GenAI ¶
GenAI Use Cases¶
- Text summarization
- Rewriting
- Information extraction
- Classification and content moderation
- Translation: Java to Python for example
- Source code generation: code from hand writtern sketch
- Reasoning
- Mark PII
GenAI Concepts¶
Generative / Discriminative model¶
A generative AI model could be trained on a dataset of images of cats and then used to generate new images of cats. A discriminative AI model could be trained on a dataset of images of cats and dogs and then used to classify new images as either cats or dogs.
Foundation model¶
A foundation model is a large AI model pre-trained on a vast quantity of data that was "designed to be adapted” (or fine-tuned) to a wide range of downstream tasks, such as sentiment analysis, image captioning, and object recognition.
Examples - Llama 2 from Meta - Falcon
Info
Foundation models are very large and complex neural network models consisting of billions of parameters (a.k.a. weights). The model parameters are learned during the training phase—often called pretraining. Foundation models are trained on massive amounts of training data—typically over a period of many weeks and months using large, distributed clusters of CPUs and graphics processing units (GPUs). After learning billions of parameters, these foundation models can represent complex entities such as human language, images, videos, and audio clips
Prompt 🎹¶
A prompt is a short piece of text that is given to the large language model as input, and it can be used to control the output of the model in many ways.
What is completion?
This prompt is passed to the model during inference time to generate a completion
Prompt Engineering¶
Prompt engineering is a practice used to guide an LLM’s response by querying the model in a more specific way. For example, instead of merely asking a model to “create a quarterly report,” a user could provide specific figures or data in their input, providing context and leading the LLM to a more relevant and accurate output. However, copying large amounts of information into an LLM’s input is not only cumbersome but is also limited by constraints on the amount of text that can be inputted into these models at once.
This is where the concept of “search and retrieval” can enhance LLM capabilities. By pairing LLMs with an efficient search and retrieval system that has access to your proprietary data, you can overcome the limitations of both static training data and manual input. This approach is the best of both worlds, combining the expansive knowledge of LLMs with the specificity and relevance of your own data, all in real-time.
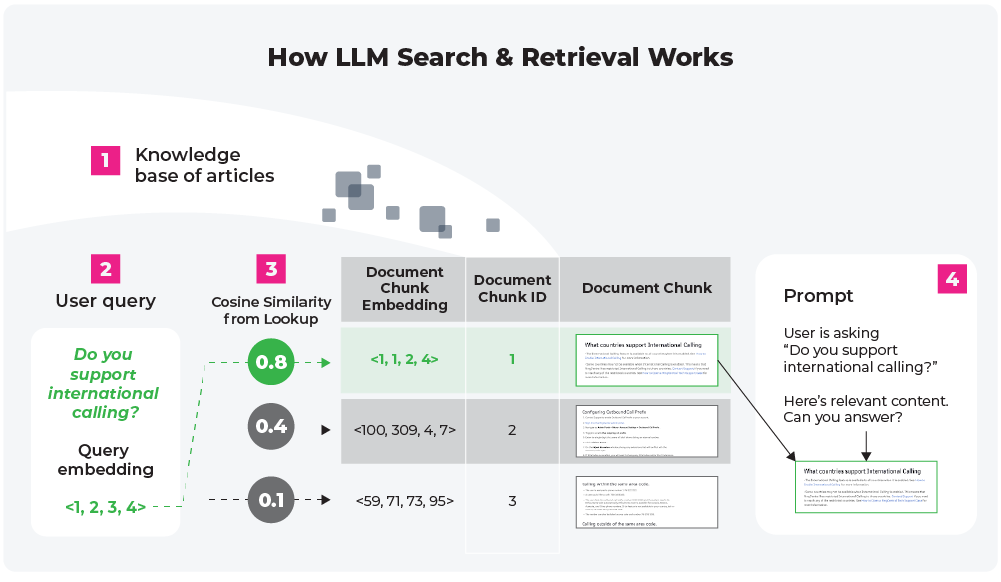
Tokens 🍪¶
It’s important to note that while text-based prompts and completions are implemented and interpreted by humans as natural language sentences, generative models convert them into sequences of tokens.
