Quantization in LLMs 🌐
In the rapidly evolving world of artificial intelligence, large language models (LLMs) have become pivotal in various applications, from chatbots to recommendation systems. However, deploying these advanced models can be challenging due to high memory and computational requirements.
This is where quantization comes into play!
Do you know?
GPT-3.5 has around 175 billion parameters, while the current state-of-the-art GPT-4 has in excess of 1 trillion parameters.
In this blog, let’s explore how quantization can make LLMs more efficient, accessible, and ready for deployment on edge devices. 🌍
What is Quantization? 🤔
Quantization is a procedure that maps the range of high precision weight values, like FP32, into lower precision values such as FP16 or even INT8 (8-bit Integer) data types. By reducing the precision of the weights, we create a more compact version of the model without significantly losing accuracy.
Tldr
Quantization transforms high precision weights into lower precision formats to optimize resource usage without sacrificing performance.
Why Quantize? 🌟
Here are a few compelling reasons to consider quantization:
-
Reduced Memory Footprint 🗄️
Quantization dramatically lowers memory requirements, making it possible to deploy LLMs on lower-end machines and edge devices. This is particularly important as many edge devices only support integer data types for storage.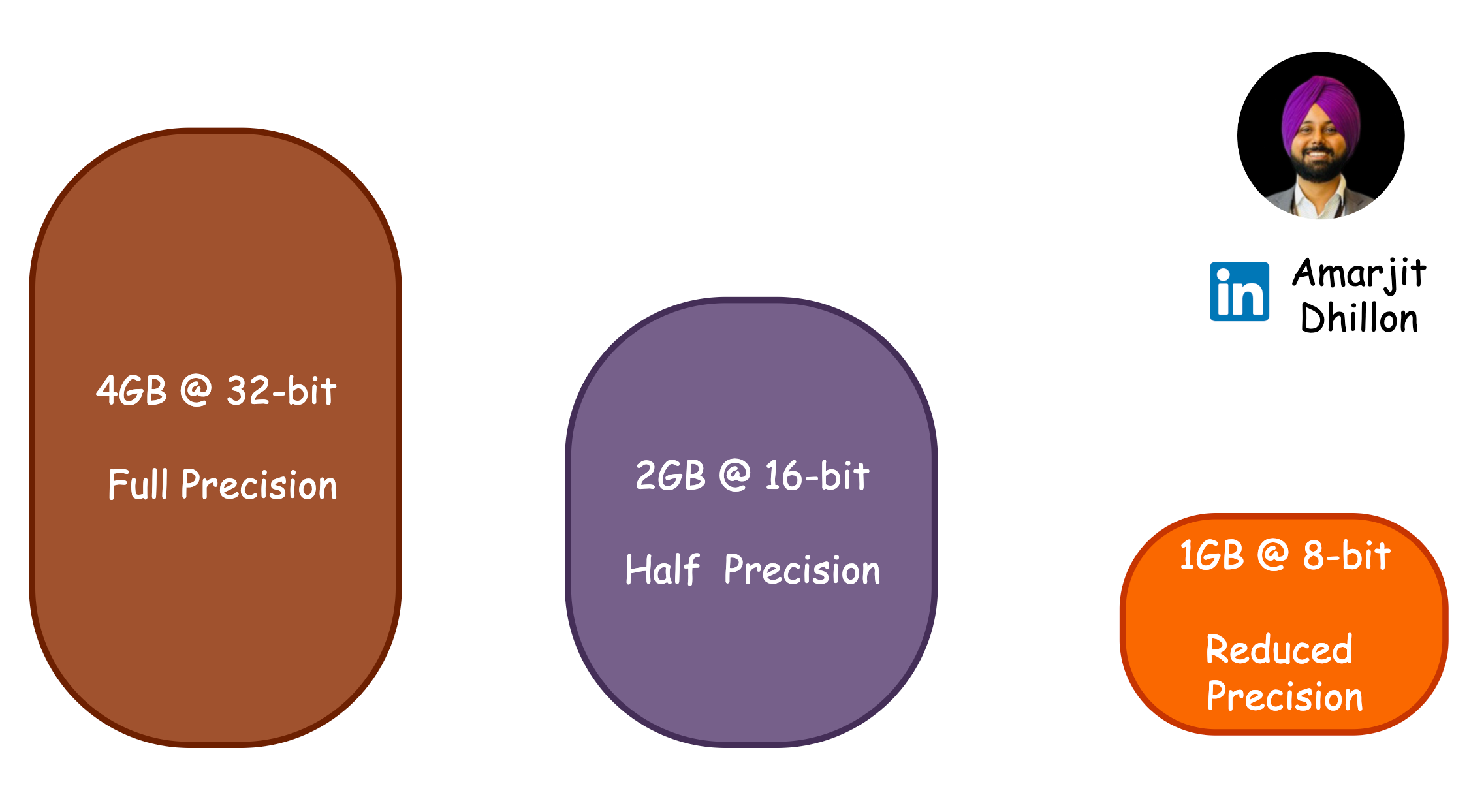
-
Faster Inference ⚡
