Feature Engineering using Databricks 🧱
The Databricks Runtime includes additional optimizations and proprietary features that build upon and extend Apache Spark, including Photon which is an optimized version of Apache Spark rewritten in C++ using vectorized query processing.
Spark Context
You don’t need to worry about configuring or initializing a Spark context or Spark session, as these are managed for you by Databricks.
Architecture 🏛️
Databricks operates out of a control plane and a data plane.
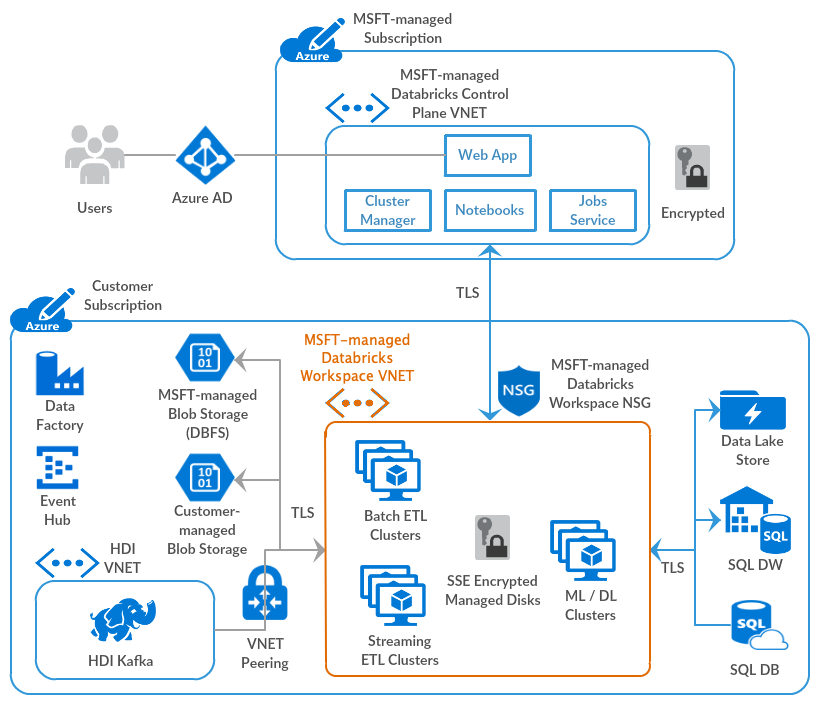
Control Plane 🧑✈️
The control plane includes the backend services that Azure Databricks manages in its own Azure account. Notebook commands and many other workspace configurations are stored in the control plane and encrypted at rest.
Data Plane 👷
Your Azure account manages the data plane, and is where your data resides. This is also where data is processed
- Job results reside in storage in your account.
Interactive notebook resultsare stored in a combination of the control plane (partial results for presentation in the UI) and your Azure storage. If you want interactive notebook results stored only in your cloud account storage, you can ask your Databricks representative to enable interactive notebook results in the customer account for your workspace.
Spark Concepts
DataFrame and RDD 🧮
Tldr
A DataFrame is a two-dimensional labeled data structure with columns of potentially different types. You can think of a DataFrame like a spreadsheet, a SQL table, or a dictionary of series objects. Apache Spark DataFrames provide a rich set of functions (select columns, filter, join, aggregate) that allow you to solve common data analysis problems efficiently.
Apache Spark DataFrames are an abstraction built on top of Resilient Distributed Datasets (RDDs).
Use of Lazy loading in Spark Dataframe instead of Pandas
One of the key differences between Pandas and Spark dataframes is eager versus lazy execution. In PySpark, operations are delayed until a result is actually requested in the pipeline. For example, you can specify operations for loading a data set from Amazon S3 and applying a number of transformations to the dataframe, but these operations won’t be applied immediately. Instead, a graph of transformations is recorded, and once the data are actually needed, for example when writing the results back to S3, then the transformations are applied as a single pipeline operation. This approach is used to avoid pulling the full dataframe into memory, and enables more effective processing across a cluster of machines.
Spark SQL 🌐
The term Spark SQL technically applies to all operations that use Spark DataFrames. Spark SQL replaced the Spark RDD API in Spark 2.x, introducing support for SQL queries and the DataFrame API for Python, Scala, R, and Java.
PySpark 🔥
PySpark is the Python API for Apache Spark, an open source, distributed computing framework and set of libraries for real-time, large-scale data processing.
Databricks Concepts 🧑🏫
Databricks File System (DBFS)
A filesystem abstraction layer over a blob store. It contains directories, which can contain files (data files, libraries, and images), and other directories. DBFS is automatically populated with some datasets that you can use to learn Azure Databricks.
