Azure ML¶
AML Workspace¶
The workspace is the top-level resource for Azure Machine Learning, providing a centralized place to work with all the artifacts you create.
When you create a new workspace, it automatically creates below Azure resources:
Storage account: It used to store files used by the workspace as well as data forexperimentsandmodel training. It Is used as thedefault datastorefor the workspace. Jupyter notebooks that are used with your Azure Machine Learning compute instances are stored here as well.Application Insights: It is used to monitor predictive services in the workspace.Key Vault instance: Storessecretsthat are used by compute targets and other sensitive information that's needed by the workspace.Container/Model registry, used to manage containers for deployed models.VMs: provide computing power for your AzureML workspace and are an integral part in deploying and training models.Load Balancer: anetwork load balanceris created for each compute instance and compute cluster to manage traffic even while the compute instance/cluster is stopped.Virtual Network: these help Azure resources communicate with one another, the internet, and other on-premises networks.
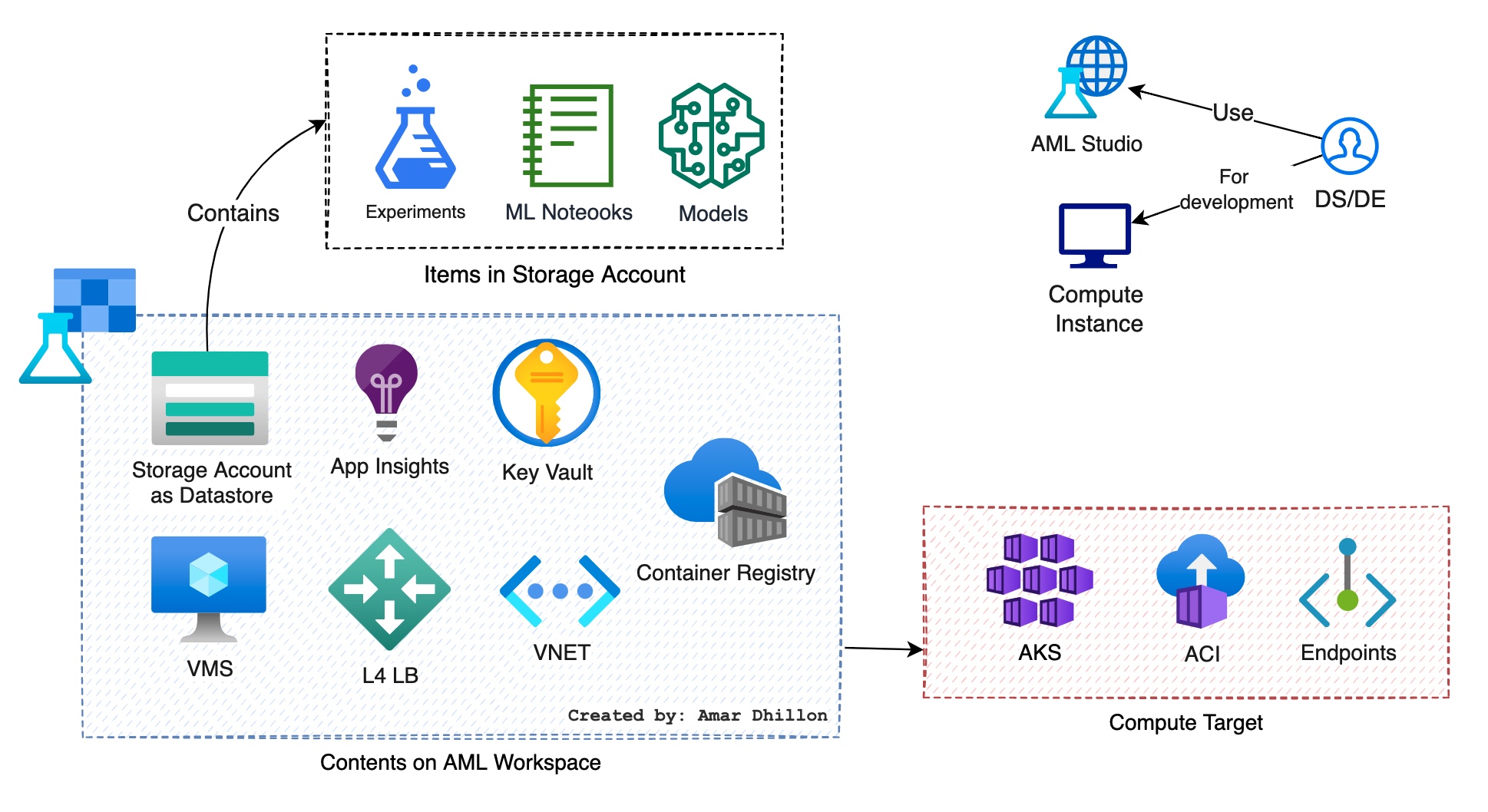
Other components:¶
Compute Instance¶
It is a managed cloud-based workstation for data scientists. Each compute instance has only one owner, although you can share files between multiple compute instances. They can be used for dev and test purposes.