Lower precision computations (such as integers) are inherently faster than higher precision (floats). By using quantized weights, mathematical operations during inference speed up significantly. Plus, modern CPUs and GPUs have specialized instructions designed for lower-precision computations, allowing you to take full advantage of hardware acceleration for even better performance! -
Reduced Energy Consumption 🔋
Many contemporary hardware accelerators are optimized for lower-precision operations, capable of performing more calculations per watt of energy when models are quantized. This is a win-win for efficiency and sustainability!
Linear Quantization 📏
In linear quantization, we essentially perform scaling within a specified range. Here, the minimum value (Rmin) is mapped to its quantized minimum (Qmin), and the maximum (Rmax) to its quantized counterpart (Qmax).
The zero in the actual range corresponds to a specific zero_point in the quantized range, allowing for efficient mapping and representation.
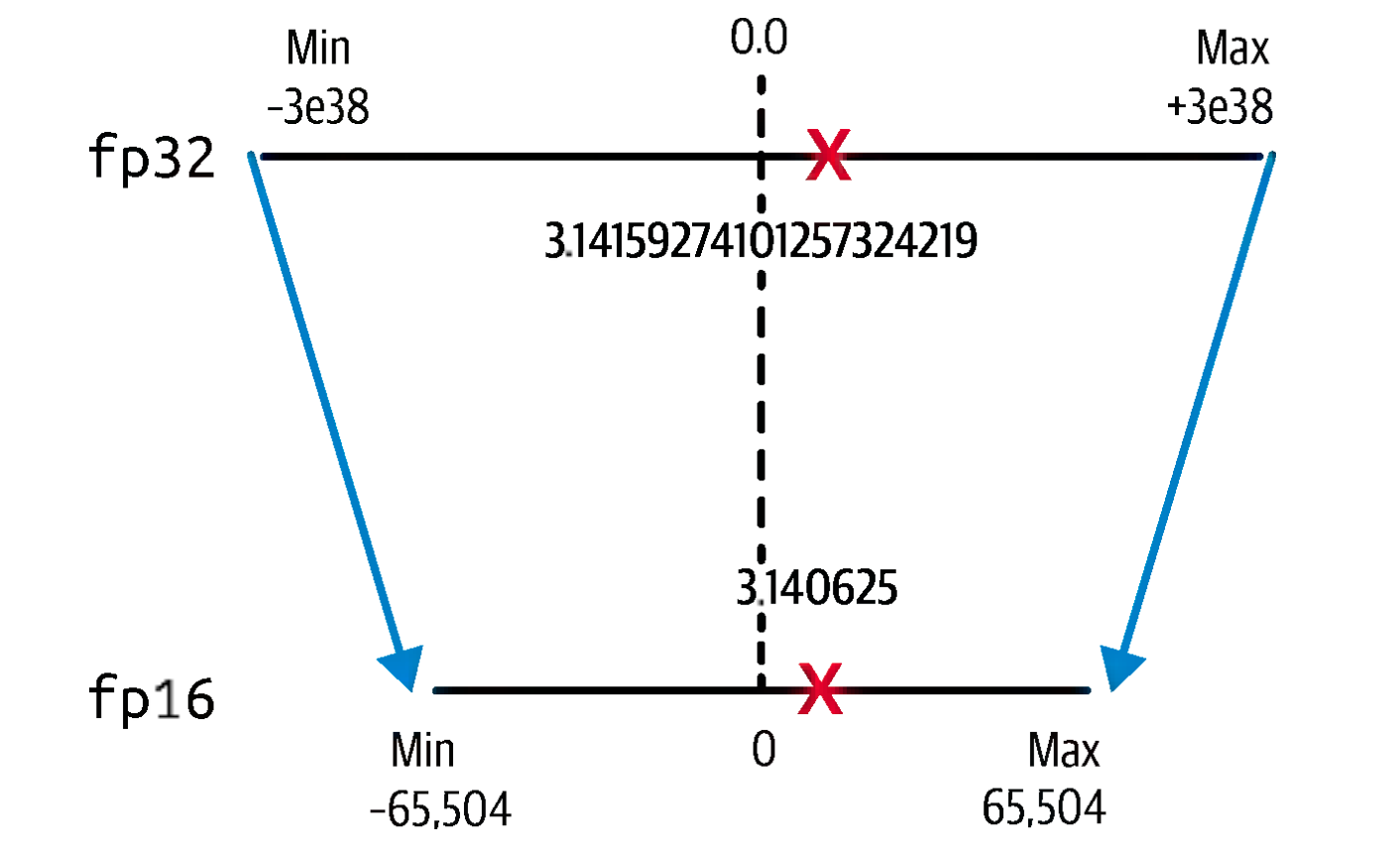
To achieve quantization, we need to find the optimum way to project our range of FP32 weight values, which we’ll label [min, max] to the INT4 space: one method of implementing this is called the affine quantization scheme, which is shown in the formula below:
$$ x_q = round(x/S + Z) $$
where:
-
x_q: the quantized INT4 value that corresponds to the FP32 value x
-
S: an FP32 scaling factor and is a positive float32
-
Zthe zero-point: the INT4 value that corresponds to 0 in the FP32 space
-
round: refers to the rounding of the resultant value to the closest integer
Types of Quantization
PTQ 🛠️