DBFS is an abstraction on top of scalable object storage that maps Unix-like filesystem calls to native cloud storage API calls.
Mount blob to DBFS 📍
Mounting object storage to DBFS allows you to access objects in object storage as if they were on the local file system. Mounts store Hadoop configurations necessary for accessing storage, so you do not need to specify these settings in code or during cluster configuration.
DBFS root 🌴
The DBFS root is the default storage location for a Databricks workspace, provisioned as part of workspace creation in the cloud account containing the Databricks workspace
It is important to differentiate that DBFS is a file system used for interacting with data in cloud object storage, and the DBFS root is a cloud object storage location.
Auto Loader 🛺
Tldr
Auto Loader incrementally and efficiently processes new data files as they arrive in cloud storage without any additional setup.
Auto Loader incrementally and efficiently processes new data files as they arrive in cloud storage. Auto Loader can load data files from
- AWS S3
(s3://) - Azure Data Lake Storage Gen2 (ADLS Gen2,
abfss://) - Google Cloud Storage (GCS,
gs://) - Azure Blob Storage (
wasbs://) - ADLS Gen1 (
adl://) - Databricks File System (DBFS,
dbfs:/)
Auto Loader can ingest JSON, CSV, PARQUET, AVRO, ORC, TEXT, and BINARYFILE file formats.
How does Auto Loader track ingestion progress?
As files are discovered, their metadata is persisted in a scalable key-value store (RocksDB) in the checkpoint location of your Auto Loader pipeline. This key-value store ensures that data is processed exactly once.
Delta Lake ⛴️
Delta Lake is open source software that extends Parquet data files with a file-based transaction log for ACID transactions and scalable metadata handling.
Delta Lake is fully compatible with Apache Spark APIs, and was developed for tight integration with Structured Streaming, allowing you to easily use a single copy of data for both batch and streaming operations and providing incremental processing at scale.
Who created delta lake format?
Delta Lake is the default storage format for all operations on Databricks. Unless otherwise specified, all tables on Databricks are Delta tables. Databricks originally developed the Delta Lake protocol and continues to actively contribute to the open source project.
Connecting to blob/ ADLS 🔗
We can use the Azure Blob Filesystem driver (ABFS) to connect to Azure Blob Storage and Azure Data Lake Storage (ADLS) Gen2 from Databricks
The connection can be scoped to either 1. Databricks cluster 2. Databricks Notebook
ABFS vs WASB
The legacy Windows Azure Storage Blobdriver (WASB) has been deprecated. ABFS has numerous benefits over WASB.
Credentials walkthrough
When you enable Azure Data Lake Storage credential passthrough for your cluster, commands that you run on that cluster can read and write data in Azure Data Lake Storage without requiring you to configure service principal credentials for access to storage. Azure Data Lake Storage credential passthrough is supported with Azure Data Lake Storage Gen1 and Gen2 only. Azure Blob storage does not support credential passthrough.
Delta table Δ
A Delta table stores data as a directory of files on cloud object storage and registers table metadata to the metastore within a catalog and schema.
Hive metastore 🐝
The component that stores all the structure information of the various tables and partitions in the data warehouse including column and column type information, the serializers and deserializers necessary to read and write data, and the corresponding files where the data is stored.
Delta live tables 🖖
Instead of defining your data pipelines using a series of separate Apache Spark tasks, Delta Live Tables manages how your data is transformed based on a target schema you define for each processing step.
You can also enforce data quality with Delta Live Tables expectations. Expectations allow you to define expected data quality and specify how to handle records that fail those expectations.
Authentication and authorization 🪪
User 🧑🦰
A unique individual who has access to the system. User identities are represented by email addresses.
Service principal ☃️
A service identity for use with jobs, automated tools, and systems such as scripts, apps, and CI/CD platforms. Service principals are represented by an application ID.
Group 🏠
Groups simplify identity management, making it easier to assign access to workspaces, data, and other securable objects. All Databricks identities can be assigned as members of groups.
ACL ⛔️
A list of permissions attached to the workspace, cluster, job, table, or experiment. An ACL specifies which users or system processes are granted access to the objects, as well as what operations are allowed on the assets
PAT 💳
An opaque string is used to authenticate to the REST API and by tools in the Databricks integrations to connect to SQL warehouses.
DS & Engineering Space ⚙️
Workspace 🪐
A workspace is an environment for accessing all of your Azure Databricks assets. A workspace organizes objects (notebooks, libraries, dashboards, and experiments) into folders and provides access to data objects and computational resources.
Notebook 🔖
A web-based interface to documents that contain runnable commands, visualizations, and narrative text.