Compute Target¶
it is a designated compute resource or environment where you run your training script or host your service deployment. This location might be your local machine or a cloud-based compute resource.
Types of Compute Targets
- Local — This is used to run the experiment on the
same compute targetas the code used to initiate the experiment. - Training Cluster — for high scalable training requirements — distributed computes, CPU/GPU are enabled and scaled on-demand.
- Inference Cluster — containerized clusters to deploy the inference of the trained model as an overall application module.
- Attached Compute — to attach already acquired Azure ML VM or Databricks machine
Training Cluster¶
- AML compute instance
- AML compute cluster
- AKS
- Databricks
- Batch
Inference Cluster¶
Docker container is created before inference
When performing inference, AML creates a Docker container that hosts the model and associated resources needed to use it. This container is then used in a compute target.
Various inference compute target can be:
AML endpoints: Fully managed computes for real-time (managed online endpoints) and batch scoring (batch endpoints) on serverless compute.AKS: use managed k8sACI: Run docker container without orchestrator
AML Concepts¶
Model deployment¶
After you train an ML model, you need to deploy the model so that others can use it to do inferencing. In Azure Machine Learning, you can use endpoints and deployments to do so.
Endpoint¶
Info
An endpoint is an HTTPS endpoint that clients can call to receive the inferencing (scoring) output of a trained model. It provides:
- Authentication using "key & token" based auth
- SSL termination
- A stable scoring URI (endpoint-name.region.inference.ml.azure.com)
Deployment¶
A deployment is a set of resources required for hosting the model that does the actual inferencing.
Remember
A single endpoint can contain multiple deployments. Endpoints and deployments are independent Azure Resource Manager resources that appear in the Azure portal.
Real-time/batch scoring¶
-
Batch scoring, or batch inferencing, involves invoking an endpoint with a reference to data. The batch endpoint runs jobs asynchronously to process data in parallel on compute clusters and store the data for further analysis -
Real-time scoring, or online inferencing, involves invoking an endpoint with one or more model deployments and receiving a response in near-real-time via HTTPs. Traffic can be split across multiple deployments, allowing for testing new model versions by diverting some amount of traffic initially and increasing once confidence in the new model is established.
CLI V2¶
The AML CLI v2 is the latest extension for the Azure CLI. The CLI v2 provides commands in the format az ml <noun> <verb> <options> to create and maintain Azure ML assets and workflows. The assets or workflows themselves are defined using a YAML file. The YAML file defines the configuration of the asset or workflow – what is it, where should it run, and so on.
az ml job create --file my_job_definition.yaml
az ml environment update --name my-env --file my_updated_env_definition.yaml
az ml model list
az ml compute show --name my_compute
AML Pipelines¶
Pipelines are workflows of complete machine learning tasks that can be run independently. The Azure Machine Learning pipeline service automatically orchestrates all the dependencies between pipeline steps.
You can create pipelines without using components, but components offer better amount of flexibility and reuse. Azure ML Pipelines may be defined in YAML and run from the CLI, authored in Python, or composed in Azure ML Studio Designer with a drag-and-drop UI.
Experiment¶
An Experiment is a container of trials that represent multiple model runs.
Environment¶
AMl environments are an encapsulation of the environment where your ML training happens. They specify the Python packages, environment variables, and software settings around your training and scoring scripts. They also specify runtimes (Python, Spark, or Docker).
Environments can broadly be divided into three categories:
- Curated: They are provided by Azure Machine Learning and are available in your workspace by default. Intended to be used as is, they contain collections of Python packages and settings to help you get started with various machine learning frameworks
- User-managed: In this you're responsible for setting up your environment and installing every package that your training script needs on the compute target.
