Vision ¶
Services¶
The Azure AI Vision service is designed to help you extract information from images. It provides functionality that you can use for:
-
Description and tag generation- determining an appropriate caption for an image, and identifying relevant "tags" that can be used as keywords to indicate its subject. -
Object detection- detecting the presence and location of specific objects within the image. -
People detection- detecting the presence, location, and features of people in the image. -
Image metadata, color, and type analysis- determining the format and size of an image, its dominant color palette, and whether it contains clip art. -
Category identification- identifying an appropriate categorization for the image, and if it contains any known landmarks. -
Background removal- detecting the background in an image and output the image with the background transparent or a greyscale alpha matte image. -
Moderation rating- determine if the image includes any adult or violent content. -
Optical character recognition- reading text in the image. -
Smart thumbnail generation- identifying the main region of interest in the image to create a smaller "thumbnail" version.
Facial Service¶
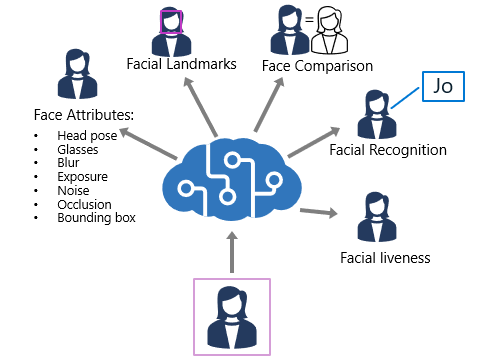
The Face service provides functionality that you can use for:
-
Face detection- for each detected face, the results include an ID that identifies the face and the bounding box coordinates indicating its location in the image. Face attribute analysis - you can return a wide range of facial attributes, including: Head pose (pitch, roll, and yaw orientation in 3D space) Glasses (NoGlasses, ReadingGlasses, Sunglasses, or Swimming Goggles) Blur (low, medium, or high) Exposure (underExposure, goodExposure, or overExposure) Noise (visual noise in the image) Occlusion (objects obscuring the face) -
Facial landmark location- coordinates for key landmarks in relation to facial features (for example, eye corners, pupils, tip of nose, and so on) -
Face comparison- you can compare faces across multiple images for similarity (to find individuals with similar facial features) and verification (to determine that a face in one image is the same person as a face in another image) Facial recognition- you can train a model with a collection of faces belonging to specific individuals, and use the model to identify those people in new images.
Face GUID
When a face is detected by the Face service, an ID is assigned to it and retained in the service resource for 24 hours. The ID is a GUID, with no indication of the individual's identity other than their facial features.
Implement facial recognition¶
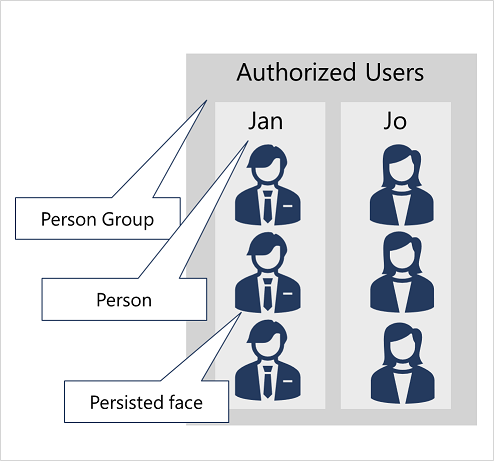
To train a facial recognition model with the Face service:
- Create a Person Group that defines the set of individuals you want to identify (for example, employees).
- Add a Person to the Person Group for each individual you want to identify.
- Add detected faces from multiple images to each person, preferably in various poses. The IDs of these faces will no longer expire after 24 hours (so they're now referred to as persisted faces).
- Train the model.
OCR¶
OCR allows you to extract text from images, such as photos of street signs and products, as well as from documents — invoices, bills, financial reports, articles, and more.
The Azure AI Vision service offers two APIs that you can use to read text.
- The Read API
- The Read API can be used to process PDF formatted files.
- Its ideal for this scenario: You need to read a large amount of text with high accuracy. Some of the text is handwritten in English and some of it is printed in multiple languages.
- There are more than
160 languagesavailable for printed text via the Read API. - The Image Analysis API
Remember
The Read function returns an operation ID, which you can use in a subsequent call to the Get Read Results function in order to retrieve details of the text that has been read. Depending on the volume of text, you may need to poll the Get Read Results function multiple times before the operation is complete.
Azure Video Indexer¶
Azure Video Indexer is a service to extract insights from video, including face identification, text recognition, object labels, scene segmentations, and more.
Azure OpenAI Service provides access to OpenAI's powerful large language models such as ChatGPT, GPT, Codex, and Embeddings models. These models enable various natural language processing (NLP) solutions to understand, converse, and generate content. Users can access the service through REST APIs, SDKs, and Azure OpenAI Studio.
--
Azure OpenAI Service provides access to OpenAI's powerful large language models such as ChatGPT, GPT, Codex, and Embeddings models. These models enable various natural language processing (NLP) solutions to understand, converse, and generate content. Users can access the service through REST APIs, SDKs, and Azure OpenAI Studio.
- OpenAI Studio: It provides access to model management, deployment, experimentation, customization, and learning resources.
Azure OpenAI includes several types of model:
GPT-4models are the latest generation of generative pretrained (GPT) models that can generate natural language and code completions based on natural language prompts.GPT 3.5models can generate natural language and code completions based on natural language prompts. In particular, GPT-35-turbo models are optimized for chat-based interactions and work well in most generative AI scenarios.Embeddings modelsconvert text into numeric vectors, and are useful in language analytics scenarios such as comparing text sources for similarities.DALL-E modelsare used to generate images based on natural language prompts. Currently, DALL-E models are in preview. DALL-E models aren't listed in the Azure OpenAI Studio interface and don't need to be explicitly deployed.
Prompts and completions
- A prompt is the text portion of a request that is sent to the deployed model's completions endpoint
- Responses are referred to as completions, which can come in form of text, code, or other formats.
Here's an example of a simple prompt and completion.
Prompt Engineering With prompt-based models, the user interacts with the model by entering a text prompt, to which the model responds with a text completion. This completion is the model’s continuation of the input text.