Repo 📦
A folder whose contents are co-versioned together by syncing them to a remote Git repository.
Databricks Workflow ⏳
Azure Databricks Workflows orchestrates data processing, machine learning, and analytics pipelines in the Azure Databricks Lakehouse Platform.
Workflows has fully managed orchestration services integrated with the Azure Databricks platform, including Azure Databricks Jobs to run non-interactive code in your Azure Databricks workspace and Delta Live Tables to build reliable and maintainable ETL pipelines.
SCC/NPIP 🎭
Secure cluster connectivity is also known as No Public IP (NPIP).
Tldr
With secure cluster connectivity enabled, customer virtual networks have no open ports and Databricks Runtime cluster nodes in the classic compute plane have no public IP addresses.
-
At a network level, each cluster initiates a connection to the control plane secure cluster connectivity relay during cluster creation. The cluster establishes this connection using port 443 (HTTPS) and uses a different IP address than is used for the Web application and REST API.
-
When the control plane logically starts new Databricks Runtime jobs or performs other cluster administration tasks, these requests are sent to the cluster through this tunnel.
-
The compute plane (the VNet) has no open ports, and Databricks Runtime cluster nodes have no public IP addresses.

Delta Lake 🐟
- Delta Lake is the optimized storage layer that provides the foundation for storing data and tables in the Databricks lakehouse.
- Delta Lake is
open source softwarethat extendsParquet data fileswith a file-based transaction log for ACID transactions and scalable metadata handling. - Delta Lake is fully compatible with Apache Spark APIs, and was developed for tight integration with Structured Streaming, allowing you to easily use a single copy of data for both batch and streaming operations and providing incremental processing at scale.
The default format
Delta Lake is the default storage format for all operations on Azure Databricks. Unless otherwise specified, all tables on Azure Databricks are Delta tables. Databricks originally developed the Delta Lake protocol and continues to actively contribute to the open source project.
Delta Table 🧩
A Delta table stores data as a directory of files on cloud object storage and registers table metadata to the metastore within a catalog and schema.
DBFS 🗄️
The Databricks File System (DBFS) is a ==distributed file system= mounted into an Azure Databricks workspace and available on Azure Databricks clusters. DBFS is an abstraction on top of scalable object storage that maps Unix-like filesystem calls to native cloud storage API calls.
So what is DBFS root?
The DBFS root is the default storage location for an Azure Databricks workspace, provisioned as part of workspace creation in the cloud account containing the Azure Databricks workspace. it is important to differentiate that DBFS is a file system used for interacting with data in cloud object storage, and the DBFS root is a cloud object storage location
Unity Catalog Metastore 🧭
Unity Catalog provides centralized access control, auditing, lineage, and data discovery capabilities. You create Unity Catalog metastores at the Azure Databricks account level, and a single metastore can be used across multiple workspaces.
Hive Metastore (Legacy) 📦
Each Azure Databricks workspace includes a built-in Hive metastore as a managed service. An instance of the metastore deploys to each cluster and securely accesses metadata from a central repository for each customer workspace.
The Hive metastore provides a less centralized data governance model than Unity Catalog. By default, a cluster allows all users to access all data managed by the workspace’s built-in Hive metastore unless table access control is enabled for that cluster.
Catalog 📕
- A
catalogis the highest abstraction (or coarsest grain) in the Databricks lakehouse relational model. - Every database will be associated with a catalog.
- Catalogs exist as objects within a metastore.
Before the introduction of Unity Catalog, Azure Databricks used a two-tier namespace. Catalogs are the third tier in the Unity Catalog namespacing model:
catalog_name.database_name.table_name
SCIM 🔐
SCIM (System for Cross-domain Identity Management) lets you use an identity provider (IdP) to create users in Azure Databricks, give them the proper level of access, and remove access (deprovision them) when they leave your organization or no longer need access to Azure Databricks.
You can either configure one SCIM provisioning connector from Microsoft Entra ID (formerly Azure Active Directory) to your Azure Databricks account, using account-level SCIM provisioning, or configure separate SCIM provisioning connectors to each workspace, using workspace-level SCIM provisioning.
