SageMaker features a capability called Bring Your Own Container (BYOC), which allows you to run custom Docker containers on the inference endpoint. These containers must meet specific requirements, such as running a web server that exposes certain REST endpoints, having a designated container entrypoint, setting environment variables, etc. Writing a Dockerfile and serving script that meets these requirements can be a tedious task.
How MLFlow integrates with S3 and ECR?
MLflow automates the process by building a Docker image from the MLflow Model on your behalf. Subsequently, it pushed the image to Elastic Container Registry and creates a SageMaker endpoint using this image. It also uploads the model artifact to an S3 bucket and configures the endpoint to download the model from there.
The container provides the same REST endpoints as a local inference server. For instance, the /invocations endpoint accepts CSV and JSON input data and returns prediction results.
It’s recommended to test your model locally before deploying it to a production environment. The mlflow deployments run-local command deploys the model in a Docker container with an identical image and environment configuration, making it ideal for pre-deployment testing.
The mlflow deployments create command deploys the model to an Amazon SageMaker endpoint. MLflow uploads the Python Function model to S3 and automatically initiates an Amazon SageMaker endpoint serving the model.
Amazon SageMaker uses domains to organize user profiles, applications, and their associated resources. An Amazon SageMaker domain consists of the following:
An associated Amazon Elastic File System (Amazon EFS) volume.
A list of authorized users.
A variety of security, application, policy, and Amazon Virtual Private Cloud (Amazon VPC) configurations.
Endpoints: Multi model endpoint, Multi container endpoint.
Inference: Based on traffic patterns, we can have following
Real time: For persistent, one prediction at time
Serverless: Workloads which can tolerate idle periods between spikes and can tolerate cold starts
Batch: To get predictions for an entire dataset, use SageMaker batch transform
Async: Requests with large payload sizes up to 1GB, long processing times, and near real-time latency requirements, use Amazon SageMaker Asynchronous Inference
Batch inference refers to model inference performed on data that is in batches, often large batches, and asynchronous in nature. It fits use cases that collect data infrequently, that focus on group statistics rather than individual inference, and that do not need to have inference results right away for downstream processes.
Projects that are research oriented, for example, do not require model inference to be returned for a data point right away. Researchers often collect a chunk of data for testing and evaluation purposes and care about overall statistics and performance rather than individual predictions. They can conduct the inference in batches and wait for the prediction for the whole batch to complete before they move on
Doing batch transform in S3 🪣
Depending on how you organize the data, SageMaker batch transform can split a single large text file in S3 by lines into a small and manageable size (mini-batch) that would fit into the memory before making inference against the model; it can also distribute the files by S3 key into compute instances for efficient computation.
SageMaker batch transform saves the results after assembly to the specified S3 location with .out appended to the input filename.
Amazon SageMaker Asynchronous Inference is a capability in SageMaker that queues incoming requests and processes them asynchronously. This option is ideal for requests with large payload sizes (up to 1GB), long processing times (up to one hour), and near real-time latency requirements. Asynchronous Inference enables you to save on costs by autoscaling the instance count to zero when there are no requests to process, so you only pay when your endpoint is processing requests.
In today's fast-paced digital environment, receiving inference results for incoming data points in real-time is crucial for effective decision-making.
Take interactive chatbots, for instance; they rely on live inference capabilities to operate effectively. Users expect instant responses during their conversations—waiting until the discussion is over or enduring delays of even a few seconds is simply not acceptable.
For companies striving to deliver top-notch customer experiences, ensuring that inferences are generated and communicated to customers instantly is a top priority.
