NLP ¶
Info
Natural language processing (NLP) is a common AI problem in which software must be able to work with text or speech in the natural language form that a human user would write or speak.
Within the broader area of NLP, Natural Language Understanding (NLU) deals with the problem of determining semantic meaning from natural language - usually by using a trained language model.
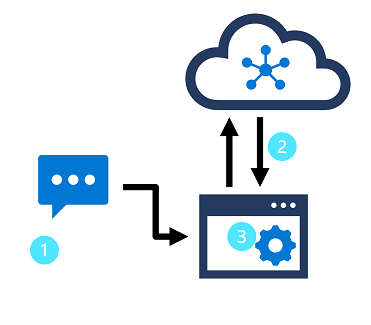
In this design pattern:
- An app accepts natural language input from a user.
- A language model is used to determine semantic meaning (the user's intent).
- The app performs an appropriate action.
Concepts¶
NLP Process
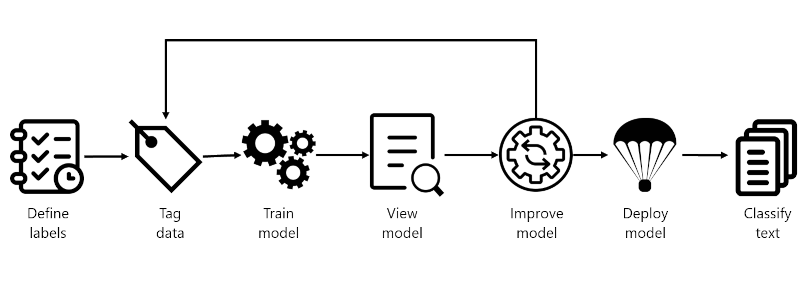
- Define labels: Understanding the data you want to classify, identify the possible labels you want to categorize into. In our video game example, our labels would be "Action", "Adventure", "Strategy", and so on.
- Tag data: Tag, or label, your existing data, specifying the label or labels each file falls under. Labeling data is important since it's how your model will learn how to classify future files. Best practice is to have clear differences between labels to avoid ambiguity, and provide good examples of each label for the model to learn from. For example, we'd label the game "Quest for the Mine Brush" as "Adventure", and "Flight Trainer" as "Action".
- Train model: Train your model with the labeled data. Training will teach our model what types of video game summaries should be labeled which genre.
- View model: After your model is trained, view the results of the model. Your model is scored between 0 and 1, based on the precision and recall of the data tested. Take note of which genre didn't perform well.
- Improve model: Improve your model by seeing which classifications failed to evaluate to the right label, see your label distribution, and find out what data to add to improve performance. For example, you might find your model mixes up "Adventure" and "Strategy" games. Try to find more examples of each label to add to your dataset for retraining your model.
- Deploy model: Once your model performs as desired, deploy your model to make it available via the API. Your model might be named "GameGenres", and once deployed can be used to classify game summaries.
- Classify text: Use your model for classifying text.
Train test split¶
During the Train model step, there are two options for how to train your model.
-
Automatic split- Azure takes all of your data, splits it into the specified percentages randomly, and applies them in training the model. This option is best when you have a larger dataset, data is naturally more consistent, or the distribution of your data extensively covers your classes. -
Manual split- Manually specify which files should be in each dataset. When you submit the training job, the Azure AI Language service will tell you the split of the dataset and the distribution. This split is best used with smaller datasets to ensure the correct distribution of classes and variation in data are present to correctly train your model.
Utterances, Intent and Entity¶
Utterancesare the phrases that a user might enter when interacting with an application that uses your language model.- An
intentrepresents a task or action the user wants to perform, or more simply the meaning of an utterance. You create a model by defining intents and associating them with one or more utterances. Entitiesare used to add specific context to intents. For example, you might define a TurnOnDevice intent that can be applied to multiple devices, and use entities to define the different devices.
| Utterance | Intent | Entities |
|---|---|---|
| What is the time? | GetTime | |
| What time is it in London? | GetTime | Location (London) |
| What's the weather forecast for Paris? | GetWeather | Location (Paris) |
| Will I need an umbrella tonight? | GetWeather | Time (tonight) |
| What's the forecast for Seattle tomorrow? | GetWeather | Location (Seattle), Time (tomorrow) |
| Turn the light on. | TurnOnDevice | Device (light) |
| Switch on the fan. | TurnOnDevice | Device (fan) |
Defining the intent
In your model, you must define the intents that you want your model to understand, so spend some time considering the domain your model must support and the kinds of actions or information that users might request. In addition to the intents that you define, every model includes a None intent that you should use to explicitly identify utterances that a user might submit, but for which there is no specific action required (for example, conversational greetings like "hello") or that fall outside of the scope of the domain for this model.
After you've identified the intents your model must support, it's important to capture various different example utterances for each intent. Collect utterances that you think users will enter; including utterances meaning the same thing but that are constructed in different ways. Keep these guidelines in mind:
- Capture multiple different examples, or alternative ways of saying the same thing
- Vary the length of the utterances from short, to medium, to long
- Vary the location of the noun or subject of the utterance. Place it at the beginning, the end, or somewhere in between
- Use correct grammar and incorrect grammar in different utterances to offer good training data examples
- The precision, consistency and completeness of your labeled data are key factors to determining model performance.