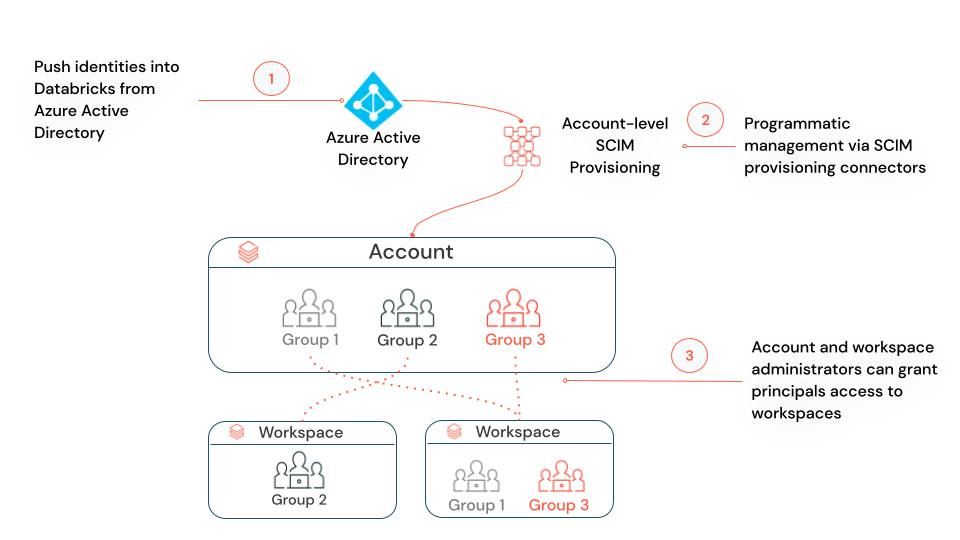
Account-level SCIM provisioning: Azure Databricks recommends that you use account-level SCIM provisioning to create, update, and delete all users from the account. You manage the assignment of users and groups to workspaces within Databricks. Your workspaces must be enabled for identity federation to manage users’ workspace assignments.
Workspace-level SCIM provisioning (public preview): If none of your workspaces is enabled for identity federation, or if you have a mix of workspaces, some enabled for identity federation and others not, you must manage account-level and workspace-level SCIM provisioning in parallel. In a mixed scenario, you don’t need workspace-level SCIM provisioning for any workspaces that are enabled for identity federation.
Unity Catalog ⚛️
Unity Catalog provides centralized access control, auditing, lineage, and data discovery capabilities across Azure Databricks workspaces.
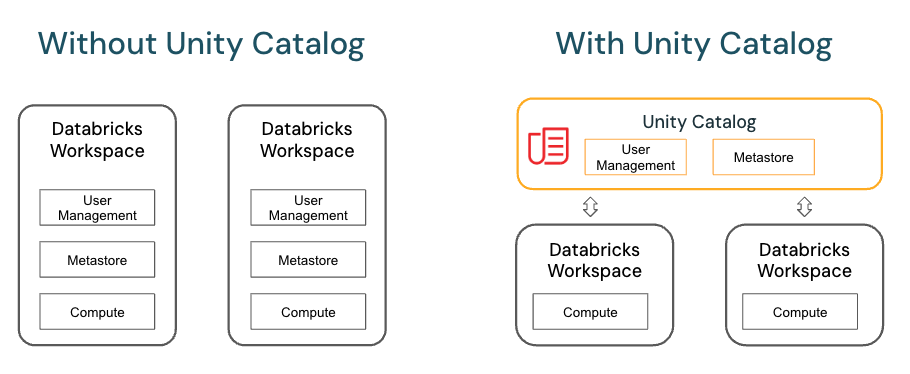
In Unity Catalog, the hierarchy of primary data objects flows from metastore to table or volume:
- Metastore: The top-level container for metadata. Each metastore exposes a three-level namespace (catalog.schema.table) that organizes your data.
- Catalog: The first layer of the object hierarchy, used to organize your data assets.
- Schema: Also known as databases, schemas are the second layer of the object hierarchy and contain tables and views.
- Tables, views, and volumes: At the lowest level in the object hierarchy are tables, views, and volumes. Volumes provide governance for non-tabular data.
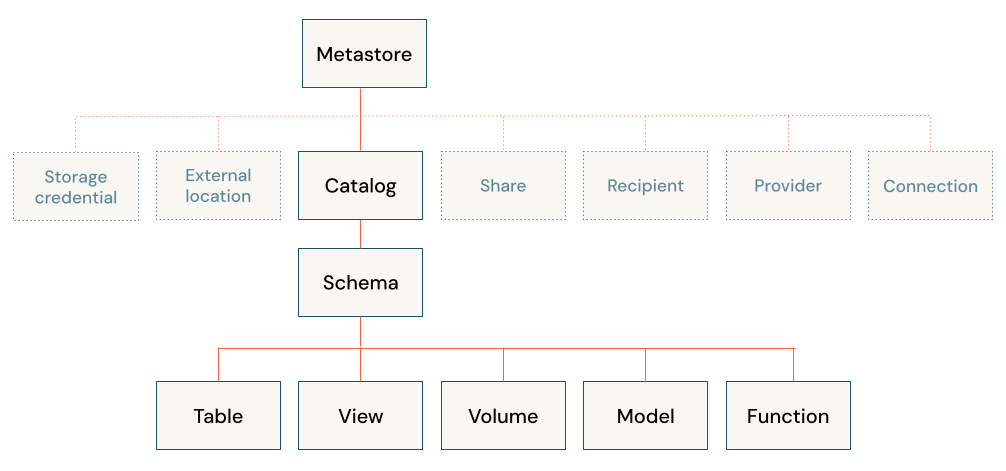
3 level namespace
You reference all data in Unity Catalog using a three-level namespace: catalog.schema.asset, where asset can be a table, view, or volume.