By combining many of these tokens in different ways, the model is capable of representing an exponential number of words using a relatively small number of tokens often on the order of 30,000–100,000 tokens in the model’s vocabulary.
From the model’s standpoint, a document is simply just a sequence of tokens from the model’s vocabulary.
Embeddings¶
We see embeddings as fundamental to AI and deep learning. Embeddings are the core of how deep learning models represent structures, mappings, hierarchy and manifolds that are learned by models.
They proliferate modern deep learning from transformers to encoders, decoders, auto-encoders, recommendation engines, matrix decomposition, SVD, graph neural networks, and generative models — they are simply everywhere.
Embeddings are dense, low-dimensional representations of high-dimensional data. They are an extremely powerful tool for input data representation, compression, and cross-team collaboration. They show you relationships in unstructured data, such as the example below showing that from word embeddings we learn man is to woman as king is to queen (from the corpus the vectors were trained on).
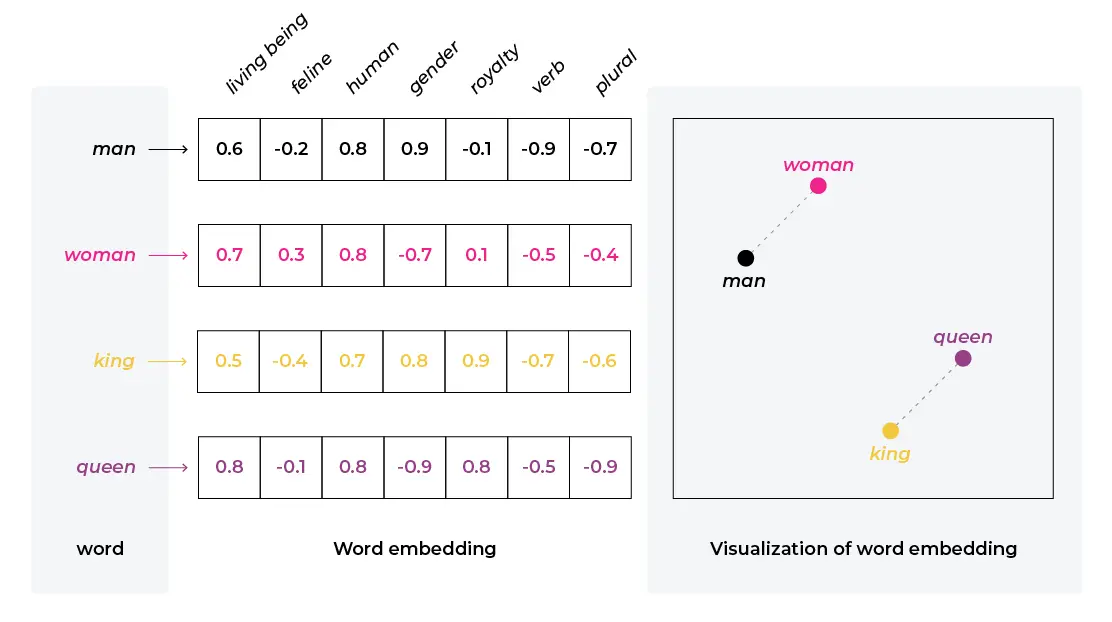
Embeddings are foundational because:
- They provide a common mathematical representation of your data
- They compress your data
- They preserve relationships within your data
- They are the output of deep learning layers providing comprehensible linear views into complex non-linear relationships learned by models
n-Shot Learning 💉¶
Zero Shot Lerarning 0️⃣¶
Zero-shot learning is a technique in which a machine learning model can recognize and classify new concepts without any labeled examples — hence zero shots. The model leverages knowledge transfer from pre-training on large unlabeled datasets.
One Shot Lerarning 1️⃣¶
LangChain ⛓¶
LangChain is an open source framework for building applications based on large language models (LLMs).
LLMs are large deep-learning models pre-trained on large amounts of data that can generate responses to user queries, for example, answering questions or creating images from text-based prompts.