Label precisely: Label each entity to its right type always. Only include what you want extracted, avoid unnecessary data in your labels.Label consistently: The same entity should have the same label across all the utterances.Label completely: Label all the instances of the entity in all your utterances.
In some cases, a model might contain multiple intents for which utterances are likely to be similar. You can use the pattern of utterances to disambiguate the intents while minimizing the number of sample utterances.
For example, consider the following utterances:
- "Turn on the kitchen light"
- "Is the kitchen light on?"
- "Turn off the kitchen light"
These utterances are syntactically similar, with only a few differences in words or punctuation. However, they represent three different intents (which could be named TurnOnDevice, GetDeviceStatus, and TurnOffDevice).
To correctly train your model, provide a handful of examples of each intent that specify the different formats of utterances
TurnOnDevice:
"Turn on the {DeviceName}"
"Switch on the {DeviceName}"
"Turn the {DeviceName} on"
GetDeviceStatus:
"Is the {DeviceName} on[?]"
TurnOffDevice:
"Turn the {DeviceName} off"
"Switch off the {DeviceName}"
"Turn off the {DeviceName}"
Classification types¶
Custom text classification assigns labels, which in the Azure AI Language service is a class that the developer defines, to text files. For example, a video game summary might be classified as "Adventure", "Strategy", "Action" or "Sports".
Custom text classification falls into two types of projects:
Single label classification- you can assign only one class to each file. Following the above example, a video game summary could only be classified as "Adventure" or "Strategy".Multiple label classification- you can assign multiple classes to each file. This type of project would allow you to classify a video game summary as "Adventure" or "Adventure and Strategy".
NER¶
An entity is a person, place, thing, event, skill, or value. Custom named entity recognition (NER) is an Azure API service that looks at documents, identifies, and extracts user defined entities. These entities could be anything from names and addresses from bank statements to knowledge mining to improve search results.
Azure AI Language provides certain built-in entity recognition, to recognize things such as a person, location, organization, or URL. Built-in NER allows you to set up the service with minimal configuration, and extract entities. To call a built-in NER, create your service and call the endpoint for that NER service like this:
Service Types¶
Azure AI Language service features fall into two categories:
- Pre-configured features
- Learned features require building and training a model to correctly predict appropriate labels, which is covered in upcoming units of this module.
Pre-Configured¶
The Azure AI Language service provides certain features without any model labeling or training. Once you create your resource, you can send your data and use the returned results within your app.
The following features are all pre-configured.
Summarization¶
Summarization is available for both documents and conversations, and will summarize the text into key sentences that are predicted to encapsulate the input's meaning.
Named entity recognition¶
Named entity recognition can extract and identify entities, such as people, places, or companies, allowing your app to recognize different types of entities for improved natural language responses. For example, given the text "The waterfront pier is my favorite Seattle attraction", Seattle would be identified and categorized as a location.
Personally identifiable information (PII) detection¶
PII detection allows you to identify, categorize, and redact information that could be considered sensitive, such as email addresses, home addresses, IP addresses, names, and protected health information. For example, if the text "email@contoso.com" was included in the query, the entire email address can be identified and redacted.
Key phrase extraction¶
Key phrase extraction is a feature that quickly pulls the main concepts out of the provided text. For example, given the text "Text Analytics is one of the features in Azure AI Services.", the service would extract "Azure AI Services" and "Text Analytics".
Sentiment analysis¶
Sentiment analysis identifies how positive or negative a string or document is. For example, given the text "Great hotel. Close to plenty of food and attractions we could walk to", the service would identify that as positive with a relatively high confidence score.
Language detection¶
Language detection takes one or more documents, and identifies the language for each. For example, if the text of one of the documents was "Bonjour", the service would identify that as French.
Deploy Model¶
Use the REST API
One way to build your model is through the REST API. The pattern would be to create your project, import data, train, deploy, then use your model.
These tasks are done asynchronously; you'll need to submit a request to the appropriate URI for each step, and then send another request to get the status of that job.
For example, if you want to deploy a model for a conversational language understanding project, you'd submit the deployment job, and then check on the deployment job status.
Request deployment
Submit a POST request to the following endpoint. HTTP
{ENDPOINT}/language/authoring/analyze-conversations/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}?api-version={API-VERSION}
| Placeholder | Value | Example |
|---|---|---|
| {ENDPOINT} | The endpoint of your Azure AI Language resource | https:// |
| {PROJECT-NAME} | The name for your project. This value is case-sensitive | AmarsProject |
| {DEPLOYMENT-NAME} | The name for your deployment. This value is case-sensitive | staging |
| {API-VERSION} | The version of the API you're calling | 2023-05-01 |
Analyze Text
To query your model using REST, create a POST request to the appropriate URL with the appropriate body specified. For built in features such as language detection or sentiment analysis, you'll query the analyze-text endpoint.