Metastores 🏬
- A metastore is the top-level container of objects in
Unity Catalog. - It registers metadata about data and AI assets and the permissions that govern access to them.
- Azure Databricks account admins should create one metastore for each region in which they operate and assign them to Azure Databricks workspaces in the same region.
- For a workspace to use Unity Catalog, it must have a Unity Catalog metastore attached.
External tables ‼️
External tables are tables whose data lifecycle and file layout are not managed by Unity Catalog. Use external tables to register large amounts of existing data in Unity Catalog, or if you require direct access to the data using tools outside of Azure Databricks clusters or Databricks SQL warehouses.
Dropping an External Table
When you drop an external table, Unity Catalog does not delete the underlying data. You can manage privileges on external tables and use them in queries in the same way as managed tables.
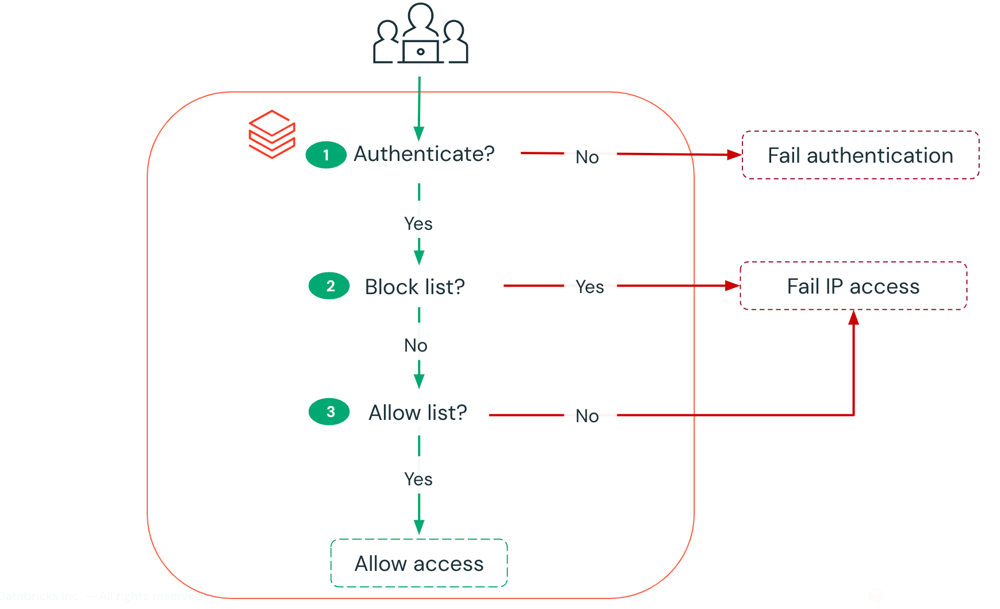
IP access lists ⚠️
IP access lists enable you to restrict access to your Azure Databricks account and workspaces based on a user’s IP address. For example, you can configure IP access lists to allow users to connect only through existing corporate networks with a secure perimeter. If the internal VPN network is authorized, users who are remote or traveling can use the VPN to connect to the corporate network. If a user attempts to connect to Azure Databricks from an insecure network, like from a coffee shop, access is blocked.
