text extraction in all the other prebuilt models. The read model can also detect the language that a line of text is written in and classify whether it's handwritten or printed text.
General document model: Extract text, keys, values, entities and selection marks from documents.The general document model extends the functionality of the read model by adding the detection of key-value pairs, entities, selection marks, and tables. The model can extract these values from structured, semi-structured, and unstructured documents.
The types of entities you can detect include:
- Person. The name of a person.
- PersonType. A job title or role.
- Location. Buildings, geographical features, geopolitical entities.
- Organization. Companies, government bodies, sports clubs, musical bands, and other groups.
- Event. Social gatherings, historical events, anniversaries.
- Product. Objects bought and sold.
- Skill. A capability belonging to a person.
- Address. Mailing address for a physical location.
- Phone number. Dialing codes and numbers for mobile phones and landlines.
- Email. Email addresses.
- URL. Webpage addresses.
- IP Address. Network addresses for computer hardware.
- DateTime. Calendar dates and times of day.
-
Quantity. Numerical measurements with their units.
-
Layout model: Extracts text and structure information from documents. As well as extracting text, the layout model returns selection marks and tables from the input image or PDF file. It's a good model to use when you need rich information about the structure of a document.
When you digitize a document, it can be at an odd angle. Tables can have complicated structures with or without headers, cells that span columns or rows, and incomplete columns or rows. The layout model can handle all of these difficulties to extract the complete document structure.
Features of prebuilt models¶
The prebuilt models are designed to extract different types of data from the documents and forms users submit. To select the right model for your requirements, you must understand these features:
Text extraction: All the prebuilt models extract lines of text and words from hand-written and printed text.Key-value pairs: Spans of text within a document that identify a label or key and its response or value are extracted by many models as key-values pairs. For example, a typical key might be Weight and its value might be 31 kg.Entities: Text that includes common, more complex data structures can be extracted as entities. Entity types include people, locations, and dates.Selection marks: Spans of text that indicate a choice can be extracted by some models as selection marks. These marks include radio buttons and check boxes.Tables: Many models can extract tables in scanned forms included the data contained in cells, the numbers of columns and rows, and column and row headings. Tables with merged cells are supported.Fields: Models trained for a specific form type identify the values of a fixed set of fields. For example, the Invoice model includes CustomerName and InvoiceTotal fields.
Custom¶
If the prebuilt models don't suit your purposes, you can create a custom model and train it to analyze the specific type of document users will send to your Azure AI Document Intelligence service. The general document analyzer prebuilt models can extract rich information from these forms and you might be able to use them if your requirements are to obtain general data. However, by using a custom model, trained on forms with similar structures and key-value pairs, you will obtain more predictable and standardized results from your unusual form types.
There are two kinds of custom model:
-
Custom template models: A custom template model is most appropriate when the forms you want to analyze have a consistent visual template. If you remove all the user-entered data from the forms and find that the blank forms are identical, use a custom template model. Custom template models support 9 different languages for handwritten text and a wide range of languages for printed text. -
Custom neural models: A custom neural model can work across the spectrum of structured to unstructured documents. Documents like contracts with no defined structure or highly structured forms can be analyzed with a neural model. Neural models work on English with the highest accuracy and a marginal drop in accuracy for Latin based languages like German, French, Italian, Spanish, and Dutch. Try using the custom neural model first if your scenario is addressed by the model.
Composed models¶
A composed model is one that consists of multiple custom models. Typical scenarios where composed models help are when you don't know the submitted document type and want to classify and then analyze it. They are also useful if you have multiple variations of a form, each with a trained individual model. When a user submits a form to the composed model, Document Intelligence automatically classifies it to determine which of the custom models should be used in its analysis.