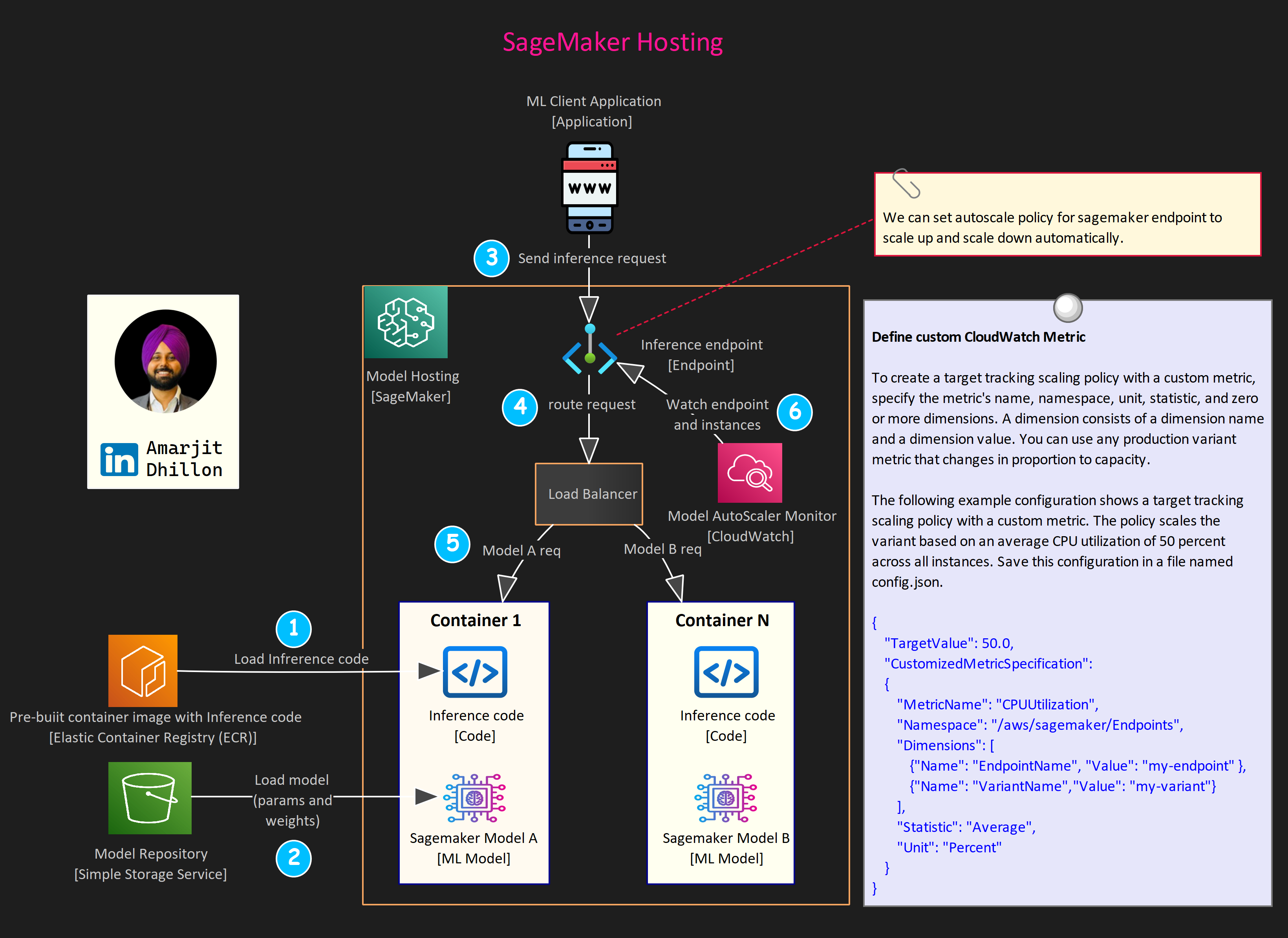
The deployment process consists of the following steps:
Create a model, container, and associated inference code in SageMaker. The model refers to the training artifact, model.tar.gz. The container is the runtime environment for the code and the model.
Create an HTTPS endpoint configuration. This configuration carries information about compute instance type and quantity, models, and traffic patterns to model variants.
Create ML instances and an HTTPS endpoint. SageMaker creates a fleet of ML instances and an HTTPS endpoint that handles the traffic and authentication. The final step is to put everything together for a working HTTPS endpoint that can interact with client-side requests.
On-demand Serverless Inference is ideal for workloads which have idle periods between traffic spurts and can tolerate cold starts. Serverless endpoints automatically launch compute resources and scale them in and out depending on traffic, eliminating the need to choose instance types or manage scaling policies. This takes away the undifferentiated heavy lifting of selecting and managing servers.
Serverless Inference integrates with AWS Lambda to offer you high availability, built-in fault tolerance and automatic scaling. With a pay-per-use model, Serverless Inference is a cost-effective option if you have an infrequent or unpredictable traffic pattern.
During times when there are no requests, Serverless Inference scales your endpoint down to 0, helping you to minimize your costs.
Possible cold-start during updating serverless endpoint
Note that when updating your endpoint, you can experience cold starts when making requests to the endpoint because SageMaker must re-initialize your container and model.
Amazon SageMaker automatically scales in or out on-demand serverless endpoints. For serverless endpoints with Provisioned Concurrency you can use Application Auto Scaling to scale up or down the Provisioned Concurrency based on your traffic profile, thus optimizing costs.