UDR/ Custom route 🚗
If your Azure Databricks workspace is deployed to your own virtual network (VNet), you can use custom routes, also known as user-defined routes (UDR), to ensure that network traffic is routed correctly for your workspace. For example, if you connect the virtual network to your on-premises network, traffic may be routed through the on-premises network and unable to reach the Azure Databricks control plane. User-defined routes can solve that problem
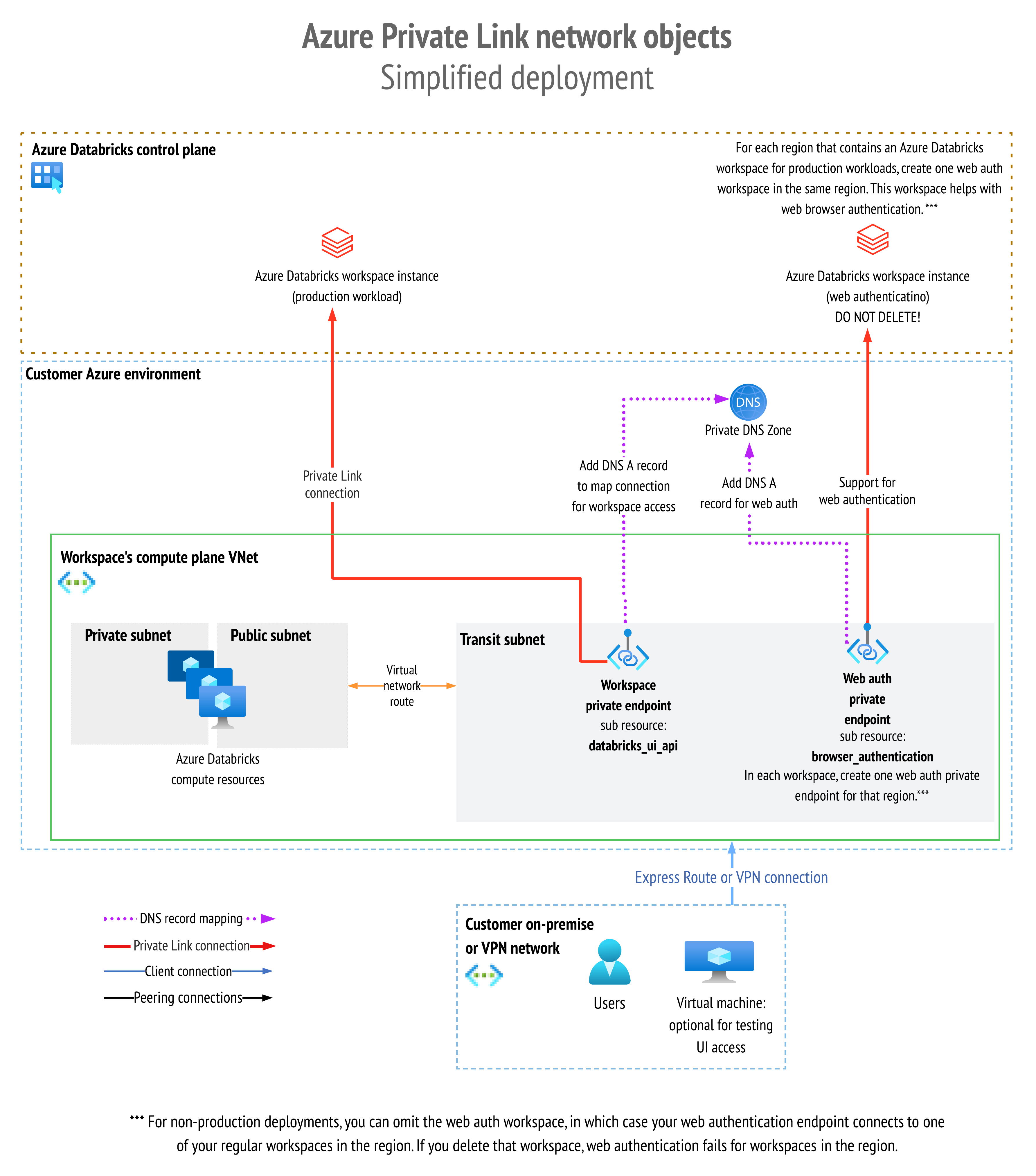
Private Link 🌐
Private Link provides private connectivity from Azure VNets and on-premises networks to Azure services without exposing the traffic to the public network. Azure Databricks supports the following Private Link connection types:
-
Front-end Private Link (also known as user to workspace): A front-end Private Link connection allows users to connect to the Azure Databricks web application, REST API, and Databricks Connect API over a VNet interface endpoint. The front-end connection is also used by JDBC/ODBC and PowerBI integrations. The network traffic for a front-end Private Link connection between a transit VNet and the workspace control plane traverses over the Microsoft backbone network.
-
Back-end Private Link (also known as compute plane to control plane): Databricks Runtime clusters in a customer-managed VNet (the compute plane) connect to an Azure Databricks workspace’s core services (the control plane) in the Azure Databricks cloud account. This enables private connectivity from the clusters to the secure cluster connectivity relay endpoint and REST API endpoint.