- System-managed: Conda will manage env.
build the env to docker
AML builds environment definitions into Docker images and conda environments. It also caches the environments, so they can be reused in subsequent training jobs and service endpoint deployments.
AML Studio¶
AML Designer¶
We can use the designer to train and deploy ML models without writing any code. Drag and drop datasets and components to create ML pipelines.
Component¶
An Azure Machine Learning component is a self-contained piece of code that does one step in a machine learning pipeline. Components are the building blocks of advanced machine learning pipelines. Components can do tasks such as data processing, model training, model scoring, and so on.
A component is analogous to a function - it has a name, parameters, expects input, and returns output.
AMl Compute¶
A compute is a designated compute resource where you run your job or host your endpoint. Azure Machine learning supports the following types of compute:
Compute cluster- a managed-compute infrastructure that allows you to easily create a cluster of CPU or GPU compute nodes in the cloud.Compute instance- a fully configured and managed development environment in the cloud. You can use the instance as a training or inference compute for development and testing. It's similar to a virtual machine on the cloudInference cluster- used to deploy trained machine learning models to Azure Kubernetes Service. You can create an Azure Kubernetes Service (AKS) cluster from your Azure ML workspace, or attach an existing AKS cluster.Attached compute- You can attach your own compute resources to your workspace and use them for training and inference.
Datastore¶
Azure Machine Learning datastores securely keep the connection information to your data storage on Azure, so you don't have to code it in your scripts. You can register and create a datastore to easily connect to your storage account, and access the data in your underlying storage service. The CLI v2 and SDK v2 support the following types of cloud-based storage services:
- Azure Blob Container
- Azure File Share
- Azure Data Lake
- Azure Data Lake Gen2
MLFlow¶
MLflow is an open-source framework that's designed to manage the complete ML lifecycle. Its ability to train and serve models on different platforms allows you to use a consistent set of tools regardless of where your experiments are running: locally on your computer, on a remote compute target, on a virtual machine, or on an AML compute instance.
Model¶
Azure machine learning models consist of the binary file(s) that represent a machine learning model and any corresponding metadata. Models can be created from a local or remote file or directory. For remote locations https, wasbs and azureml locations are supported
The created model will be tracked in the workspace under the specified name and version. Azure ML supports 3 types of storage format for models:
- custom_model
- mlflow_model
- triton_model
Difference between Artifacts and Models
Any file generated (and captured) from an experiment's run or job is an artifact. It may represent a model serialized as a Pickle file, the weights of a PyTorch or TensorFlow model, or even a text file containing the coefficients of a linear regression
ONNX format¶
It is the Open Neural Network Exchange format.
Who created ONNX and why?
Microsoft and a community of partners created ONNX as an open standard for representing ML models. Models from many frameworks including TensorFlow, PyTorch, SciKit-Learn, Keras, Chainer, MXNet, MATLAB, and SparkML can be exported or converted to the standard ONNX format. Once the models are in the ONNX format, they can be run on a variety of platforms and devices.
ONNX Runtime: It is a high-performance inference engine for deploying ONNX models to production. It's optimized for both cloud and edge and works on Linux, Windows, and Mac.
MLOPS¶
DevOps for machine learning models, often called MLOps, is a process for developing models for production. A model's lifecycle from training to deployment must be auditable if not reproducible.
Model training lifecycle¶
The Azure training lifecycle consists of:
- Zipping the files in your project folder, ignoring those specified in
.amlignoreor.gitignore - Scaling up your
compute cluster - Building or downloading the
dockerfileto thecompute node- The system calculates a hash of:
- The base image
- Custom docker steps
- The conda definition YAML
- The system uses this hash as the key in a lookup of the workspace
Azure Container Registry (ACR) - If it is not found, it looks for a match in the
global ACR - If it is not found, the system builds a new image (which will be cached and registered with the
workspace ACR)
- The system calculates a hash of:
- Downloading your zipped project file to temporary storage on the
compute node. - Unzipping the project file.
- The compute node executing
python <entry script> <arguments> - Saving logs, model files, and other files written to
./outputsto the storage account associated with the workspace. - Scaling down compute, including removing temporary storage.