LLM as a Judge 🧑⚖️¶
LLM-as-a-Judge is a powerful solution that uses LLMs to evaluate LLM responses based on any specific criteria of your choice, which means using LLMs to carry out LLM (system) evaluation.
Potential issues with using LLM as a Judge?
The non-deterministic nature of LLMs implies that even with controlled parameters, outputs may vary, raising concerns about the reliability of these judgments.
prompt = """
You will be given 1 summary (LLM output) written for a news article published in Ottawa Daily.
Your task is to rate the summary on how coherent it is to the original text (input).
Original Text:
{input}
Summary:
{llm_output}
Score:
"""
LLM Metrics 📊¶
-
Recall@k: It measures the proportion of all relevant documents retrieved in the top k results, and is crucial for ensuring the system captures a high percentage of pertinent information. -
Precision@k: It complements this by measuring the proportion of retrieved documents that are relevant. -
Mean Average Precision (MAP): It provides an overall measure of retrieval quality across different recall levels. -
Normalized Discounted Cumulative Gain (NDCG): It is particularly valuable as it considers both the relevance and ranking of retrieved documents.
LLM Metric Types ⎐¶
Metrics for LLM calls can be broken up into two categories
- Absolute
- Subjective
Absolute Metrics¶
These metrics like latency, throughput, etc are easier to calculate.
Subjective Metrics¶
They are more difficult to calculate. These subjective categories range from truthfulness, faithfulness, answer relevancy, to any custom metric your business cares about.
How to find the relavancy for Subjective metrics?