-
Browser authentication private endpoint: To support private front-end connections to the Azure Databricks web application for clients that have no public internet connectivity, you must add a browser authentication private endpoint to support single sign-on (SSO) login callbacks to the Azure Databricks web application from Microsoft Entra ID (formerly Azure Active Directory). If you allow connections from your network to the public internet, adding a browser authentication private endpoint is recommended but not required. A browser authentication private endpoint is a private connection with sub-resource type browser_authentication.
On-Prem connectivity 🏢
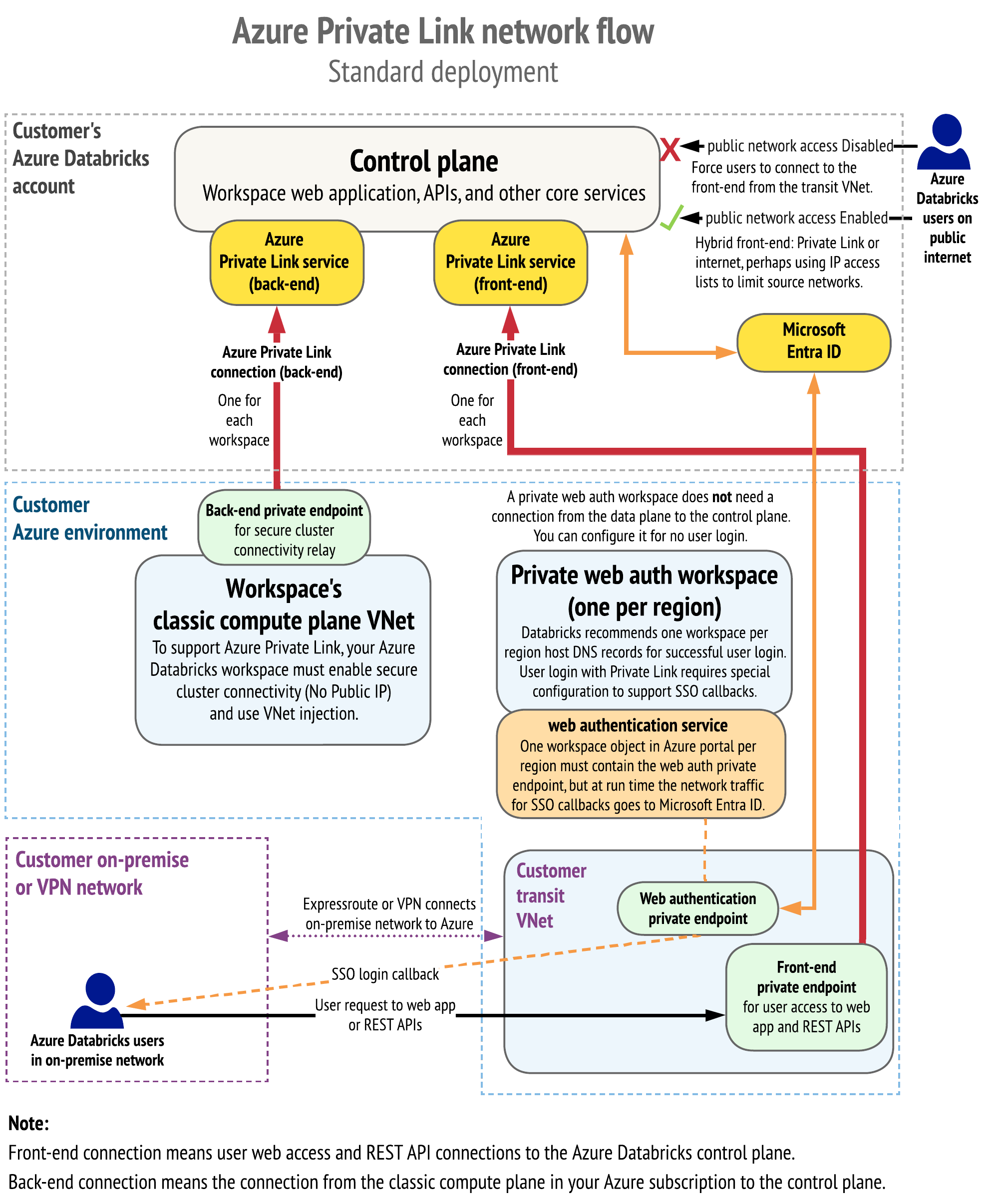
Traffic is routed via a transit virtual network (VNet) to the on-premises network, using the following hub-and-spoke topology.