LangChain provides tools and abstractions to improve the customization, accuracy, and relevancy of the information the models generate. For example, developers can use LangChain components to build new prompt chains or customize existing templates.
LangChain also includes components that allow LLMs to access new data sets without retraining.
Agents, Chains ⛓️¶
What are AI agents? Agents are used in LLMs as a reasoning engine to determine which actions to take and in which order to take them. So instead of using an LLM directly, you can use an agent and give it access to a set of tools and context to deliver a sequence based on your intended task
Why use an agent instead of a LLM directly? Agents offer benefits like memory, planning, and learning over time.
What are complex agents? However, complex agents require more complex testing scenarios and engineering to build and maintain. These architectures may include modules for memory, planning, learning over time, and iterative processing
What is a chain?
A chain is a sequence of calls to components that can be combined to create a single, coherent application. For example, we can create a chain that takes user input, formats it with a prompt template, and then passes the formatted response to an LLM.
Custom Chaining? What happens when an applications requires not just a predetermined chain of calls to LLMs, but potentially an unknown chain that depends on the user's input?
In these types of chains, there is an “agent” which has access to a suite of tools.
Depending on the user input, the agent can then decide which, if any, of these tools to call.
LLM Frameworks
Frameworks like LlamaIndex and LangChain are great for leveraging agents when developing applications powered by LLMs.
ReAct(Reason + Act) Agent Architecture The Reason and Action (ReAct) framework: 1.Has the agent reason over the next action 2.Constructs a command 3.Executes the action
RAG¶
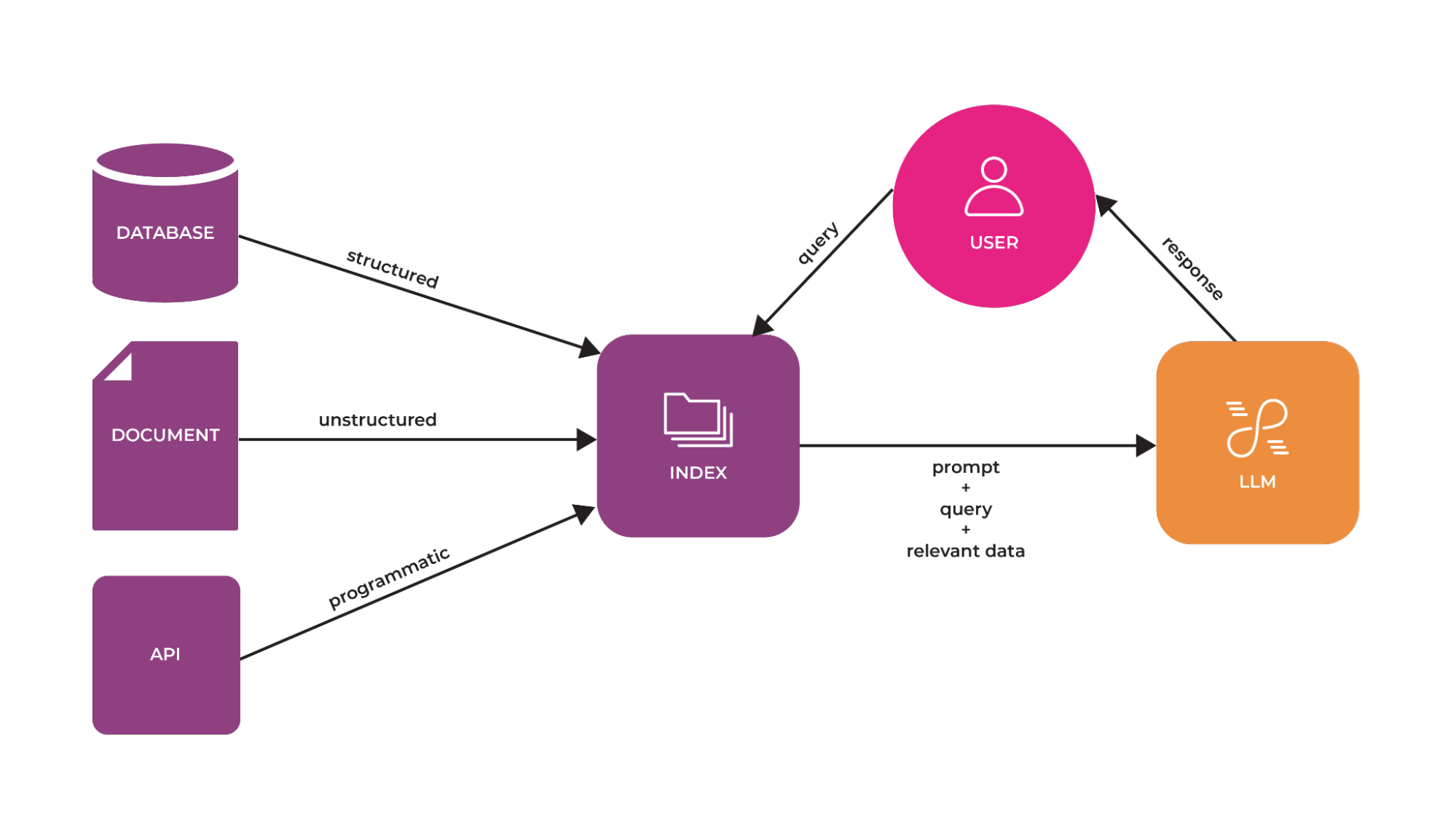
LLMs are trained on vast datasets, but these will not include your specific data (things like company knowledge bases and documentation). Retrieval-Augmented Generation (RAG) addresses this by dynamically incorporating your data as context during the generation process.
This is done not by altering the training data of the LLMs but by allowing the model to access and utilize your data in real-time to provide more tailored and contextually relevant responses.
In RAG, your data is loaded and prepared for queries. This process is called indexing. User queries act on this index, which filters your data down to the most relevant context. This context and your query then are sent to the LLM along with a prompt, and the LLM provides a response.
RAG is a critical component for building applications such a chatbots or agents and you will want to know RAG techniques on how to get data into your application.
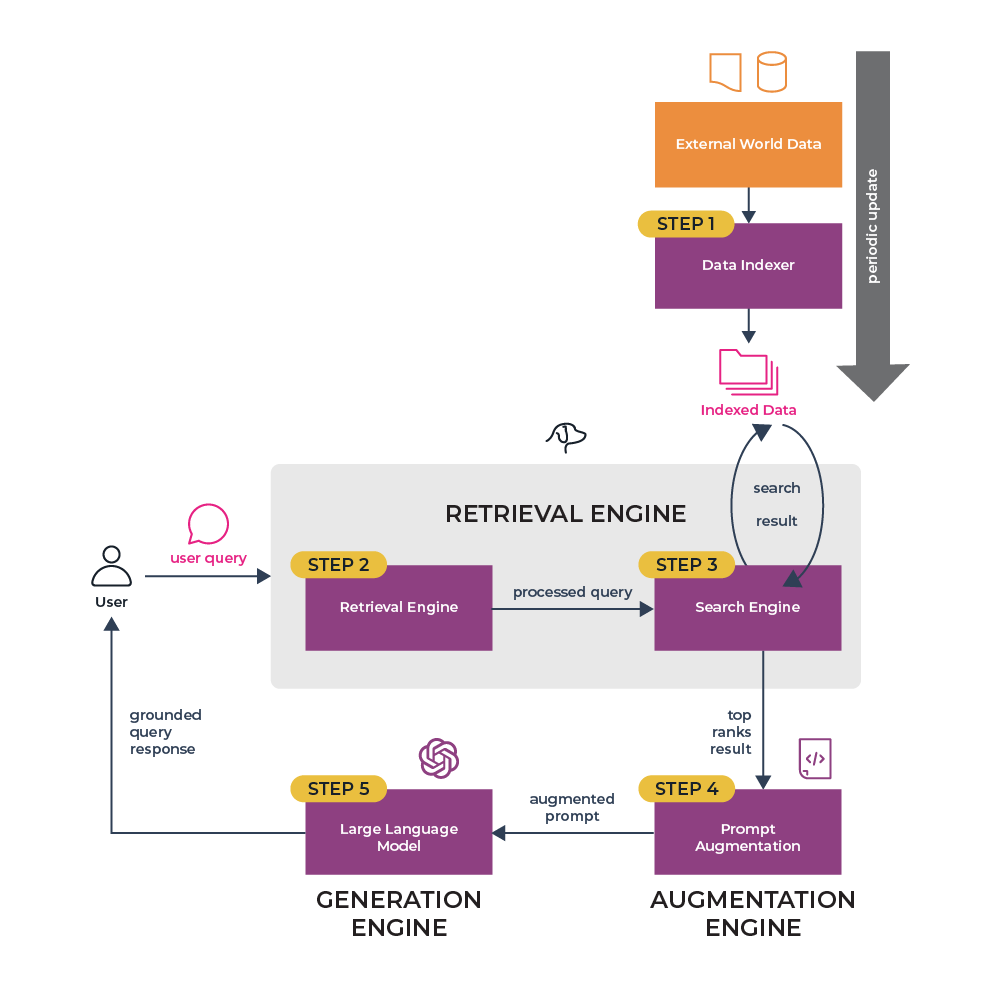
Context Aware RAG¶
RAG Steps¶
To ensure accuracy and relevance, there are six stages to follow within RAG that will in turn be a part of any larger RAG application.
-
Data Indexing: Before RAG can retrieve information, the data must be aggregated and organized in an index. This index acts as a reference point for the retrieval engine.
-