Typically, in all the subjective metrics, it requires a level of human reasoning to determine a numeric answer. Techniques used for evaluation are:
1. Human Evaluators¶
This is a time intensive process although sometimes its considered as gold standard. It requires humans to go through and evaluate your answer. You need to select the humans carefully and make sure their instructions on how to grade are clear
It’s not unusual for a real-world LLM application to generate approximately 100,000 responses a month. I don’t know about you, but it takes me about 60 seconds on average to read through a few paragraphs and make a judgment about it. That adds up to around 6 million seconds, or about 65 consecutive days each month — without taking lunch breaks — to evaluate every single generated LLM responses.
2. LLM's as a Judge¶
To use LLM-as-a-judge, you have to iterate on a prompt until the human annotators generally agree with the LLMs grades. An evaluation dataset should be created and graded by a human.
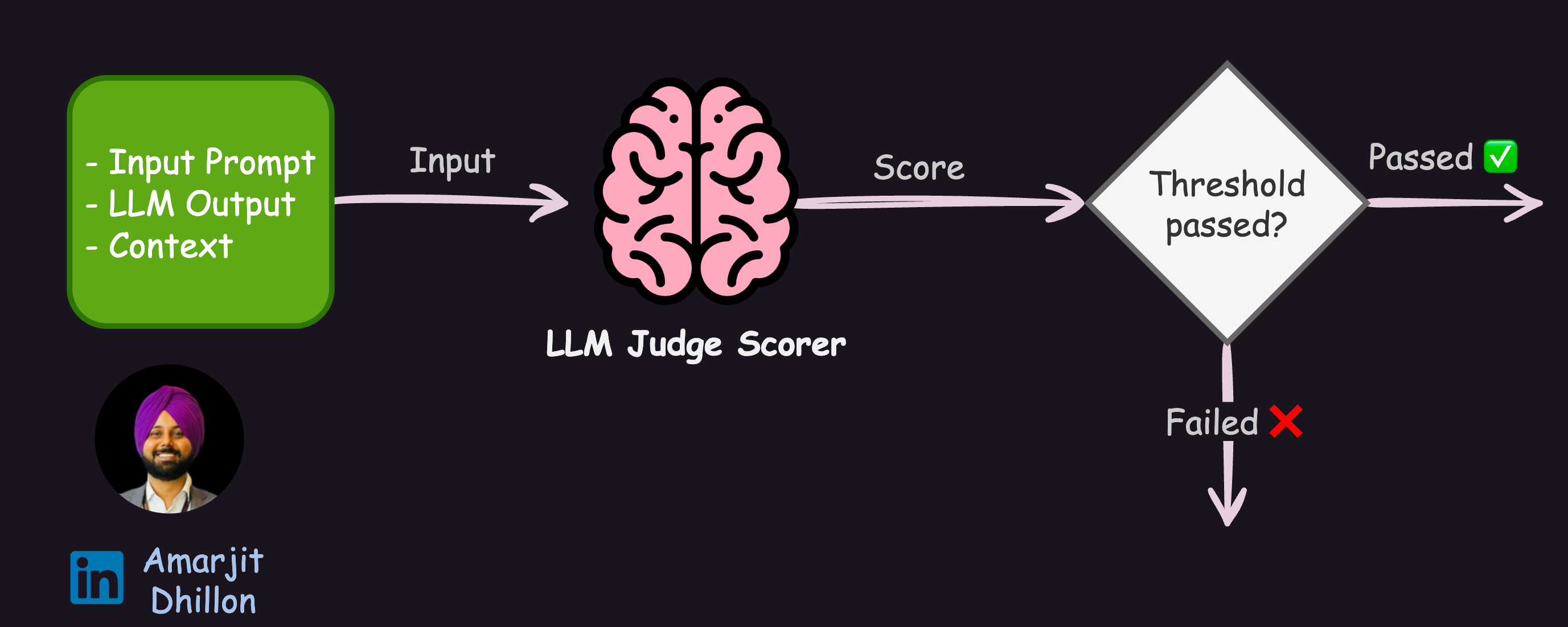
Single Layer Judge ·¶
The flow for single layer Judge is shown below
Muti Layered Judgements ⵘ¶
We can also use a master LLM judge to judge the judgement of First level Judge for getting better recall
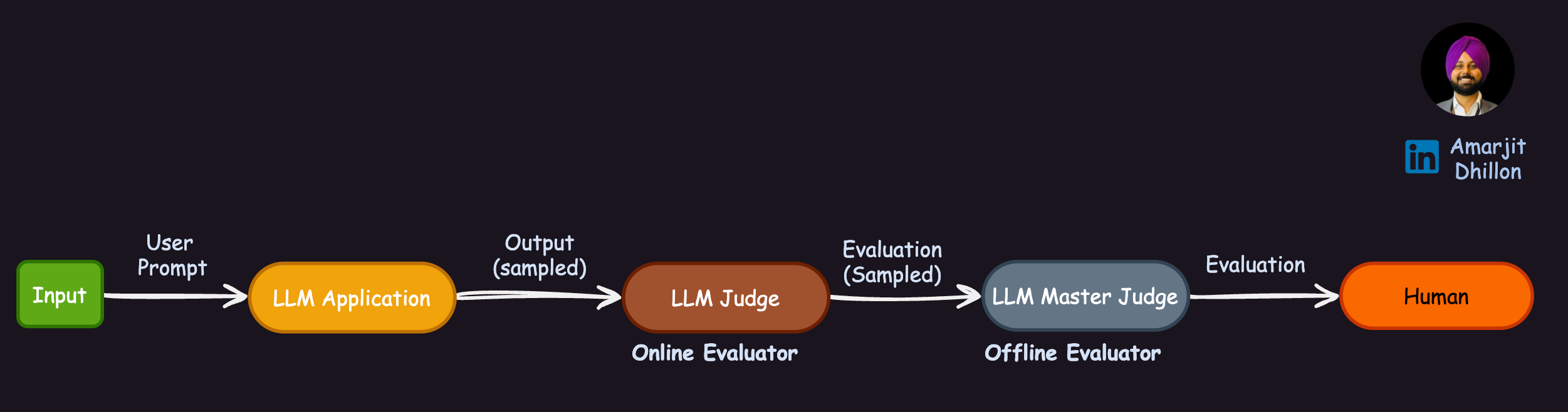
Why are we using Sampling?
It is also worth noting that using a random sampling method for evaluation might be a good approach to save resources
How to improve LLM Judgements? 📈¶
- Use
Chain of Thought (CoT)Prompting by asking the reasoning process - Use
Few shot Prompting: This approach can be more computationally expensive - Provide a
reference guide for Judgements - Evaluate based on
QAG (Question Answer Generation)