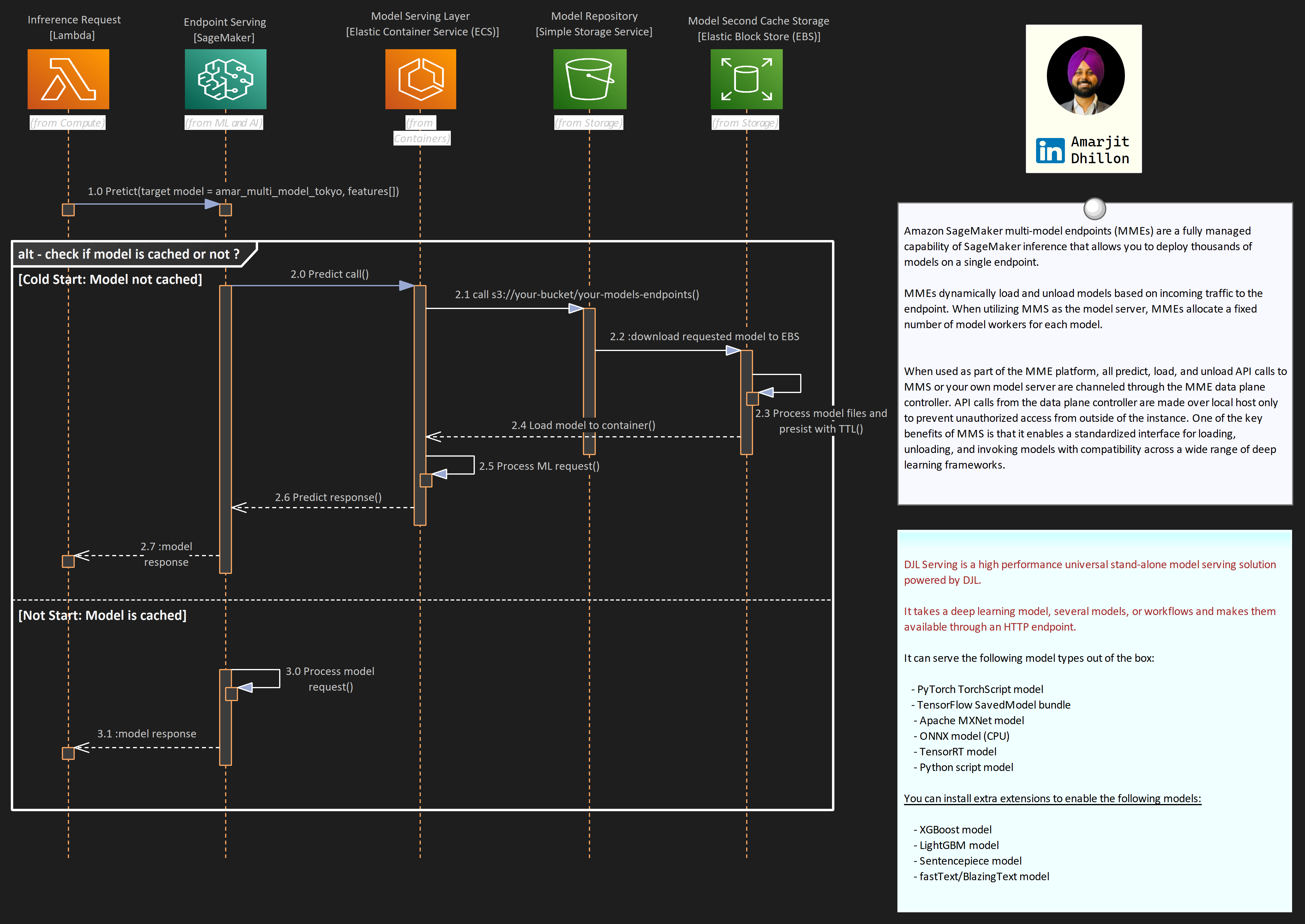
Amazon SageMaker multi-model endpoint (MME) enables you to cost-effectively deploy and host multiple models in a single endpoint and then horizontally scale the endpoint to achieve scale.
When to use MME?
Multi-model endpoints are suitable for use cases where you have models that are built in the same framework (XGBoost in this example), and where it is tolerable to have latency on less frequently used models.
As illustrated in the following figure, this is an effective technique to implement multi-tenancy of models within your machine learning (ML) infrastructure.
Use Cases
Shared tenancy: SageMaker multi-model endpoints are well suited for hosting a large number of models that you can serve through a shared serving container and you don’t need to access all the models at the same time. Depending on the size of the endpoint instance memory, a model may occasionally be unloaded from memory in favor of loading a new model to maximize efficient use of memory, therefore your application needs to be tolerant of occasional latency spikes on unloaded models.