Private Link 🔗
The following diagram shows the network flow in a typical implementation of the Private Link simplified deployment:
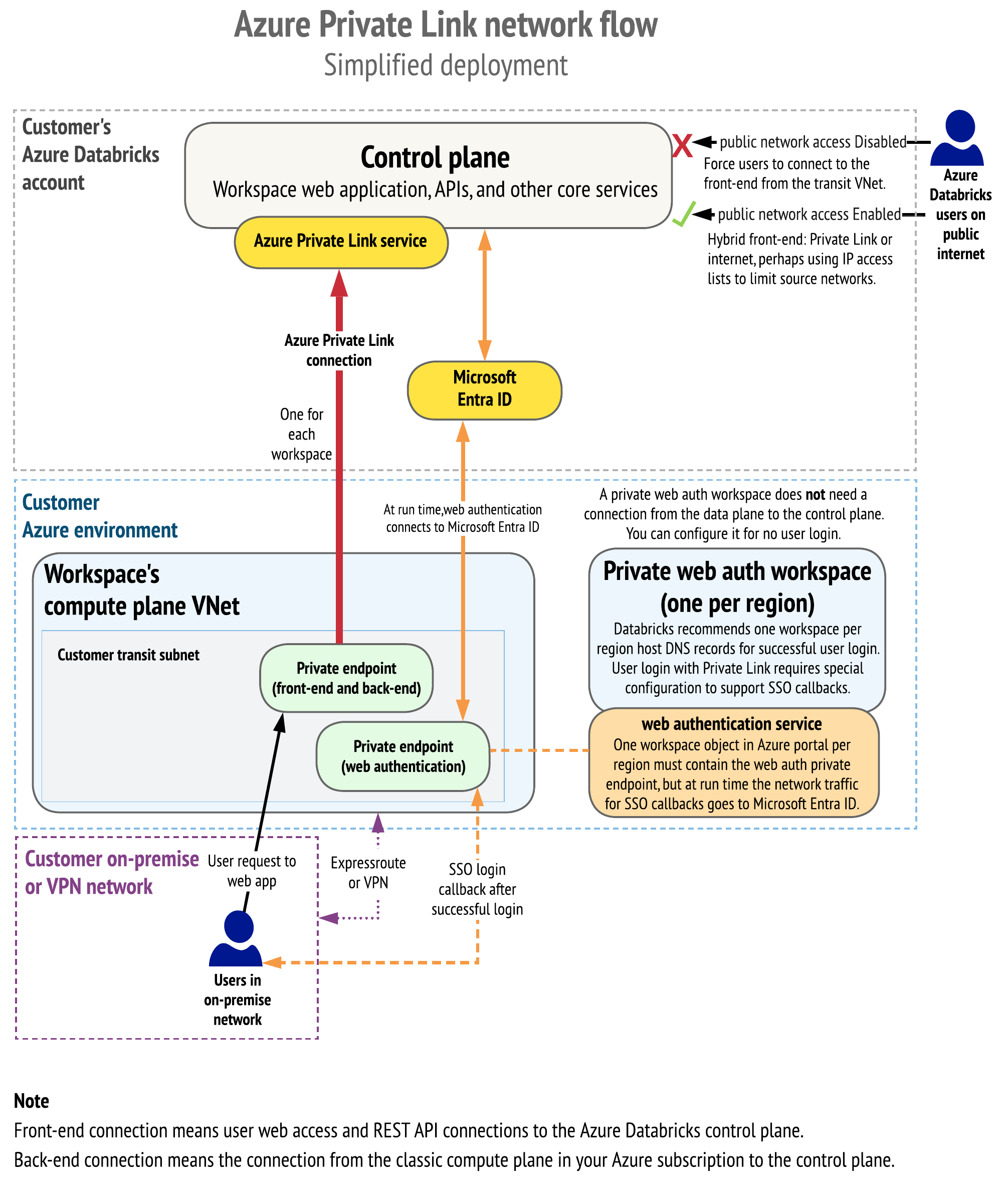
The following diagram shows the network object architecture:
Workflows ⏳
Azure Databricks Workflows orchestrates data processing, machine learning, and analytics pipelines on the Databricks Data Intelligence Platform. Workflows has fully managed orchestration services integrated with the Databricks platform, including Azure Databricks Jobs to run non-interactive code in your Azure Databricks workspace and Delta Live Tables to build reliable and maintainable ETL pipelines.
Jobs 👨🎨
-
An Azure Databricks job is a way to run your data processing and analysis applications in an Azure Databricks workspace.
-
Your job can consist of a single task or can be a large, multi-task workflow with complex dependencies.
-
Azure Databricks manages the task orchestration, cluster management, monitoring, and error reporting for all of your jobs.
-
You can run your jobs immediately, periodically through an easy-to-use scheduling system, whenever new files arrive in an external location, or continuously to ensure an instance of the job is always running.
-
You can also run jobs interactively in the notebook UI.