Input Query Processing: The user’s input is processed and understood by the system, forming the basis of the search query for the retrieval engine.
-
Search and Ranking: The retrieval engine searches the indexed data and ranks the results in terms of relevance to the input query.
-
Prompt Augmentation: The most relevant information is then combined with the original query. This augmented prompt serves as a richer source for response generation.
-
Response Generation: Finally, the generation engine uses this augmented prompt to create an informed and contextually accurate response.
-
Evaluation: A critical step in any pipeline is checking how effective it is relative to other strategies, or when you make changes. Evaluation provides objective measures on accuracy, faithfulness, and speed of responses.
By following these steps, RAG systems can provide answers that are not just accurate but also reflect the most current and relevant information available. This process is adaptable to both online and offline modes, each with its unique applications and advantages.
Vector Stores 🧮¶
Vector stores and embeddings are used for RAG to efficiently retrieve relevant information from external data sources to augment the data used by a generative model
Example: - Amazon OpenSearch Serverless - Amazon Kendra
GenAI Project Lifecycle ♼¶
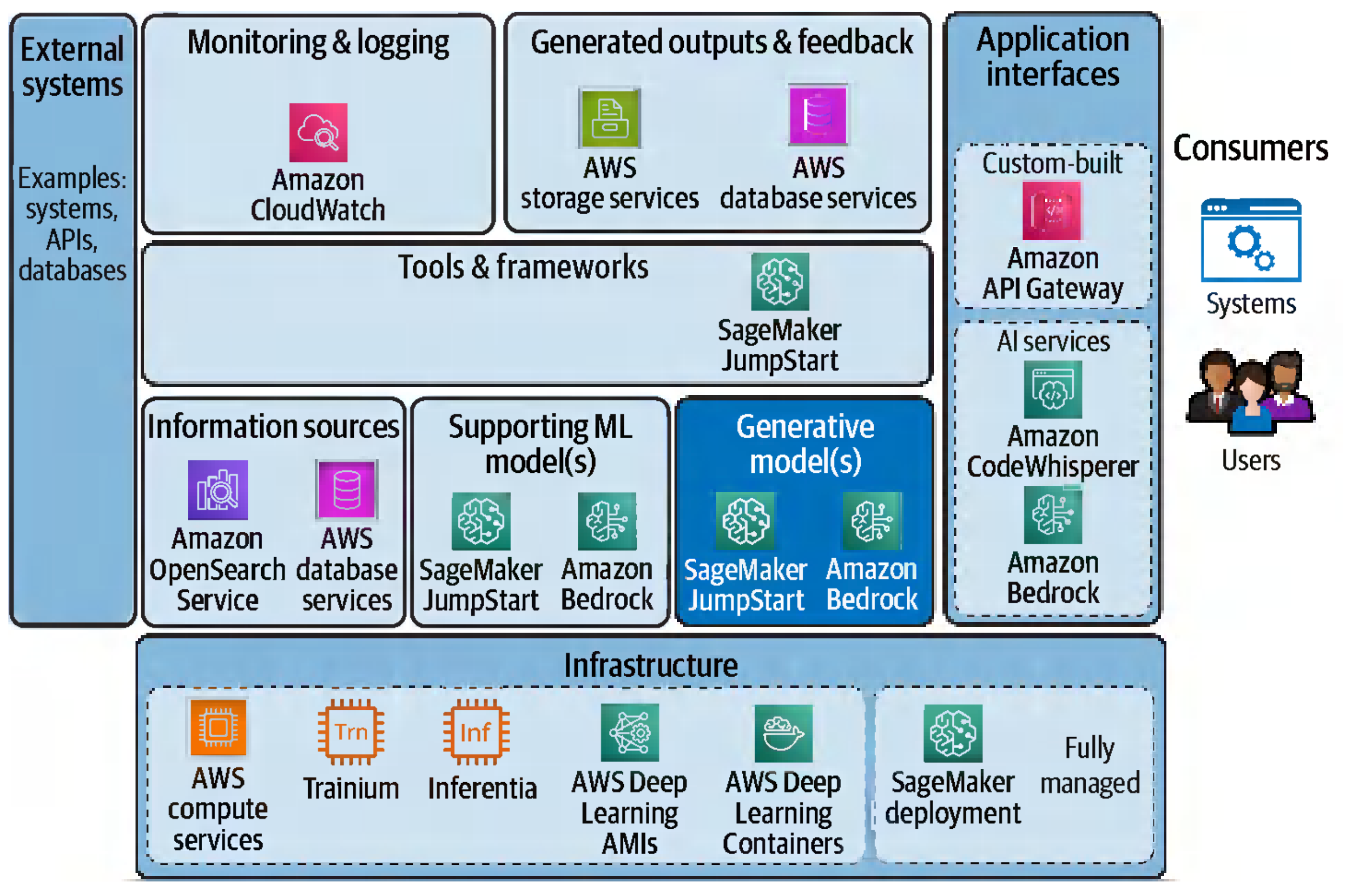
Deployment Optimization 📦¶
Pruning 🎄¶
Pruning is a technique that focuses on removing redundant, or low-impact, parameters that do not contribute, or contribute little, to the model’s performance. Pruning reduces the size of the model, but also increases performance by reducing the number of computations during inference.
How is pruning done?