Co host models: MME is also designed for co-hosting models that use the same ML framework because they use the shared container to load multiple models. Therefore, if you have a mix of ML frameworks in your model fleet (such as PyTorch and TensorFlow), SageMaker dedicated endpoints or multi-container hosting is a better choice.
Ability to handle cold starts: Finally, MME is suited for applications that can tolerate an occasional cold start latency penalty, because models are loaded on first invocation and infrequently used models can be offloaded from memory in favor of loading new models. Therefore, if you have a mix of frequently and infrequently accessed models, a multi-model endpoint can efficiently serve this traffic with fewer resources and higher cost savings.
Host both CPU and GPU: Multi-model endpoints support hosting both CPU and GPU backed models. By using GPU backed models, you can lower your model deployment costs through increased usage of the endpoint and its underlying accelerated compute instances.
MMS creates one or more Python worker processes per model based on the value of the default_workers_per_model configuration parameter. These Python workers handle each individual inference request by running any preprocessing, prediction, and post processing functions you provide.
Design for spikes
Each MMS process within an endpoint instance has a request queue that can be configured with the job_queue_size parameter (default is 100). This determines the number of requests MMS will queue when all worker processes are busy. Use this parameter to fine-tune the responsiveness of your endpoint instances after you’ve decided on the optimal number of workers per model.
Setup AutoScaling
Before you can use auto scaling, you must have already created an Amazon SageMaker model endpoint. You can have multiple model versions for the same endpoit. Each model is referred to as a production (model) variant.
Setup cooldown policy
A cooldown period is used to protect against over-scaling when your model is scaling in (reducing capacity) or scaling out (increasing capacity). It does this by slowing down subsequent scaling activities until the period expires. Specifically, it blocks the deletion of instances for scale-in requests, and limits the creation of instances for scale-out requests.
SageMaker multi-container endpoints enable customers to deploy multiple containers, that use different models or frameworks (XGBoost, Pytorch, TensorFlow), on a single SageMaker endpoint.
The containers can be run in a sequence as an inference pipeline, or each container can be accessed individually by using direct invocation to improve endpoint utilization and optimize costs.
Load testing is a technique that allows us to understand how our ML model hosted in an endpoint with a compute resource configuration responds to online traffic.
There are factors such as model size, ML framework, number of CPUs, amount of RAM, autoscaling policy, and traffic size that affect how your ML model performs in the cloud. Understandably, it's not easy to predict how many requests can come to an endpoint over time.
It is prudent to understand how your model and endpoint behave in this complex situation. Load testing creates artificial traffic and requests to your endpoint and stress tests how your model and endpoint respond in terms of model latency, instance CPU utilization, memory footprint, and so on.
EI attaches fractional GPUs to a SageMaker hosted endpoint. It increases the inference throughput and decreases the model latency for your deep learning models that can benefit from GPU acceleration
Neo is a capability of Amazon SageMaker that enables machine learning models to train once and run anywhere in the cloud and at the edge.
Why use NEO
Problem Statement
Generally, optimizing machine learning models for inference on multiple platforms is difficult because you need to hand-tune models for the specific hardware and software configuration of each platform. If you want to get optimal performance for a given workload, you need to know the hardware architecture, instruction set, memory access patterns, and input data shapes, among other factors. For traditional software development, tools such as compilers and profilers simplify the process. For machine learning, most tools are specific to the framework or to the hardware. This forces you into a manual trial-and-error process that is unreliable and unproductive.
Solution
Neo automatically optimizes Gluon, Keras, MXNet, PyTorch, TensorFlow, TensorFlow-Lite, and ONNX models for inference on Android, Linux, and Windows machines based on processors from Ambarella, ARM, Intel, Nvidia, NXP, Qualcomm, Texas Instruments, and Xilinx. Neo is tested with computer vision models available in the model zoos across the frameworks. SageMaker Neo supports compilation and deployment for two main platforms:
Inf1 provide high performance and low cost in thecloud with AWS Inferentia chips designed and built by AWS for ML inference purposes.You can compile supported ML models using SageMaker Neo and select Inf1 instances todeploy the compiled model in a SageMaker hosted endpoint.
LMI containers are a set of high-performance Docker Containers purpose built for large language model (LLM) inference.
With these containers, you can leverage high performance open-source inference libraries like vLLM, TensorRT-LLM, Transformers NeuronX to deploy LLMs on AWS SageMaker Endpoints. These containers bundle together a model server with open-source inference libraries to deliver an all-in-one LLM serving solution.