As the name suggests, Post Training Quantization (PTQ) occurs after the LLM training phase.
In this process, the model’s weights are converted from higher precision formats to lower precision types, applicable to both weights and activations. While this enhances speed, memory efficiency, and power usage, it comes with an accuracy trade-off.
Beware of Quantizaion Error
During quantization, rounding or truncation introduces quantization error, which can affect the model’s ability to capture fine details in weights.
QAT ⏰
Quantization-Aware Training (QAT) refers to methods of fine-tuning on data with quantization in mind. In contrast to PTQ techniques, QAT integrates the weight conversion process, i.e., calibration, range estimation, clipping, rounding, etc., during the training stage. This often results in superior model performance, but is more computationally demanding.
Tip
PTQ is easier to implement than QAT, as it requires less training data and is faster. However, it can also result in reduced model accuracy from lost precision in the value of the weights.
Final Thoughts 💭
Quantization is not just a technical detail; it's a game-changer for making LLMs accessible and cost-effective.
By leveraging this technique, developers can democratize AI technology and deploy sophisticated language models on everyday CPUs.
So, whether you’re building intelligent chatbots, personalized recommendation engines, or innovative code generators, don’t forget to incorporate quantization into your toolkit—it might just be your secret weapon! 🚀
Happy learning 🧑🏫