The model weights to be eliminated during pruning are those with a value of zero or very close to zero. Pruning during training is accomplished through unstructured pruning (removing weights) or structured pruning (removing entire columns or rows of the weight matrices).
Quantization 🔬¶
Quantization converts a model’s weights from high precision (e.g., 32-bit) to lower precision (e.g., 16-bit).
This not only reduces the model’s memory footprint, but also improves model performance by working with smaller number representations. With large generative models, it’s common to reduce the precision further to 8 bits to increase inference performance.
PTQ
Post Training Quantization (PTQ) aims to transform the model’s learned weights into a lower-precision representation with the goals of reducing the model’s size and the compute requirements when hosting generative models for inference.
Distillation 🧪¶
Distillation trains a smaller student model from a larger teacher model. The smaller model is then used for inference to reduce your compute resources yet retain a high percentage of accuracy of your student model.
The end result is a student model that retains a high percentage of the teacher’s model accuracy but uses a much smaller number of parameters. The student model is then deployed for inference. The smaller model requires smaller hardware and therefore less cost per inference request.
Example
A popular distilled student model is DistilBERT from Hugging Face. DistilBERT was trained from the larger BERT teacher model and is an order of magnitude smaller than BERT, yet it retains approximately 97% of the accuracy of the original BERT model.