MLOPS Basics ¶
MLaaS¶
MLaaS describes a variety of machine learning capabilities that are delivered via the cloud. Vendors in the MLaaS market offer tools like image recognition, voice recognition, data visualization, and deep learning.A user typically uploads data to a vendor’s cloud, and then the machine learning computation is processed on the cloud
Model Training¶
2 kinds of model training
Offline/Static Model training¶
- A
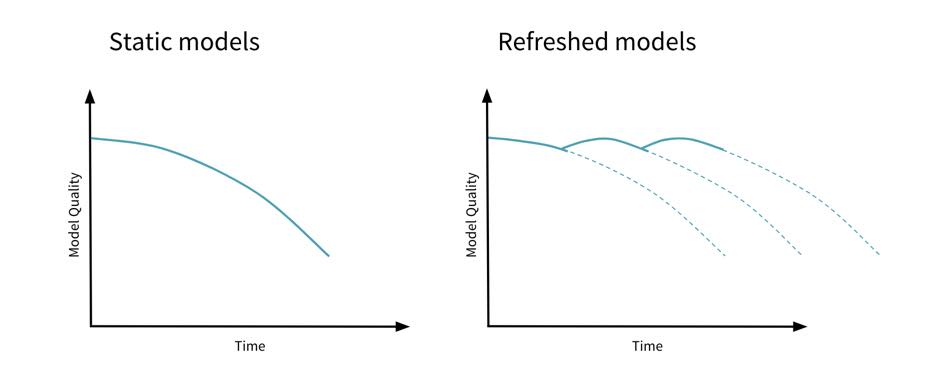
static modelis trained offline. That is, we train the model exactly once and then use that trained model for a while. - This one is easy to build and test - use batch traing and test, iterate until good
- This can go stale
Info
Currently, the majority of machine learning models are offline. These offline models are trained using trained data and then deployed. After an offline model is deployed, the underlying model doesn’t change as it is exposed to more data. The problem with offline models is that they presume the incoming data will remain fairly consistent.
Over the next few years, you will see more machine learning models available for use. As these models are constantly updated with new data, the better the models will be at predictive analytics. However, preferences and trends change, and offline models can’t adapt as the incoming data changes. For example, take the situation where a machine learning model makes predictions on the likelihood that a customer will churn. The model could have been very accurate when it was deployed, but as new, more flexible competitors emerge, and once customers have more options, their likelihood to churn will increase. Because the original model was trained on older data before new market entrants emerged, it will no longer give the organization accurate predictions. On the other hand, if the model is online and continuously adapting based on incoming data, the predictions on churn will be relevant even as preferences evolve and the market landscape changes.
Online/Dynamic Model Training¶
- A
dynamic modelis trained online. That is, data is continually entering the system and we're incorporating that data into the model through continuous updates. - We need to feed training data over time
- Use Progressive Validation rather than batch training and test
- Needs monitoring, model rollback and data quarantine capabilities
- Staleness is avoided.
Model Inference¶
Offline Inference¶
Offline inference, meaning that you make all possible predictions in a batch, using a MapReduce or something similar. You then write the predictions to an SSTable or Bigtable, and then feed these to a cache/lookup table.
Issues
We can only predict about the things we know about, for the data that we dont know we cant make the prediction
Online Inference¶
Online inference, meaning that you predict on demand, using a server (model stored in a server).- More extensive monitoring needs to be setup.
- Having a feedback loop from a monitoring system, and refreshing models over time, will help avoid model staleness.
Success
They can predict any new data that comes in - good for long tailing.
Model Selection¶
Model Deployment¶
Model deployment is the process of making a machine learning model available for use on a target environment—for testing or production.
Optimization Steps¶
- Using GPU's instead of CPU's when required. In addition to GPUs, researchers are using Field-Programmable Gate Arrays (FPGAs) to successfully run machine learning workloads. Sometimes FPGAs outperform GPUs when running neural network and deep learning operations